Linux MySQL分库分表之Mycat
介绍
背景
- 当表的个数达到了几百千万张表时,众多的业务模块都访问这个数据库,压力会比较大,考虑对其进行分库
- 当表的数据达到几千万级别,在做很多操作都比较吃力,考虑对其进行分库或分表
数据切分(sharding)方案
数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式:
- 垂直切分:按照业务模块进行切分,将不同模块的表切分到不同的数据库中
- 水平切分,将一张大表按照一定的切分规则,按照行切分成不同的表或者切分到不同的库中
如何理解垂直切分?
垂直分库:主要解决的问题是单个数据库中[数据表]过多问题。
垂直分表:主要解决的问题是单个表中[过多问题(将一张大表,拆分不同的关联表)。
如何理解水平切分?
水平切分主要解决的问题就是对于[单表数据量过大]的问题(1000W以上数据性能会有所下降)
切分原则
- 能不切尽量不要切分
- 如果要切分一定要选择合适的切分规则,提前规划好
- 数据切分尽量通过冗余或表分组(Table Group)来降低跨库Join的可能
- 由于数据库中间件对数据Join实现的优劣难以把握,而且实现高性能难度极大,业务读取尽量少使用多表Join
分库分表之后带来问题?
- 跨库Join:订单表需要关联会员信息(订单表和会员表拆分为两个库的表)
- 应用层由一个查询拆分为多个
- 全局表,每个库都存储相同的数据,比如字典表、地址表
- 字段冗余
- Mycat技术可以实现跨库Join,只能实现2张表跨库Join
- 分布式事务(Mycat没有很好实现分布式事务)
- 强一致性(互联网项目不推荐,性能不好)
- 最终一致性(异步方式去实现,需要通过日志信息)
- 主键问题(保证ID的连续性和唯一性)
- UUID(性能不好)
- redis incr命令
- zookeeper
- 雪花算法
- 跨库进行排序问题
- 在应用层进行排序
Mycat应用
官网链接
Mycat核心概念
- Schema:由它制定逻辑数据库(相当于MySQL的database数据库)
- Table:逻辑表(相当于MySQL的table表)
- DataNode:真正存储数据的物理节点
- DataHost:存储节点所在的数据库主机(指定MySQL数据库的连接信息)
- User:MyCat的用户(类似于MySQL的用户,支持多用户)
MyCat主要解决的问题
- 海量数据存储
- 查询优化
Mycat对数据库的支持

Mycat安装
安装要求
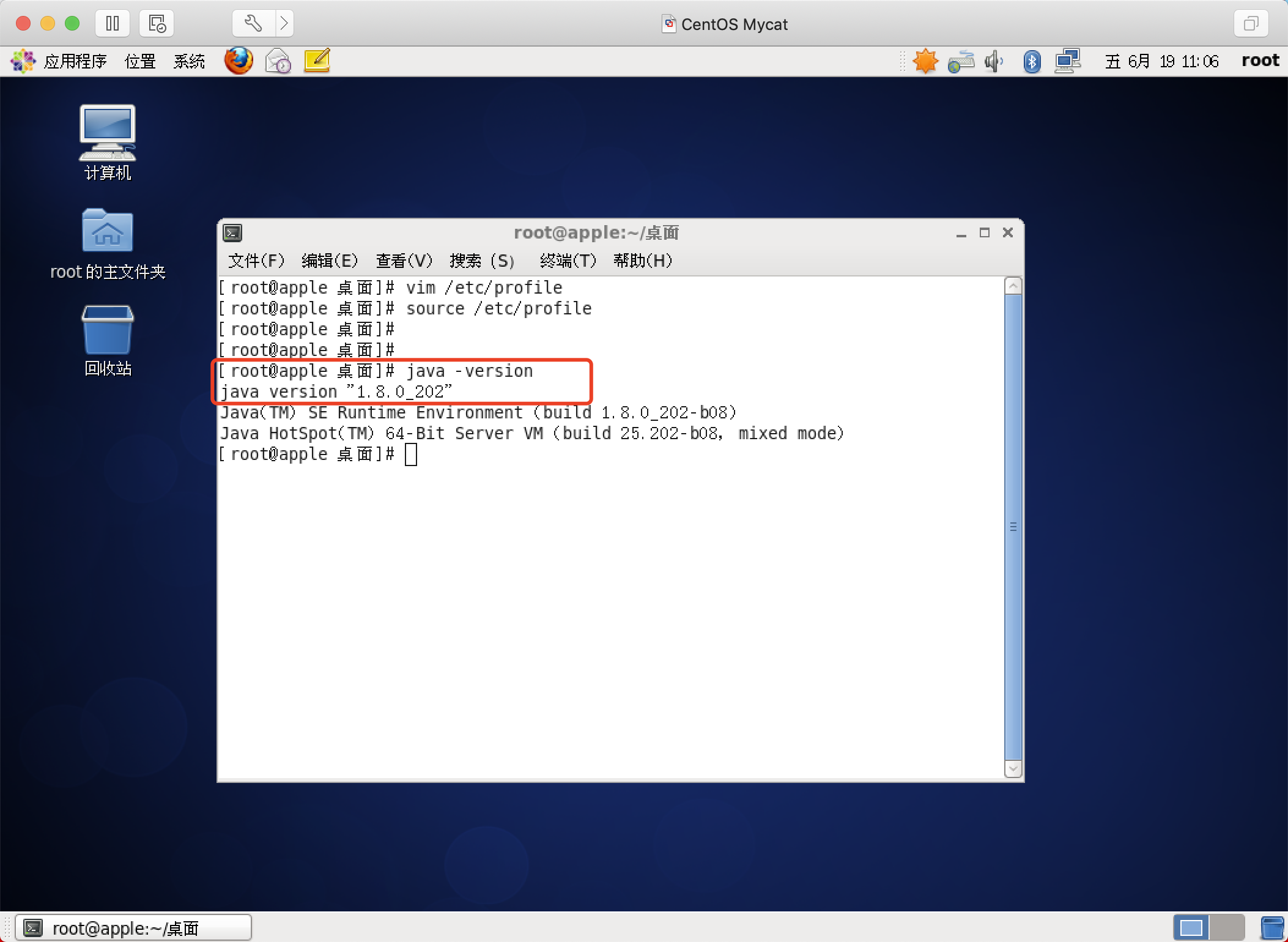
jdk:要求jdk必须是1.7及以上版本 (我使用的是jdk 1.8)
Mysql:推荐mysql是5.5以上版本(我使用的是mysql 5.7)
安装jdk
具体教程:点我直达
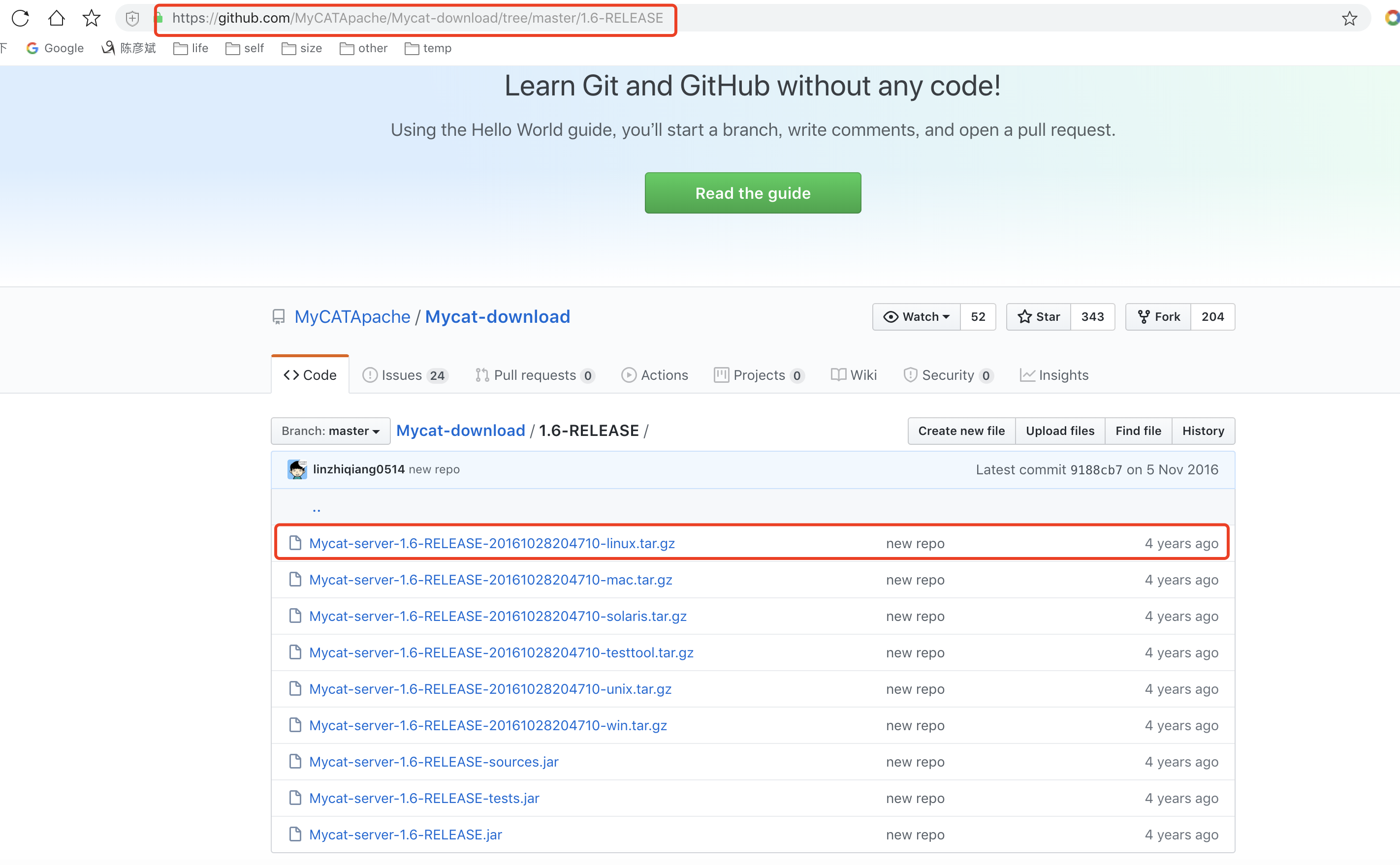
Mcat下载
下载链接:点我直达
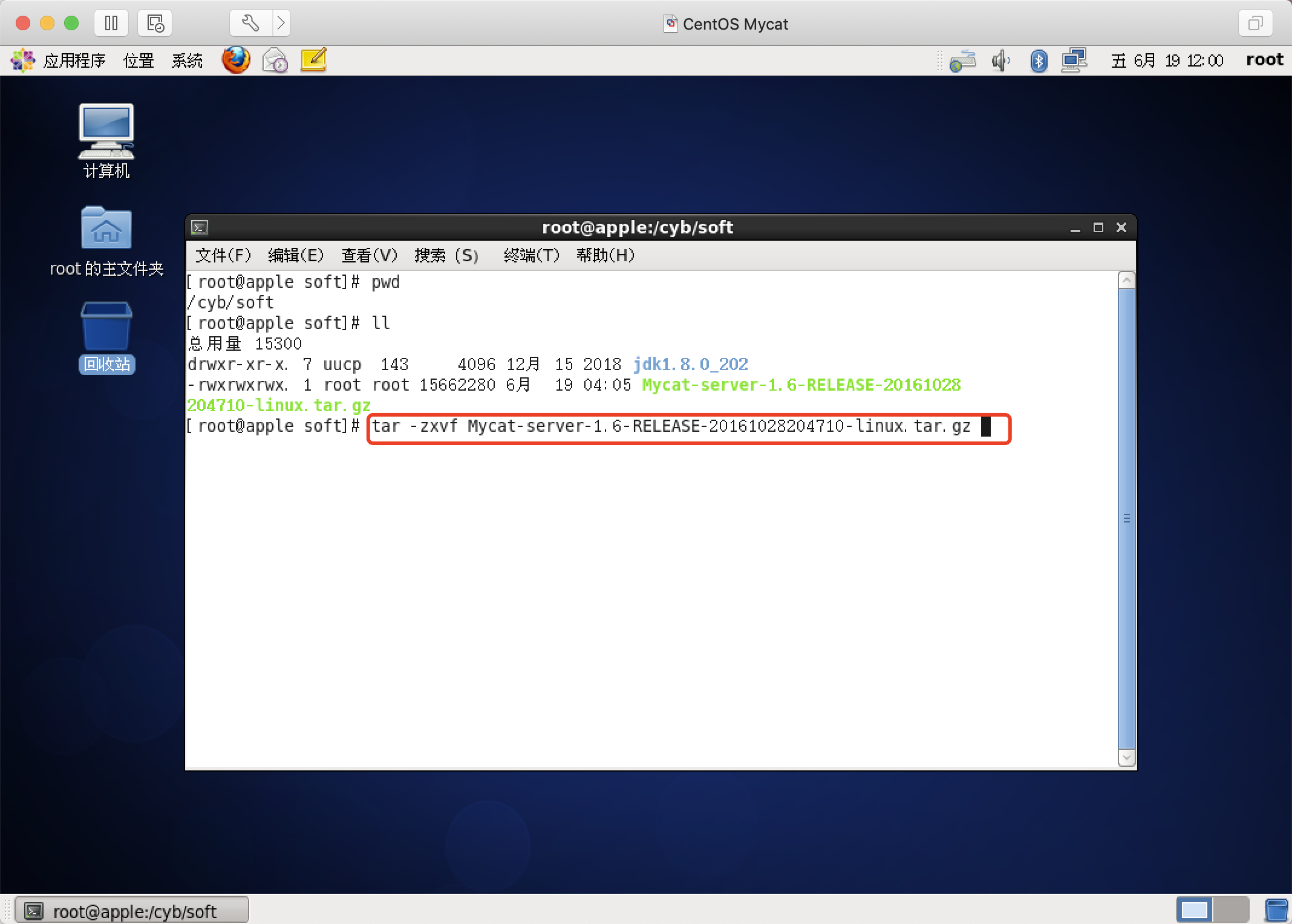
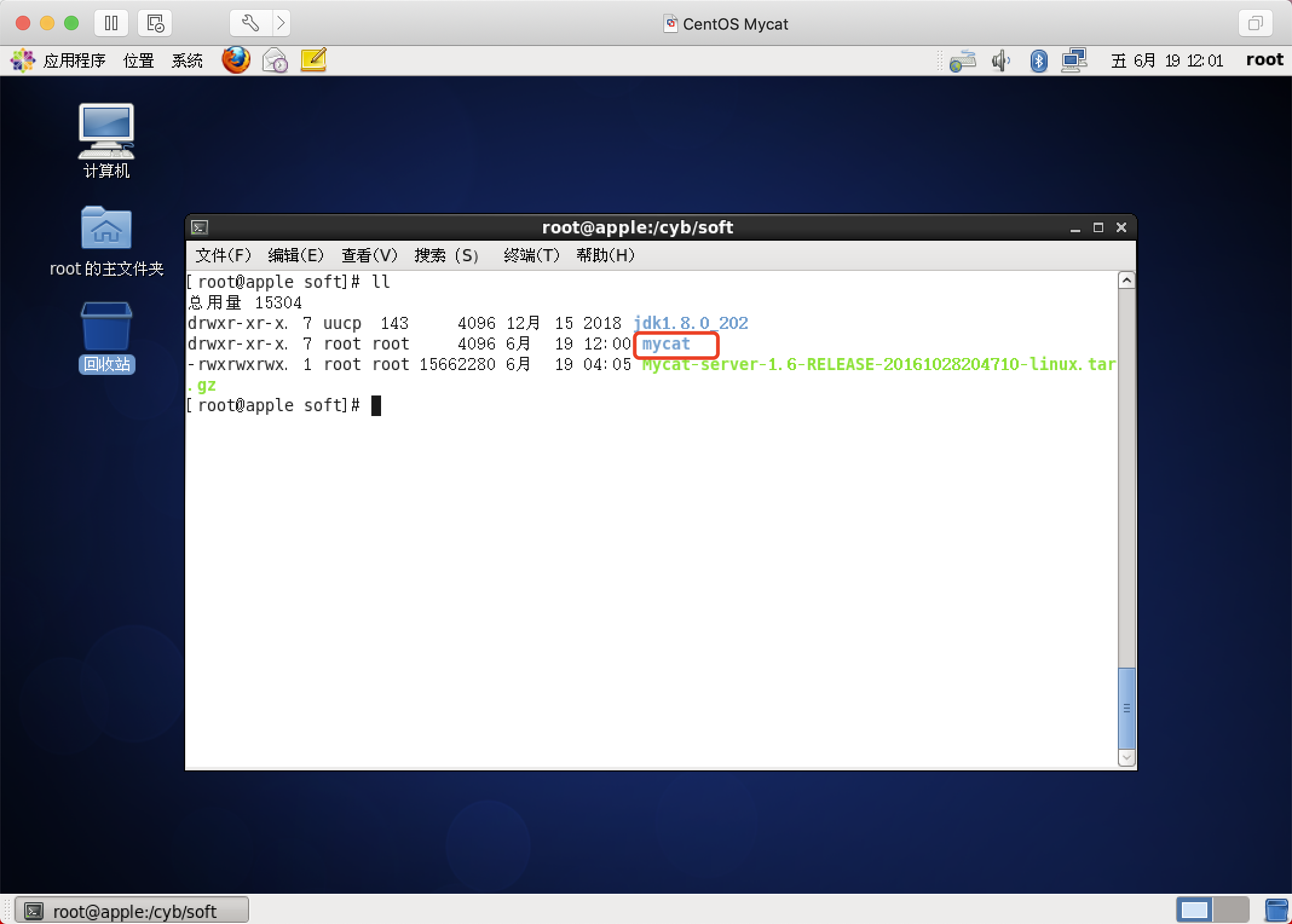
解压
修改配置文件
路径:/cyb/soft/mycat/conf
server.xml
用途:用于配置用户信息

<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 --> <property name="sequnceHandlerType">2</property>
<!-- <property name="useCompression">1</property>--> <!--1为开启mysql压缩协议-->
<!-- <property name="fakeMySQLVersion">5.6.20</property>--> <!--设置模拟的MySQL版本号-->
<!-- <property name="processorBufferChunk">40960</property> -->
<!--
<property name="processors">1</property>
<property name="processorExecutor">32</property>
-->
<!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena-->
<property name="processorBufferPoolType">0</property>
<!--默认是65535 64K 用于sql解析时最大文本长度 -->
<!--<property name="maxStringLiteralLength">65535</property>-->
<!--<property name="sequnceHandlerType">0</property>-->
<!--<property name="backSocketNoDelay">1</property>-->
<!--<property name="frontSocketNoDelay">1</property>-->
<!--<property name="processorExecutor">16</property>-->
<!--
<property name="serverPort">8066</property> <property name="managerPort">9066</property>
<property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property>
<property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> -->
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property> <!--
off heap for merge/order/group/limit 1开启 0关闭
-->
<property name="useOffHeapForMerge">1</property> <!--
单位为m
-->
<property name="memoryPageSize">1m</property> <!--
单位为k
-->
<property name="spillsFileBufferSize">1k</property> <property name="useStreamOutput">0</property> <!--
单位为m
-->
<property name="systemReserveMemorySize">384m</property> <!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">true</property> </system> <!-- 全局SQL防火墙设置 -->
<!--
<firewall>
<whitehost>
<host host="127.0.0.1" user="mycat"/>
<host host="127.0.0.2" user="mycat"/>
</whitehost>
<blacklist check="false">
</blacklist>
</firewall>
--> <user name="root">
<property name="password">root</property>
<property name="schemas">TESTDB</property> <!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user> <user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
</user> </mycat:server>
schema.xml
用途:管理逻辑表
为了演示方便,删掉一些不必要的标签,标签详细用法:点我直达
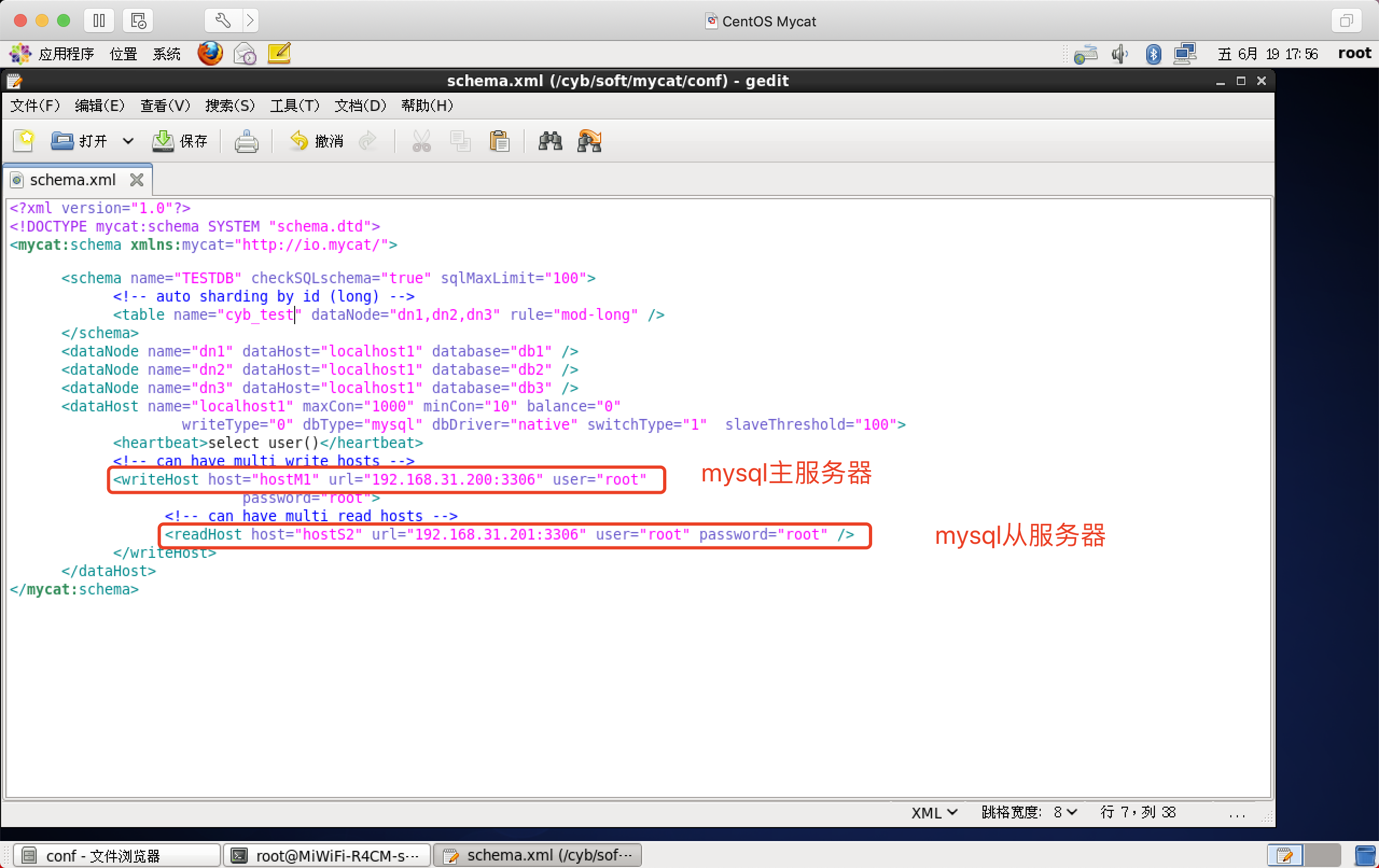
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100">
<!-- auto sharding by id (long) -->
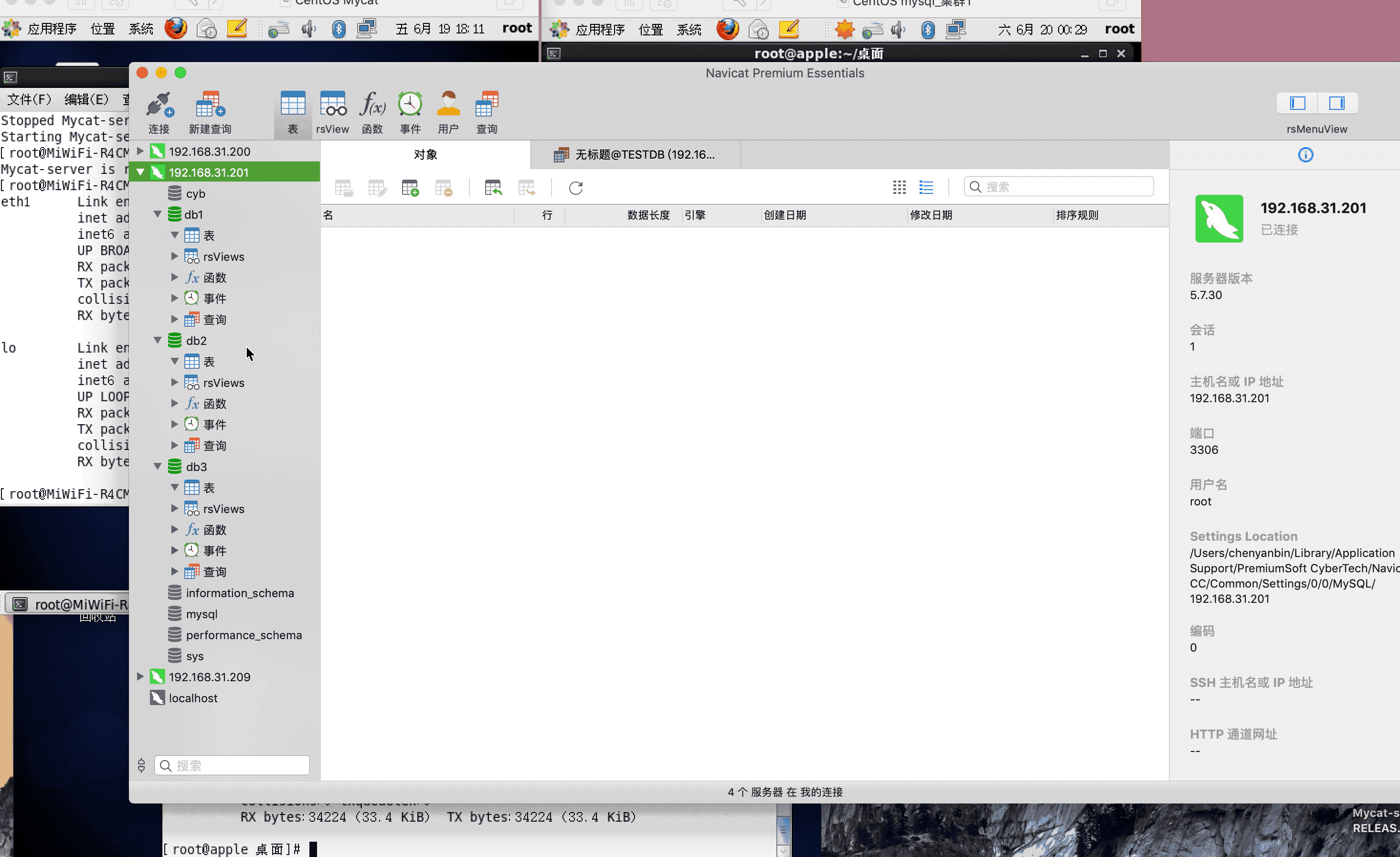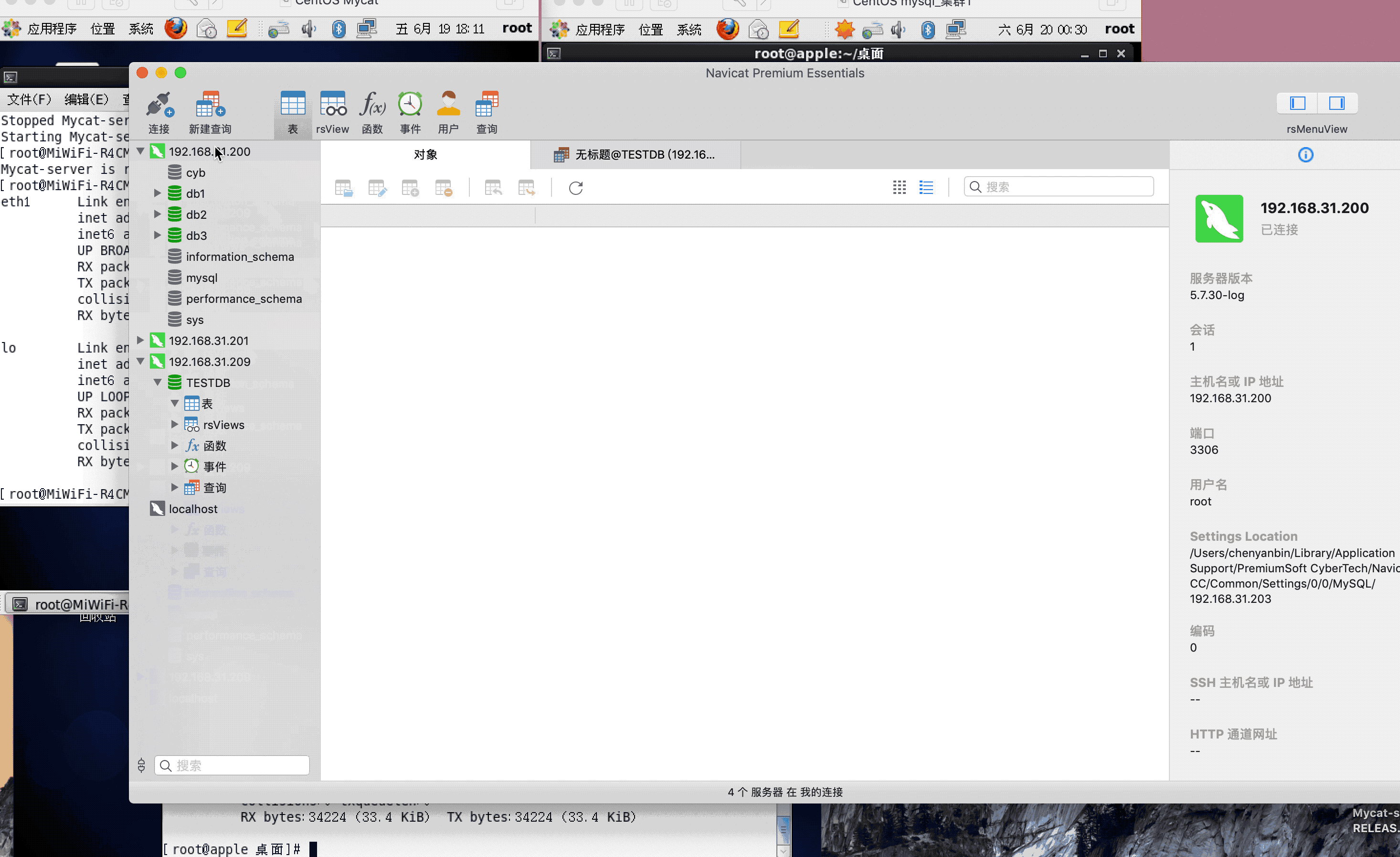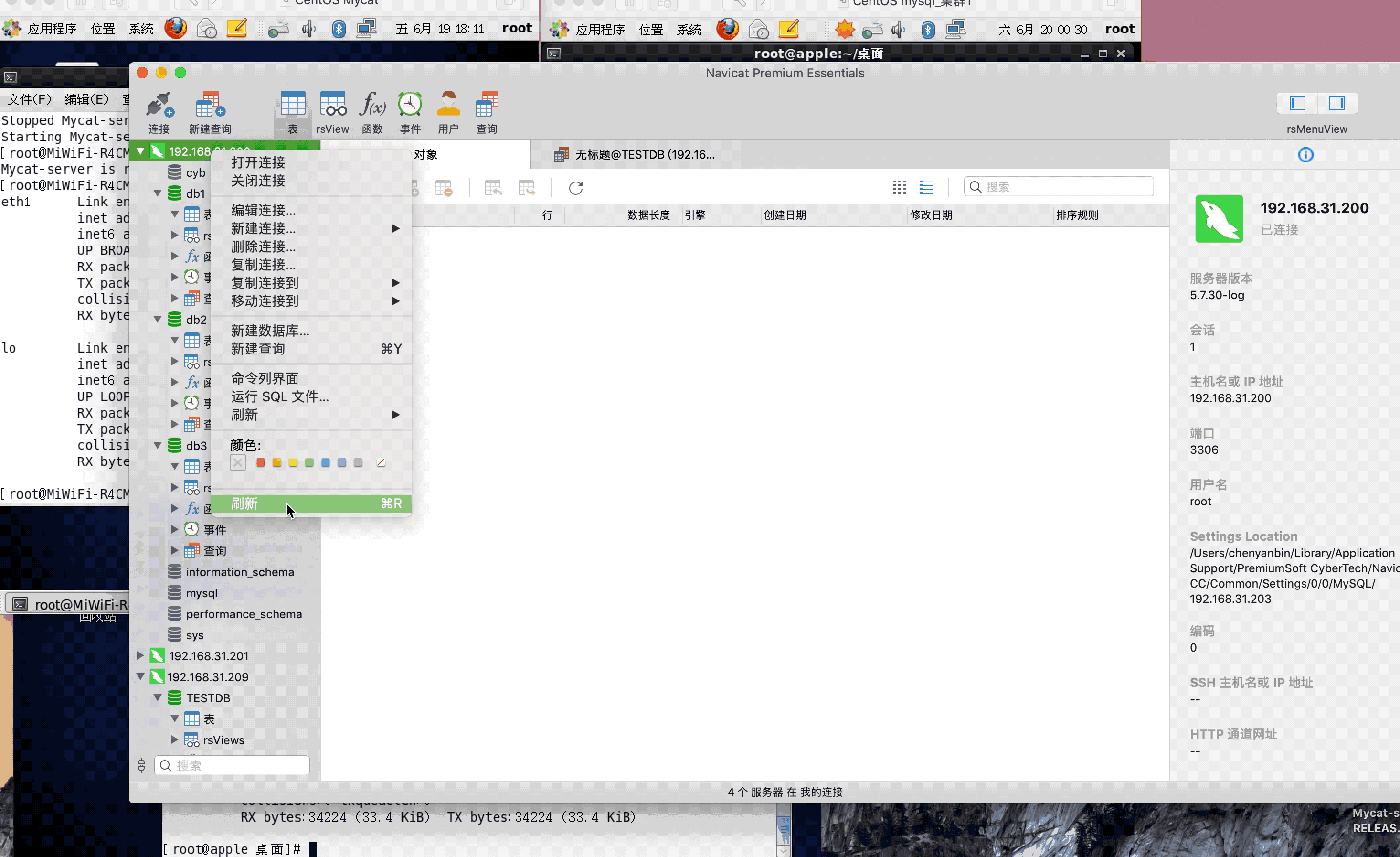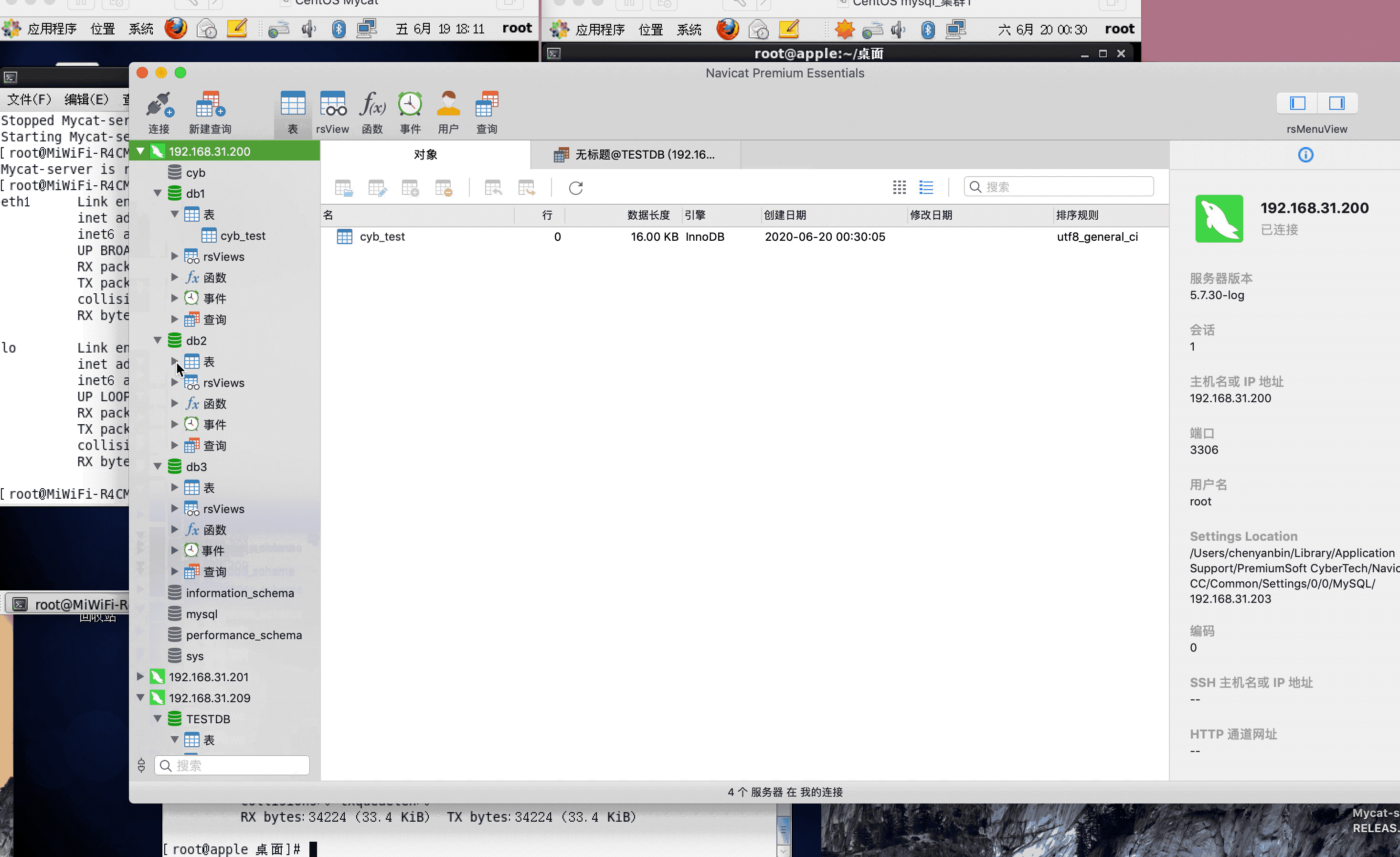
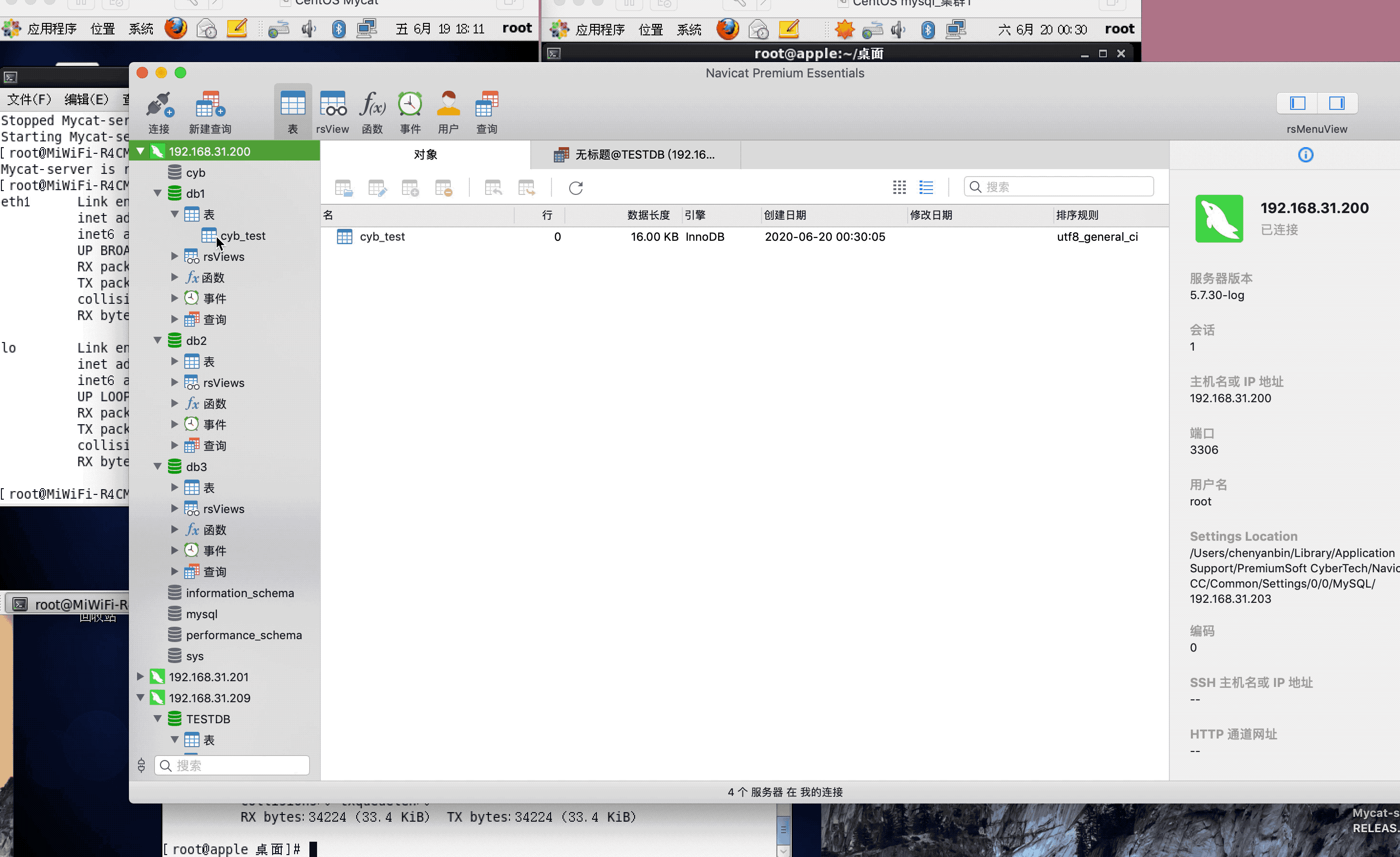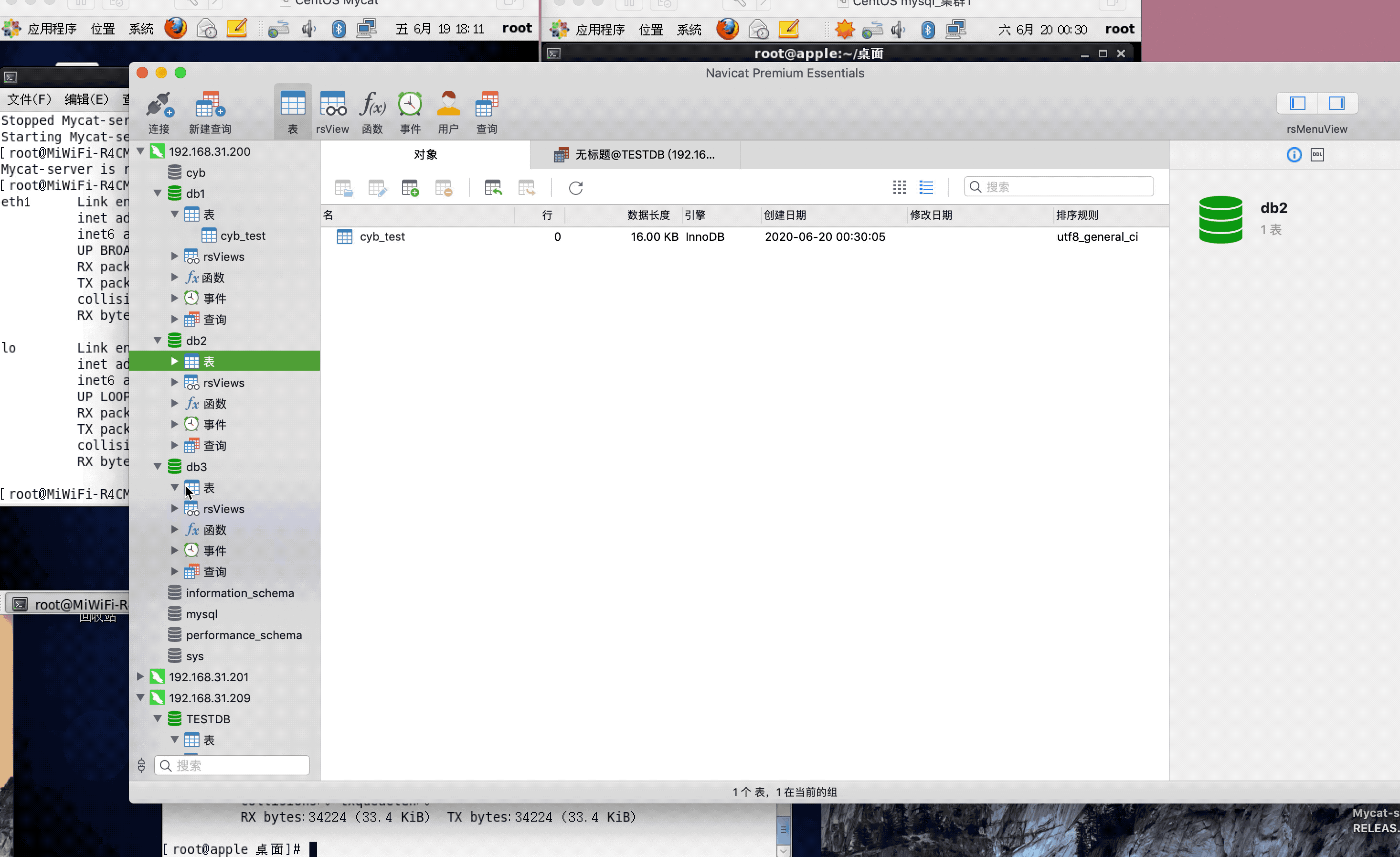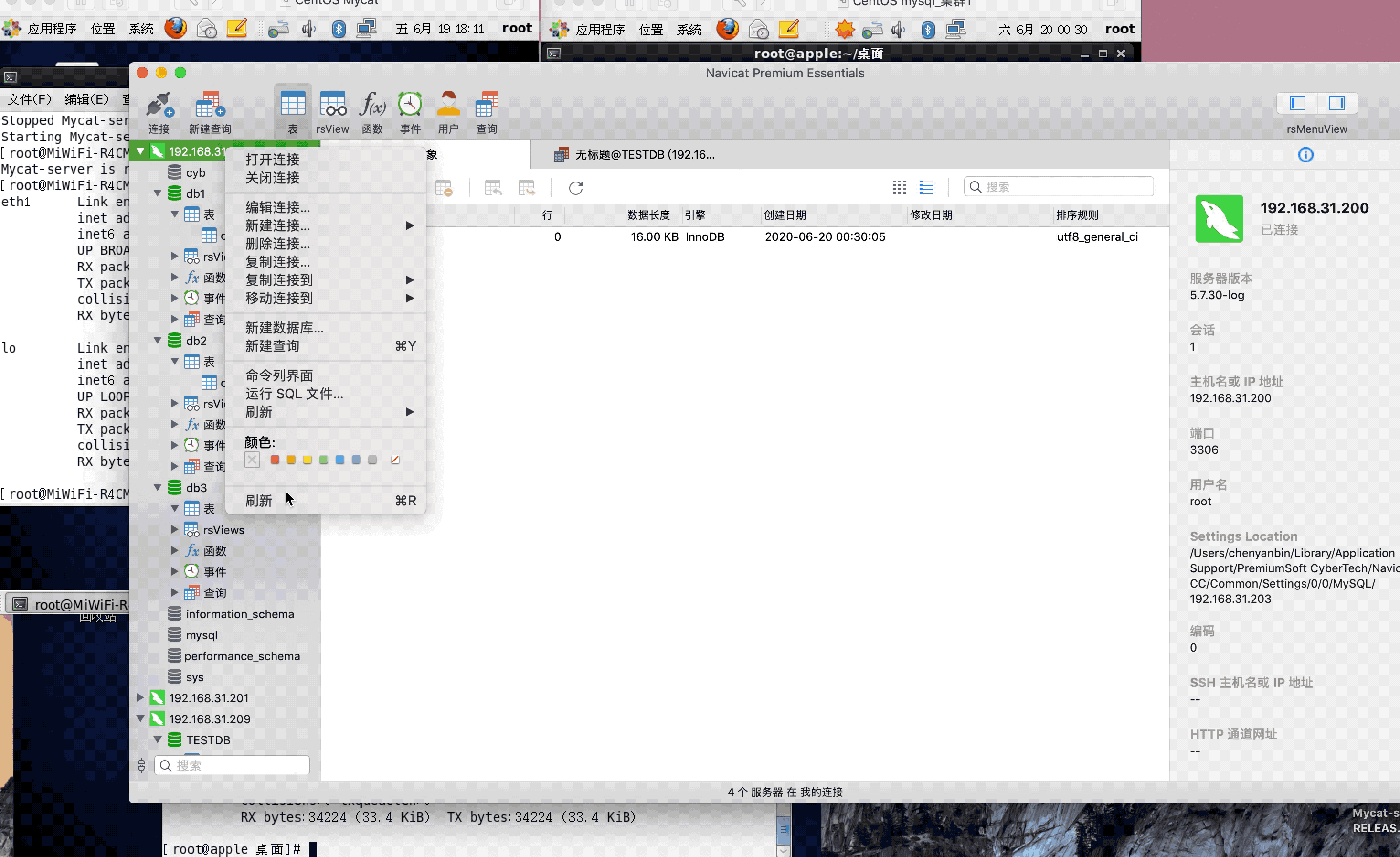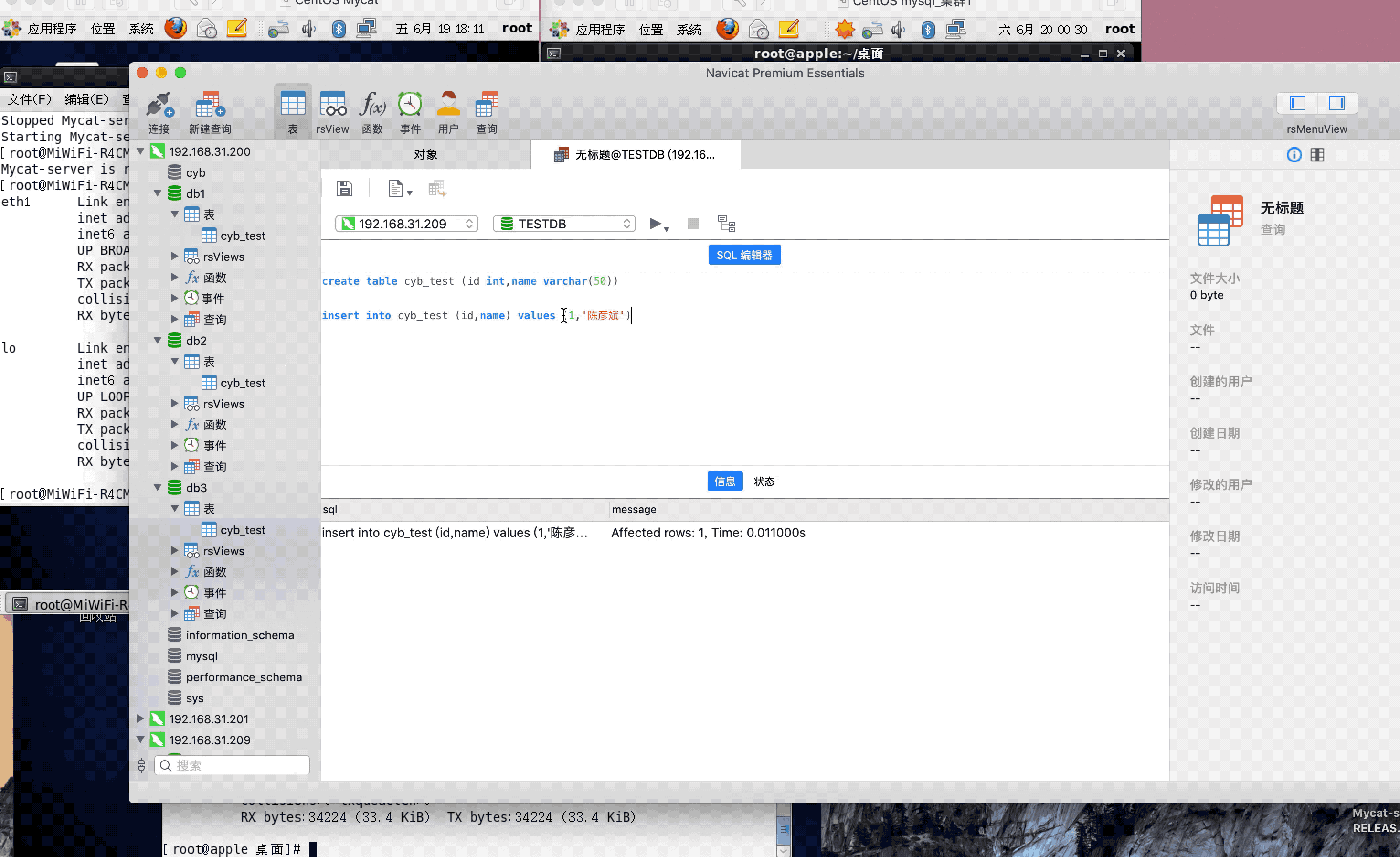
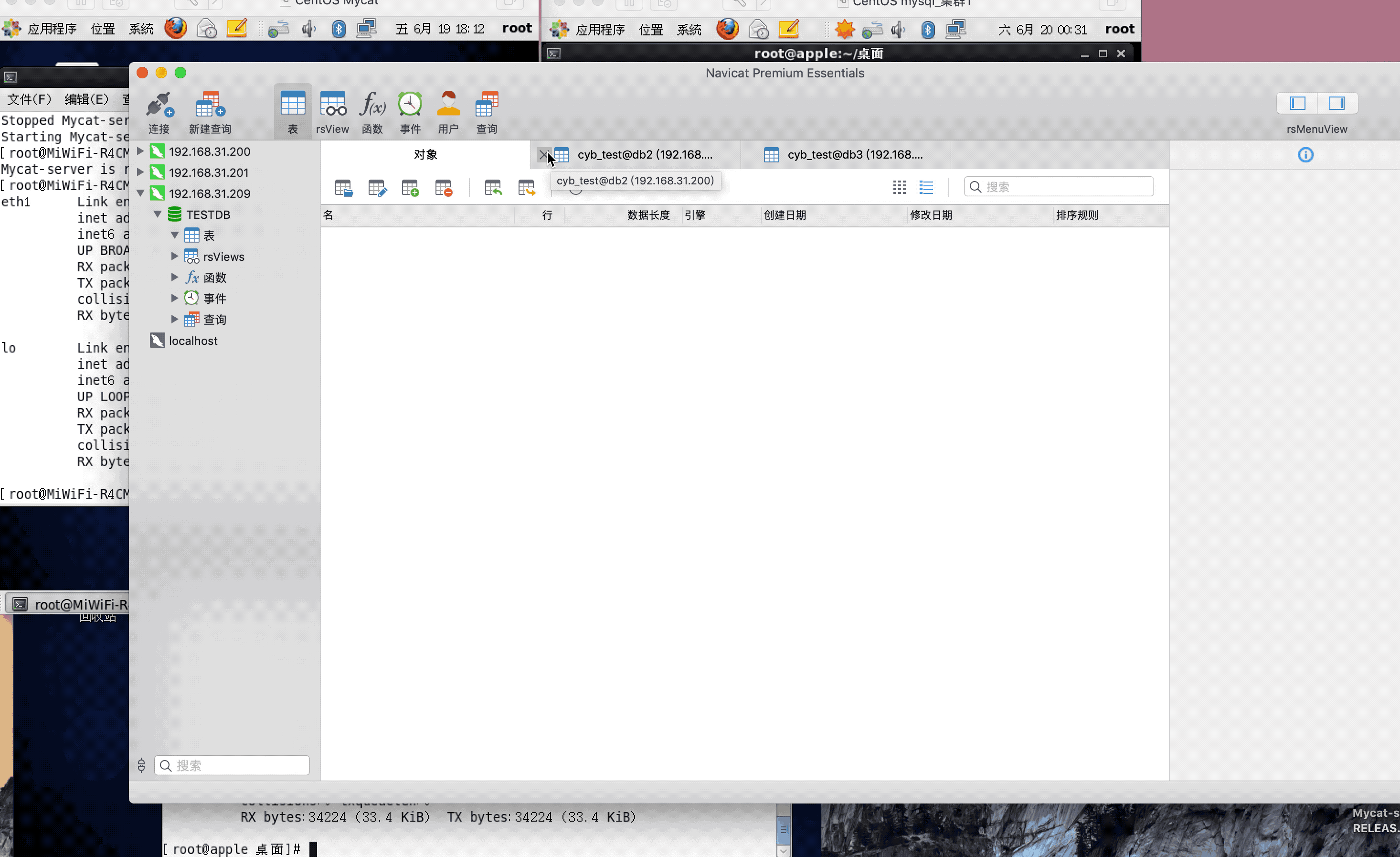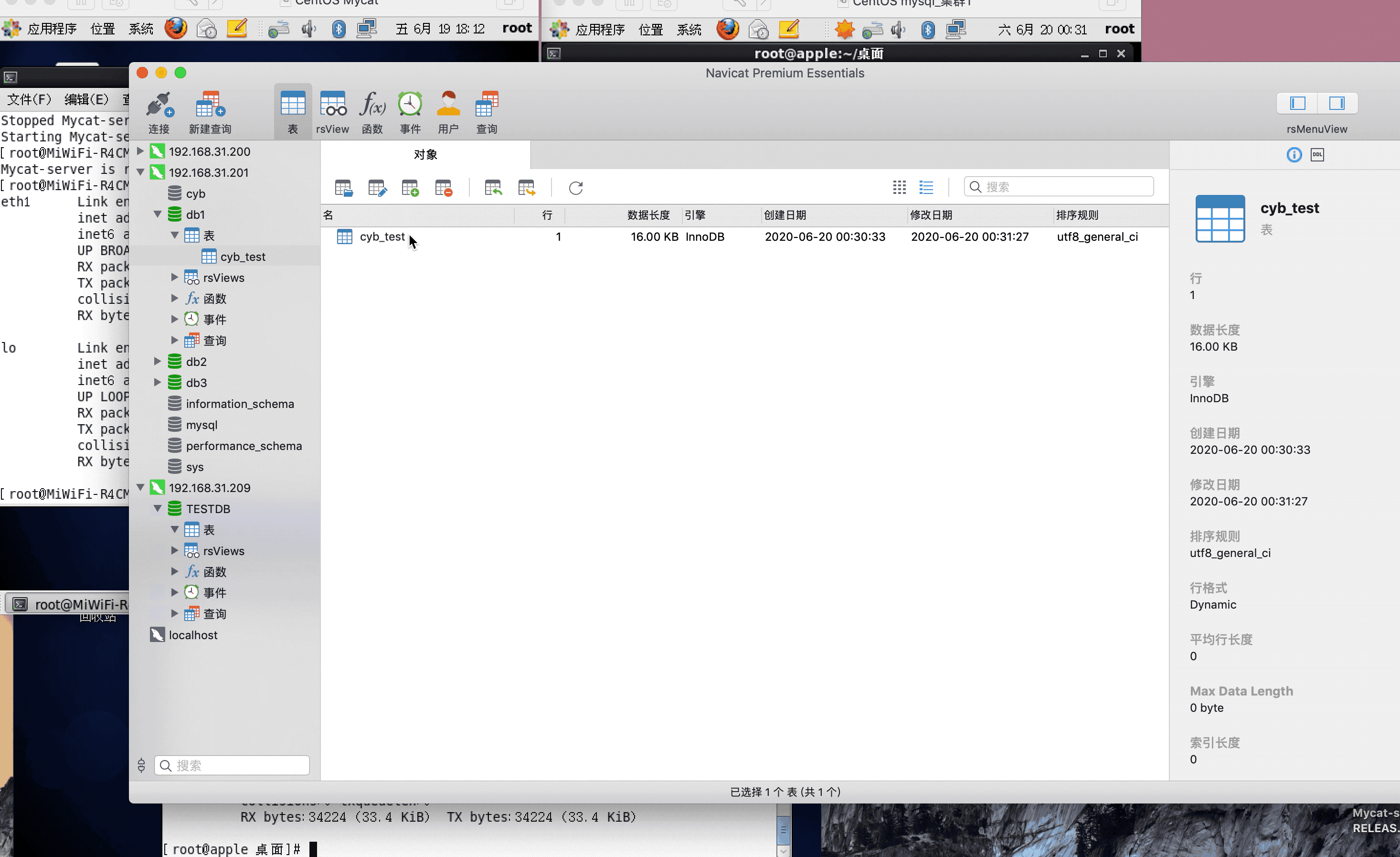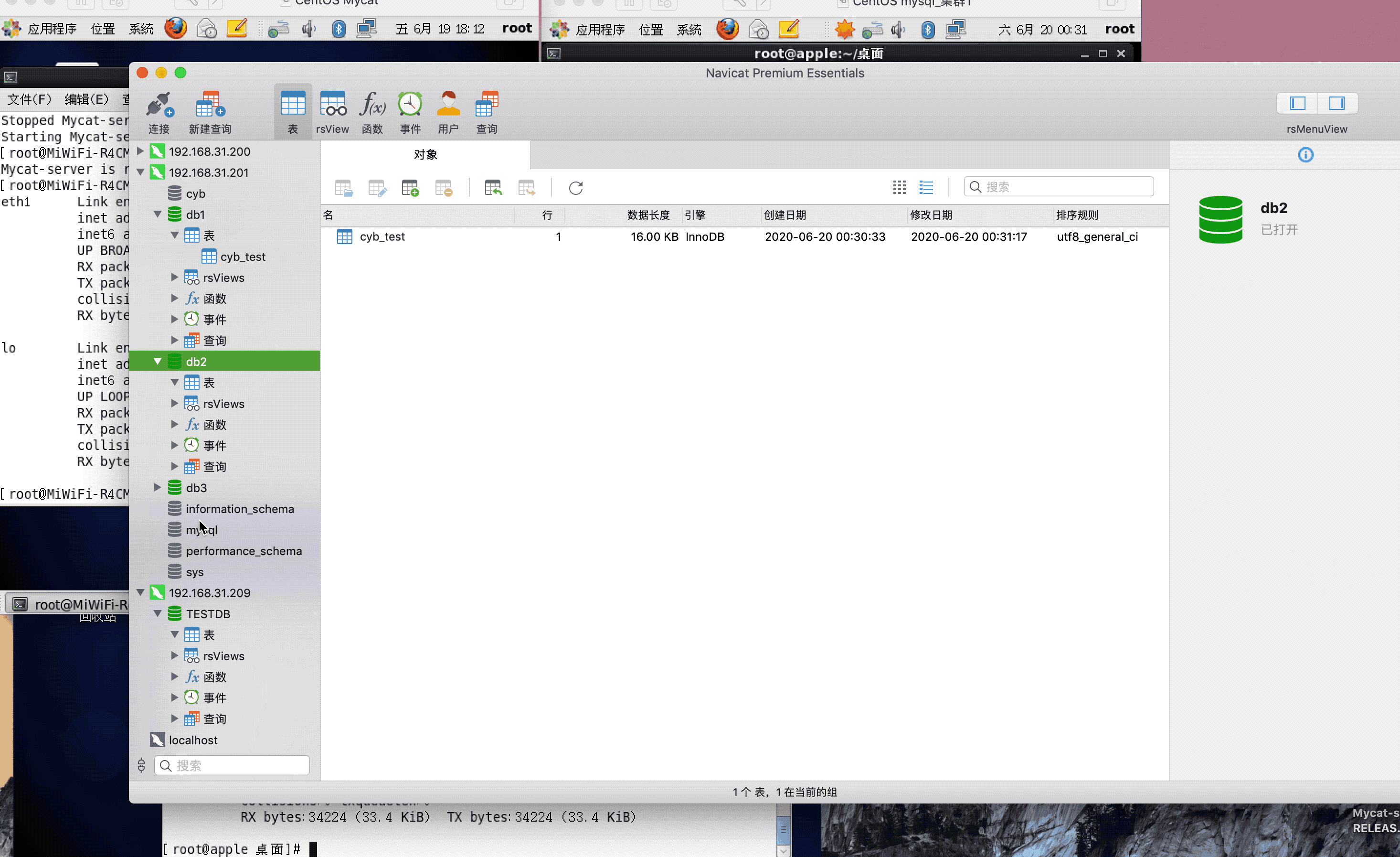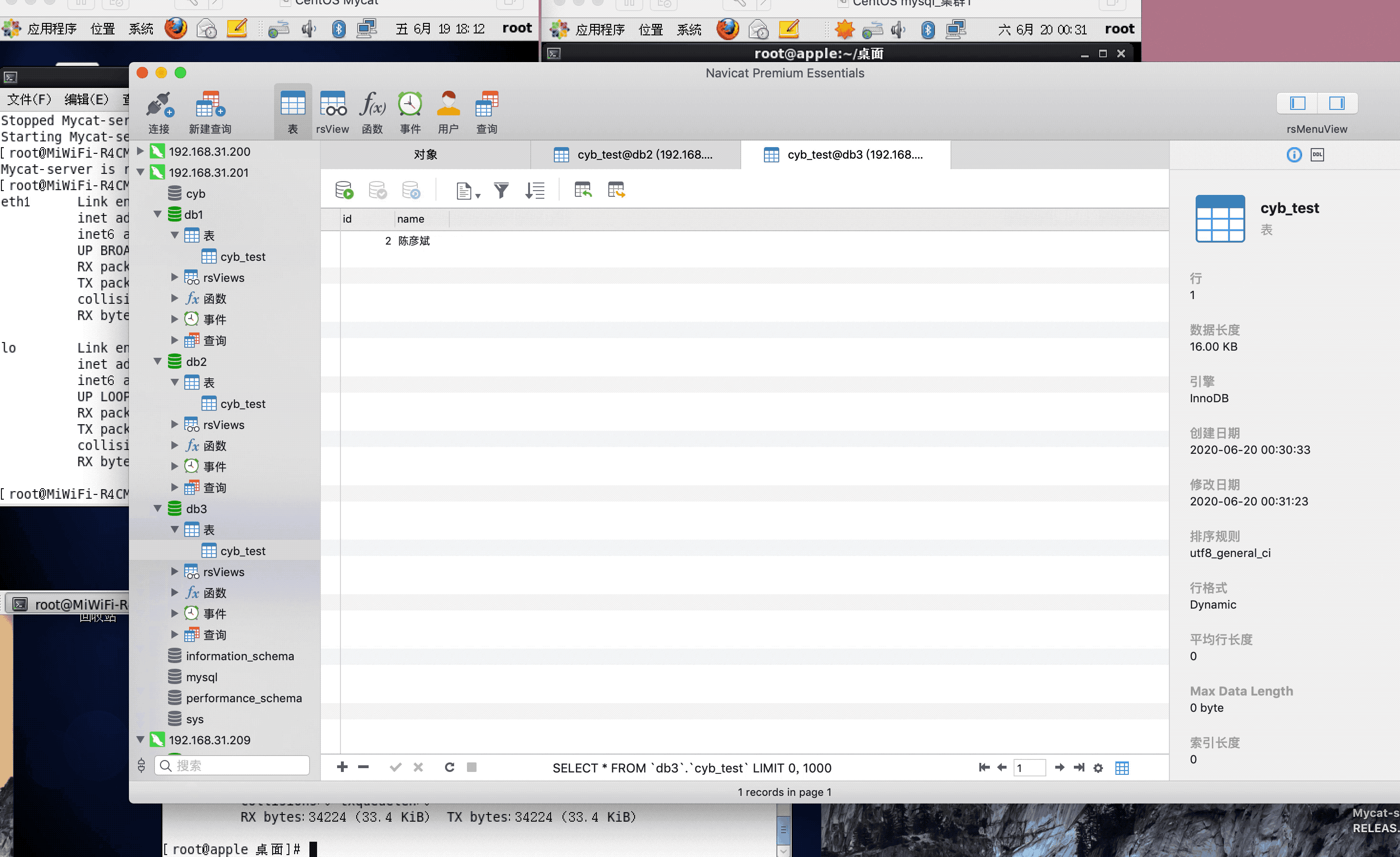
<table name="cyb_test" dataNode="dn1,dn2,dn3" rule="mod-long" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="192.168.31.200:3306" user="root"
password="root">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="192.168.31.201:3306" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
rule.xml
用途:定义了我们对表进行拆分所涉及到的规则定义,视情况修改参数
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule> <tableRule name="rule2">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule> <tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<tableRule name="latest-month-calldate">
<rule>
<columns>calldate</columns>
<algorithm>latestMonth</algorithm>
</rule>
</tableRule> <tableRule name="auto-sharding-rang-mod">
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule> <tableRule name="jch">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule> <function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function> <function name="crc32slot"
class="io.mycat.route.function.PartitionByCRC32PreSlot">
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
</function>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function> <function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
<function name="latestMonth"
class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function> <function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function> <function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">3</property>
</function>
</mycat:rule>
启动mycat
进入mycat/bin,启动mycat 启动命令:./mycat start
停止命令:./mycat stop
重启命令:./mycat restart
查看状态命令:./mycat status
注意,可以使用mysql的客户端直接连接mycat服务,默认端口为8066
错误日志(重要)
部署过程中,我碰到点小问题,找不到主机名,具体解决方案,请看我另一篇:点我直达 ,如果Mycat服务起不来,记得看错误日志哟!
测试
ip:192.168.31.200(mysql主服务器)
ip:192.168.31.201(mysql从服务器)
ip:192.168.31.209(mycat服务器)
注:演示过程中,因为mysql搭建了集群,主从复制,可能网络原因,有些延迟,或者mysql主从复制同步机制问题,导致刷新好几次,才显示出来,因为图片较大,被分割几张gif,内容都是连续的,验证结果,达到预期,演示成功!
MySQL集群搭建主从复制:点我直达
Linux MySQL分库分表之Mycat的更多相关文章
- 高可用Mysql架构_Mysql主从复制、Mysql双主热备、Mysql双主双从、Mysql读写分离(Mycat中间件)、Mysql分库分表架构(Mycat中间件)的演变
[Mysql主从复制]解决的问题数据分布:比如一共150台机器,分别往电信.网通.移动各放50台,这样无论在哪个网络访问都很快.其次按照地域,比如国内国外,北方南方,这样地域性访问解决了.负载均衡:M ...
- 你们要的MyCat实现MySQL分库分表来了
❝ 借助MyCat来实现MySQL的分库分表落地,没有实现过的,或者没了解过的可以看看 ❞ 前言 在之前写过一篇关于mysql分库分表的文章,那篇文章只是给大家提供了一个思路,但是回复下面有很多说是细 ...
- (转)企业Shell实战-MySQL分库分表备份脚本
本文来自http://www.xuliangwei.com/xubusi/252.html 免费视频讲解见 http://edu.51cto.com/course/course_id-5064.htm ...
- Mysql分库分表方案
Mysql分库分表方案 1.为什么要分表: 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. m ...
- MYSQL分库分表和不停机更改表结构
在MYSQL分库分表中我们一般是基于数据量比较大的时间对mysql数据库一种优化的做法,下面我简单的介绍一下mysql分表与分库的简单做法. .分库分表 很明显,一个主表(也就是很重要的表,例如用户表 ...
- MySQL分库分表备份脚本
MySQL分库备份脚本 #脚本详细内容 [root@db02 scripts]# cat /server/scripts/Store_backup.sh #!/bin/sh MYUSER=root M ...
- 【分库、分表】MySQL分库分表方案
一.Mysql分库分表方案 1.为什么要分表: 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. ...
- Java互联网架构-Mysql分库分表订单生成系统实战分析
概述 分库分表的必要性 首先我们来了解一下为什么要做分库分表.在我们的业务(web应用)中,关系型数据库本身比较容易成为系统性能瓶颈,单机存储容量.连接数.处理能力等都很有限,数据库本身的“有状态性” ...
- mysql分库分表(二)
mysql分库分表 参考: https://www.cnblogs.com/dongruiha/p/6727783.html https://www.cnblogs.com/oldUncle/p/64 ...
随机推荐
- ES[7.6.x]学习笔记(十一)与SpringBoot结合
在前面的章节中,我们把ES的基本功能都给大家介绍完了,从ES的搭建.创建索引.分词器.到数据的查询,大家发现,我们都是通过ES的API去进行调用,那么,我们在项目当中怎么去使用ES呢?这一节,我们就看 ...
- [nginx报错问题]reload时报错:nginx: [error] invalid PID number "" in ...
错误 第一次探索nginx,执行以下命令时: nginx -s reload 报出错误: nginx: [error] invalid PID number "" in ... * ...
- 4.String字符串类型操作
String类型操作 1.set key value 设置key对应的值为string类型的value 2.mset key1 value1 … keyN valueN 一次设置多个key的值 3. ...
- 一文读懂JAVA多线程
背景渊源 摩尔定律 提到多线程好多书上都会提到摩尔定律,它是由英特尔创始人之一Gordon Moore提出来的.其内容为:当价格不变时,集成电路上可容纳的元器件的数目,约每隔18-24个月便会增加一倍 ...
- SpringBoot—自定义线程池及并发定时任务模板
介绍 在项目开发中,经常遇到定时任务,今天通过自定义多线程池总结一下SpringBoot默认实现的定时任务机制. 定时任务模板 pom依赖 <dependencies> <dep ...
- 节点流(文件流) FileInputStream & FileOutputStream & FileReader & FileWriter
节点流(文件流) FileInputStream(字节流)处理视频类的 FileOutputStream(字节流) FileReader(字符流)处理文本文件 ...
- C# 委托浅析
C# 中的委托(Delegate)类似于 C 或 C++ 中函数的指针.委托(Delegate) 是存有对某个方法的引用的一种引用类型变量.引用可在运行时被改变. 委托(Delegate)特别用于实现 ...
- tomcat漏洞利用总结
一.后台war包getshell 漏洞利用: tomcat在conf/tomcat-users.xml配置用户权限 <?xml version="1.0" encoding= ...
- Vue中控制更新的方式
一. 强制更新的实例方法 vm.$forceUpdate() 迫使 Vue 实例重新渲染.注意它仅仅影响实例本身和插入插槽内容的子组件,而不是所有子组件. 在没有留意到数组或对象的变更检测注意事 ...
- Rocket - config - DefaultConfig
https://mp.weixin.qq.com/s/zWW00D0fb8h7_TotGD9YoQ 介绍DefaultConfig类的组成. 1. DefaultConfig Defa ...