python爬虫(九) requests库之post请求
1、方法:
response=requests.post("https://www.baidu.com/s",data=data)
2、拉勾网职位信息获取
因为拉勾网设置了反爬虫机制,在拉勾网中,一些页面的信息获取方法是post,所以就用到了post方法

在拉勾网中,我们搜索与python相关的职业,如果我们爬取这一页的信息,是没有职业的信息的,因为职业的信息在另外的jsp页面上,所以我们需要在这个界面上爬取到职业的信息,选择一个城市+学生身份
同样,在页面右击,选择查看元素,找到网络,刷新,选择跟职位相关的
然后右侧的网址为url:
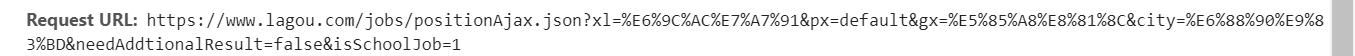
这个页面上面的网址为urls:

可以看到他的获取方法是post,所以我们要获取职位的信息,需要post函数
这时我们需要用到data参数
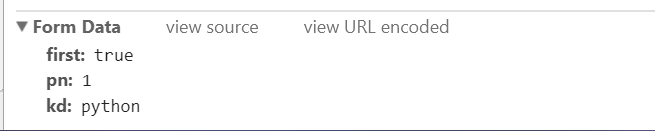
以及请求头:


代码如下:
import requests url='https://www.lagou.com/jobs/positionAjax.json?xl=%E6%9C%AC%E7%A7%91&px=default&gx=%E5%85%A8%E8%81%8C&city=%E6%88%90%E9%83%BD&needAddtionalResult=false&isSchoolJob=1'
data ={
'first':"true",
'pn':1,
'kd':"python"
}
headers={
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
'Referer':"https://www.lagou.com/jobs/list_python/p-city_252?px=default&gx=%E5%85%A8%E8%81%8C&gj=&xl=%E6%9C%AC%E7%A7%91&isSchoolJob=1",
'Accept':'application/json, text/javascript, */*; q=0.01'
}
urls='https://www.lagou.com/jobs/list_python/p-city_252?px=default&gx=%E5%85%A8%E8%81%8C&gj=&xl=%E6%9C%AC%E7%A7%91&isSchoolJob=1#filterBox'
s = requests.Session()
s.get(urls, headers=headers, timeout=3)
cookie = s.cookies
response = s.post('https://www.lagou.com/jobs/positionAjax.json?xl=%E6%9C%AC%E7%A7%91&px=default&gx=%E5%85%A8%E8%81%8C&city=%E6%88%90%E9%83%BD&needAddtionalResult=false&isSchoolJob=1',data=data,headers=headers, cookies=cookie,timeout=5) print(response.text)
with open('py.html', 'w') as file:
file.write(response.text)
中间出现错误:您操作太频繁,请稍后再访问,解决方法参考网址:http://www.freesion.com/article/140098505/
python爬虫(九) requests库之post请求的更多相关文章
- Python爬虫之requests库介绍(一)
一:Requests: 让 HTTP 服务人类 虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 ...
- Python爬虫:requests 库详解,cookie操作与实战
原文 第三方库 requests是基于urllib编写的.比urllib库强大,非常适合爬虫的编写. 安装: pip install requests 简单的爬百度首页的例子: response.te ...
- python爬虫之requests库
在python爬虫中,要想获取url的原网页,就要用到众所周知的强大好用的requests库,在2018年python文档年度总结中,requests库使用率排行第一,接下来就开始简单的使用reque ...
- Python爬虫之requests库的使用
requests库 虽然Python的标准库中 urllib模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests宣传是 "HTTP for ...
- 【Python爬虫】Requests库的基本使用
Requests库的基本使用 阅读目录 基本的GET请求 带参数的GET请求 解析Json 获取二进制数据 添加headers 基本的POST请求 response属性 文件上传 获取cookie 会 ...
- python爬虫(1)requests库
在pycharm中安装requests库的一种方法 首先找到设置 搜索然后安装,蓝色代表已经安装 requests库中的get请求 与HTTP协议相对应,requests库也有七种请求方式. 获取ur ...
- python爬虫之requests库介绍(二)
一.requests基于cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们 ...
- Python爬虫之Requests库的基本使用
import requests response = requests.get('http://www.baidu.com/') print(type(response)) print(respons ...
- Python爬虫系列-Requests库详解
Requests基于urllib,比urllib更加方便,可以节约我们大量的工作,完全满足HTTP测试需求. 实例引入 import requests response = requests.get( ...
- python 爬虫 基于requests模块的get请求
需求:爬取搜狗首页的页面数据 import requests # 1.指定url url = 'https://www.sogou.com/' # 2.发起get请求:get方法会返回请求成功的响应对 ...
随机推荐
- AngularJS请求数据提示resource from url not allowed by $sceDelegate policy
AngularJS iframe跨域打开内容时报错 解决方案 使用 $sceDelegateProvider 配置跨域请求域名 config.js app.config(function($sce ...
- queue的使用-Hdu 1702
ACboy needs your help again! Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K ( ...
- [Fiddler学习] - Mock的简单实现原理及方法
最近在研究Fidder抓包并做一点测试工作,下面介绍一下Fiddler的实现原理: 简单来说从clent,server端发出来的请求,都需要通过Fiddler进行代理走一遍.如果有任何请求需要做修改, ...
- PHP 文件上传之如何识别文件伪装?——PHP的fileinfo扩展可!
问题:文件上传时候需要验证上传的文件是否合法,文件伪装如何识别? 一个简单测试:把txt文件后缀直接改成jpg;上传 <!DOCTYPE html> <html> <ti ...
- 开源协议:LGPL协议、OSGi协议
本文介绍开源的协议. LGPL 是 GNU Lesser General Public License (GNU 宽通用公共许可证)的缩写形式,旧称 GNU Library General Publi ...
- 红帽RHCE培训-课程2笔记内容
1 kickstart自动安装 已安装系统中,在root下述目录会自动生成kickstart配置文件 ll ~/anaconda-ks.cfg 关键配置元素注释,详见未精简版 创建Kickstart配 ...
- 解决VMware Workstation下Win2012R2无法安装Hyper-v问题
有时候我们需要测试Hyper-V但是发现VMware下不能够正常安装,提示:验证过程发现你要安装功能的服务器存在问题.所选功能与所选服务器的当前配置不兼容.无法安装Hyper-V:虚拟机监控程序已在运 ...
- eclipse修改快捷键
eclipse修改快捷键 ctrl + shift + l查看快捷键 window -> preferences -> 搜索keys 鼠标点击以下五个表头,可以按照内容搜索 示例,选中Bi ...
- html学习-第一集(基本标签)
什么是HTML html是一套规则,浏览器认识的规则 开发者怎么使用html 学习HTML语言 开发后台程序 写HTML文件 从数据库获取数据,然后替换到html中对应的位子(web框架) HTML文 ...
- 【转】通过python调用jenkins 常用api操作
原:https://www.cnblogs.com/L-O-N/p/11608220.html # -*- coding: utf- -*- import jenkins class TestJenk ...