POJ 1080:Human Gene Functions LCS经典DP
| Time Limit: 1000MS | Memory Limit: 10000K | |
| Total Submissions: 18007 | Accepted: 10012 |
Description
these can be used to diagnose human diseases and to design new drugs for them.
A human gene can be identified through a series of time-consuming biological experiments, often with the help of computer programs. Once a sequence of a gene is obtained, the next job is to determine its function.
One of the methods for biologists to use in determining the function of a new gene sequence that they have just identified is to search a database with the new gene as a query. The database to be searched stores many gene sequences and their functions – many
researchers have been submitting their genes and functions to the database and the database is freely accessible through the Internet.
A database search will return a list of gene sequences from the database that are similar to the query gene.
Biologists assume that sequence similarity often implies functional similarity. So, the function of the new gene might be one of the functions that the genes from the list have. To exactly determine which one is the right one another series of biological experiments
will be needed.
Your job is to make a program that compares two genes and determines their similarity as explained below. Your program may be used as a part of the database search if you can provide an efficient one.
Given two genes AGTGATG and GTTAG, how similar are they? One of the methods to measure the similarity
of two genes is called alignment. In an alignment, spaces are inserted, if necessary, in appropriate positions of
the genes to make them equally long and score the resulting genes according to a scoring matrix.
For example, one space is inserted into AGTGATG to result in AGTGAT-G, and three spaces are inserted into GTTAG to result in –GT--TAG. A space is denoted by a minus sign (-). The two genes are now of equal
length. These two strings are aligned:
AGTGAT-G
-GT--TAG
In this alignment, there are four matches, namely, G in the second position, T in the third, T in the sixth, and G in the eighth. Each pair of aligned characters is assigned a score according to the following scoring matrix.
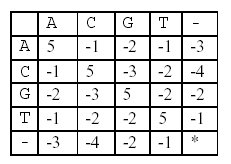
denotes that a space-space match is not allowed. The score of the alignment above is (-3)+5+5+(-2)+(-3)+5+(-3)+5=9.
Of course, many other alignments are possible. One is shown below (a different number of spaces are inserted into different positions):
AGTGATG
-GTTA-G
This alignment gives a score of (-3)+5+5+(-2)+5+(-1) +5=14. So, this one is better than the previous one. As a matter of fact, this one is optimal since no other alignment can have a higher score. So, it is said that the
similarity of the two genes is 14.
Input
is at least one and does not exceed 100.
Output
Sample Input
2
7 AGTGATG
5 GTTAG
7 AGCTATT
9 AGCTTTAAA
Sample Output
14
21
题意是要找一对基因序列的最大相似度。这个最大相似度来源于每一对字母的相似度相加(方框里的),但让人蛋疼的是,每一对字母之间是可以错位的,不一定是一对一那么匹配,可以空出来一位让‘-’去和原字母匹配去,所以这样就增加了难度,要用DP。
这个题我真的是想递推关系想不出来啊啊啊,结果看了discuss中的思路才明白过来,是这样:
假设上面序列的是A1A2A3A4......Am
下面序列式B1B2B3B4....Bn,然后用f[m][n]表示A长度为m,B长度为n时的最大相似程度。
好,我们假设现在比对的是Am和Bn这里,比对这里的话,就有三个情况:
1)Am=Bn
这样结果会是:
XXXXXAm
XXXXXBn
那么此时递推的关系也就是
f[m][n]=f[m-1][n-1]+pipei(Am,Bn)
2)Am不等于Bn
这样结果可能会是
XXXXXAm
XXXXX -
那么此时的递推关系就是
f[m][n]=f[m-1][n]+pipei(Am,'-')
3)Am不等于Bn
XXXXX -
XXXXX Bn
此时的递推关系是f[m][n-1]+pipei('-',Bn),从这三个情况中选择最大值。
递推关系是这样的话,是必须初始化的(因为存在着最佳匹配是第一个字符与‘-’匹配的情况)
即f[m][0]=f[m-1][0]+pipei(Am,'-')
f[0][n]=f[0][n-1]+pipei('-',Bn)
代码:
#include <iostream>
#include <algorithm>
#include <cmath>
#include <vector>
#include <string>
#include <cstring>
#include <map>
#pragma warning(disable:4996)
using namespace std; int matrix[5][5]={{5,-1,-2,-1,-3},
{-1,5,-3,-2,-4},
{-2,-3,5,-2,-2},
{-1,-2,-2,5,-1},
{-3,-4,-2,-1,0}
};
map<char,int>pair1;
int num1,num2;
char test1[150],test2[150];
int dp[150][150]; void cal()
{
memset(dp,0,sizeof(dp)); int i,j;
for(i=0;i<num1;i++)
{
dp[i+1][0]=dp[i][0]+matrix[pair1[test1[i]]][pair1['-']];
}
for(j=0;j<num2;j++)
{
dp[0][j+1]=dp[0][j]+matrix[pair1['-']][pair1[test2[j]]];
}
for(i=0;i<num1;i++)
{
for(j=0;j<num2;j++)
{
dp[i+1][j+1]= max(dp[i][j]+matrix[pair1[test1[i]]][pair1[test2[j]]],
max(dp[i][j+1]+matrix[pair1[test1[i]]][pair1['-']],dp[i+1][j]+matrix[pair1['-']][pair1[test2[j]]]));
}
}
cout<<dp[num1][num2]<<endl;
} int main()
{
pair1['A']=0;
pair1['C']=1;
pair1['G']=2;
pair1['T']=3;
pair1['-']=4; int Test;
scanf("%d",&Test); while(Test--)
{
cin>>num1>>test1;
cin>>num2>>test2; cal();
}
return 0;
}
版权声明:本文为博主原创文章,未经博主允许不得转载。
POJ 1080:Human Gene Functions LCS经典DP的更多相关文章
- poj 1080 Human Gene Functions(lcs,较难)
Human Gene Functions Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 19573 Accepted: ...
- poj 1080 ——Human Gene Functions——————【最长公共子序列变型题】
Human Gene Functions Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 17805 Accepted: ...
- POJ 1080 Human Gene Functions -- 动态规划(最长公共子序列)
题目地址:http://poj.org/problem?id=1080 Description It is well known that a human gene can be considered ...
- dp poj 1080 Human Gene Functions
题目链接: http://poj.org/problem?id=1080 题目大意: 给两个由A.C.T.G四个字符组成的字符串,可以在两串中加入-,使得两串长度相等. 每两个字符匹配时都有个值,求怎 ...
- poj 1080 Human Gene Functions(dp)
题目:http://poj.org/problem?id=1080 题意:比较两个基因序列,测定它们的相似度,将两个基因排成直线,如果需要的话插入空格,使基因的长度相等,然后根据那个表格计算出相似度. ...
- POJ 1080 Human Gene Functions 【dp】
题目大意:每次给出两个碱基序列(包含ATGC的两个字符串),其中每一个碱基与另一串中碱基如果配对或者与空串对应会有一个分数(可能为负),找出一种方式使得两个序列配对的分数最大 思路:字符串动态规划的经 ...
- POJ 1080 Human Gene Functions
题意:给两个DNA序列,在这两个DNA序列中插入若干个'-',使两段序列长度相等,对应位置的两个符号的得分规则给出,求最高得分. 解法:dp.dp[i][j]表示第一个字符串s1的前i个字符和第二个字 ...
- poj 1080 Human Gene Functions (最长公共子序列变形)
题意:有两个代表基因序列的字符串s1和s2,在两个基因序列中通过添加"-"来使得两个序列等长:其中每对基因匹配时会形成题中图片所示匹配值,求所能得到的总的最大匹配值. 题解:这题运 ...
- hdu 1080 Human Gene Functions(DP)
题意: 人类基因由A.C.G.T组成. 有一张5*5的基因表.每格有一个值,叫相似度.例:A-C:-3.意思是如果A和C配对, 则它俩的相似度是-3[P.S.:-和-没有相似度,即-和-不能配对] 现 ...
随机推荐
- L2-012. 关于堆的判断(最小堆)
将一系列给定数字顺序插入一个初始为空的小顶堆H[].随后判断一系列相关命题是否为真.命题分下列几种: “x is the root”:x是根结点: “x and y are siblings”:x和y ...
- vSphere中Storage vMotion的流程详解
内容预览: 1. Storage vMotion的迁移方式 2. 影响Storage vMotion效率的因素 3. Storage vMotion的详细流程 企业部署虚拟化后,如果发现存储的性能出现 ...
- 小程序导航组件navigator活学活用
小程序开发中必不可少的组件navigator,虽然使用频率非常高,但是却没多少人能灵活运用. 先说navigator组件的用处: 它的主要用处是跳转执行,跳转可分为当前页面内跳转.前往页面外部的跳转. ...
- crashpad 应用程序异常解决方案
衡量某个应用程序的稳定性的一个重要指标即它自身的崩溃率的统计,但是如何判断应用程序崩溃,且上报崩溃产生的dmp文件进行分析? google提供了一套开源的系统 Crashpad,详细了解参见 http ...
- 神奇的i++
神奇的i++ i++,++i,多简单啊,不需要深入研究吧!!! 我是这样想的. 直到我做了一道Java基础检测题,才发现,哦,原来是这样啊!!! 题是这样的 public class Demo { p ...
- 043、Java中逻辑运算之实现位与操作
01.代码如下: package TIANPAN; /** * 此处为文档注释 * * @author 田攀 微信382477247 */ public class TestDemo { public ...
- DateTimePicker控件在WinXP下的BUG
如图,通过图示的按钮改变datetimepicker的值 ,弹出MessageBox, datetimePicker重新获得焦点后,自动重复点击按钮. 解决办法: new Thread(() => ...
- .net 4.0 : Missing compiler required member 'Microsoft.CSharp.RuntimeBinder.Binder.****'
解决办法,添加 MicroSoft.CSharp 的引用.
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 字体图标(Glyphicons):glyphicon glyphicon-minus
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name ...
- docker-compose(grafana influxdb) + telegraf 快速搭建简单监控
灵活实现方案: 1: telegraf 为go 语言写得占用内存小 收集主机各项监控数据 定时写入 时序DB influxdb ------------------------&qu ...