scrapy补充-分布式爬虫
spiders
介绍:在项目中是创建爬虫程序的py文件
#1、Spiders是由一系列类(定义了一个网址或一组网址将被爬取)组成,具体包括如何执行爬取任务并且如何从页面中提取结构化的数据。 #2、换句话说,Spiders是你为了一个特定的网址或一组网址自定义爬取和解析页面行为的地方
Spiders会循环做如下的几件事
#1、生成初始的Requests来爬取第一个URLS,并且标识一个回调函数
第一个请求定义在start_requests()方法内默认从start_urls列表中获得url地址来生成Request请求,默认的回调函数是parse方法。回调函数在下载完成返回response时自动触发 #2、在回调函数中,解析response并且返回值
返回值可以4种:
包含解析数据的字典
Item对象
新的Request对象(新的Requests也需要指定一个回调函数)
或者是可迭代对象(包含Items或Request) #3、在回调函数中解析页面内容
通常使用Scrapy自带的Selectors,但很明显你也可以使用Beutifulsoup,lxml或其他你爱用啥用啥。 #4、最后,针对返回的Items对象将会被持久化到数据库
通过Item Pipeline组件存到数据库:https://docs.scrapy.org/en/latest/topics/item-pipeline.html#topics-item-pipeline)
或者导出到不同的文件(通过Feed exports:https://docs.scrapy.org/en/latest/topics/feed-exports.html#topics-feed-exports)
Spiders总共提供了五种类:
#1、scrapy.spiders.Spider #scrapy.Spider等同于scrapy.spiders.Spider
#2、scrapy.spiders.CrawlSpider
#3、scrapy.spiders.XMLFeedSpider
#4、scrapy.spiders.CSVFeedSpider
#5、scrapy.spiders.SitemapSpider
导入使用
# -*- coding: utf-8 -*-
import scrapy
from scrapy.spiders import Spider,CrawlSpider,XMLFeedSpider,CSVFeedSpider,SitemapSpider class AmazonSpider(scrapy.Spider): #自定义类,继承Spiders提供的基类
name = 'amazon'
allowed_domains = ['www.amazon.cn']
start_urls = ['http://www.amazon.cn/'] ```
def parse(self, response):
pass
```
数据存储到mongodb
pipelins的使用流程:
settings.py配置,item里定义要获取的数据的models,pipelins.py里连接数据库,cnblogs.py书写爬取数据的内容。
1、 在item中写一个类,有一个一个字段,类似django的models
import scrapy # class MyscrapyItem(scrapy.Item):
# # define the fields for your item here like:
# # name = scrapy.Field()
# pass
class ArticleItem(scrapy.Item):
article_name = scrapy.Field()
article_url = scrapy.Field()
auther_name = scrapy.Field()
commit_count = scrapy.Field()
2、settings.py,在setting中配置pipeline,优先级。

3、 pipelines.py
连接数据库,书写一堆方法
# -ArticleMongodbPipeline
-init
-from_crawler
-open_spider
-close_spider
-process_item
-相应的写存储
return的东西是有区别的,如果item,下一个pipelins能够继续拿到,如果return None,下一个拿不到
# -ArticleFilePipeline
代码实现:
# -*- coding: utf-8 -*- from pymongo import MongoClient
class ArticleMongodbPipeline(object):
def process_item(self, item, spider): # client = MongoClient('mongodb://localhost:27017/')
#连接
client = MongoClient('localhost', 27017)
#创建article数据库,如果没有叫创建,如果有,叫使用
db = client['article']
# print(db)
#如果有使用articleinfo,如果没有,创建这个表
article_info=db['articleinfo'] article_info.insert(dict(item))
# article_info.save({'article_name':item['article_name'],'aritcle_url':item['article_url']})
# 如果retrun None ,下一个就取不到item了,取到的就是None class ArticleFilePipeline(object):
# def __init__(self,host,port):
def __init__(self):
# self.mongo_conn=MongoClient(host,port)
pass #如果这个类中有from_crawler,首先会执行from_crawler,aa=ArticleFilePipeline.from_crawler(crawler)
#如果没有直接aa=ArticleFilePipeline()
@classmethod
def from_crawler(cls, crawler):
print('有')
#mongodb的配置信息在setting中
# host = '从配置文件中拿出来的'
# port='从配置文件中拿出来的'
#crawler.settings总的配置文件
print('asdfasdfasfdasfd',crawler.settings['AA'])
# return cls(host,port)
return cls() def open_spider(self, spider):
# print('----',spider.custom_settings['AA'])
self.f = open('article.txt','a') def close_spider(self, spider):
self.f.close()
print('close spider') def process_item(self, item, spider):
pass
去重
去重规则应该多个爬虫共享的,但凡一个爬虫爬取了,其他都不要爬了,实现方式如下。
#方法一:
1、新增类属性
visited=set() #类属性 2、回调函数parse方法内:
def parse(self, response):
if response.url in self.visited:
return None
....... ```
self.visited.add(response.url)
``` #方法一改进:针对url可能过长,所以我们存放url的hash值
def parse(self, response):
url=md5(response.request.url)
if url in self.visited:
return None
....... ```
self.visited.add(url)
```
方法二:Scrapy自带去重功能
配置文件:
DUPEFILTER_CLASS = 'scrapy.dupefilter.RFPDupeFilter' #默认的去重规则帮我们去重,去重规则在内存中
DUPEFILTER_DEBUG = False
JOBDIR = "保存范文记录的日志路径,如:/root/" # 最终路径为 /root/requests.seen,去重规则放文件中 scrapy自带去重规则默认为RFPDupeFilter,只需要我们指定
Request(...,dont_filter=False) ,如果dont_filter=True则告诉Scrapy这个URL不参与去重
系统自带的去重方法在settings中配置:

需要手动实现自自定义去重的几个方法,
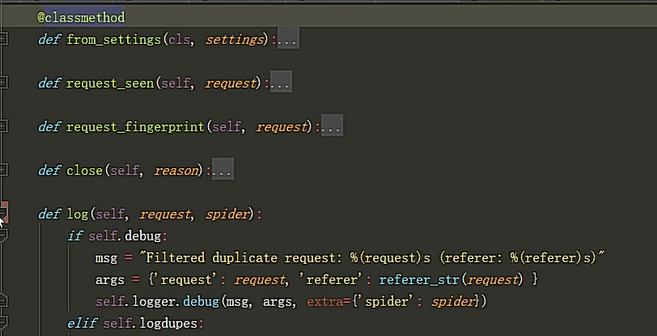
方法三:自定义去重方案
我们也可以仿照RFPDupeFilter自定义去重规则,
# from scrapy.dupefilter import RFPDupeFilter,看源码,仿照BaseDupeFilter
#步骤一:在项目目录下自定义去重文件dup.py
class UrlFilter(object):
def __init__(self):
self.visited = set() #或者放到数据库 @classmethod
def from_settings(cls, settings):
return cls() ```
def request_seen(self, request):
if request.url in self.visited:
return True
self.visited.add(request.url) def open(self): # can return deferred
pass def close(self, reason): # can return a deferred
pass def log(self, request, spider): # log that a request has been filtered
pass
#步骤二:配置文件settings.py:
DUPEFILTER_CLASS = '项目名.dup.UrlFilter' # 源码分析:
from scrapy.core.scheduler import Scheduler
见Scheduler下的enqueue_request方法:self.df.request_seen(request)
例子:
import scrapy class MySpider(scrapy.Spider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = [
'http://www.example.com/1.html',
'http://www.example.com/2.html',
'http://www.example.com/3.html',
] ```
def parse(self, response):
self.logger.info('A response from %s just arrived!', response.url)
```
爬虫去重方案
去重一般是对URL去重,访问过的页面不在访问,但是也有例外,比如一些网站有用户评论,内容是不断变化的,若爬取评论,则就不能以URL作为去重标准,但本质上都可以看做针对字符串的去重。
去重可以避免网络之间的环路,并且增加爬取效率。常见有以下几种方式:
- 关系数据库去重:查询导致效率低,不推荐。
- 缓存数据库去重: 如Redis,使用其中的Set数据类型,并可将内存中的数据持久化,应用广泛,推荐。
- 内存去重:最大制约是内存大小和掉电易失。
- URL直接存到HashSet中:太消耗内存。
- URL经过MD5或SHA-1等哈希算法生成摘要,再存到HashSet中。MD5处理后摘要长度128位,SHA-1摘要长度160位,这样占用内存比直接存小很多。
- 采用Bit-Map方法,建立一个BitSet,每个URL经过一个哈希函数映射到一位,消耗内存最少,但是发生冲突概率太高,易误判。
综上,比较好的方式为:内存去重第二种方式+缓存数据库。基本可以满足大多数中型爬虫需要。数据量上亿或者几十亿时,就需要用BloomFilter算法了。
BloomFilter算法:
布隆过滤器:可以很快的实现去重的方法,缓存的内存很小,比hush占用的内存小,同时也解决了缓存穿透、缓存雪崩、缓存击穿。
概念详见:
# https://baijiahao.baidu.com/s?id=1619572269435584821&wfr=spider&for=pc
Dowloader Middeware
下载中间件的用途:
"""
1、在process——request内,自定义下载,不用scrapy的下载
2、对请求进行二次加工,比如
设置请求头
设置cookie
添加代理
scrapy自带的代理组件:
from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware
from urllib.request import getproxies
"""
使用自定义的时候必须打开settings.py里的设置

一般创建Scrapy项目时都会自带中间件:爬虫中间件和下载中间件
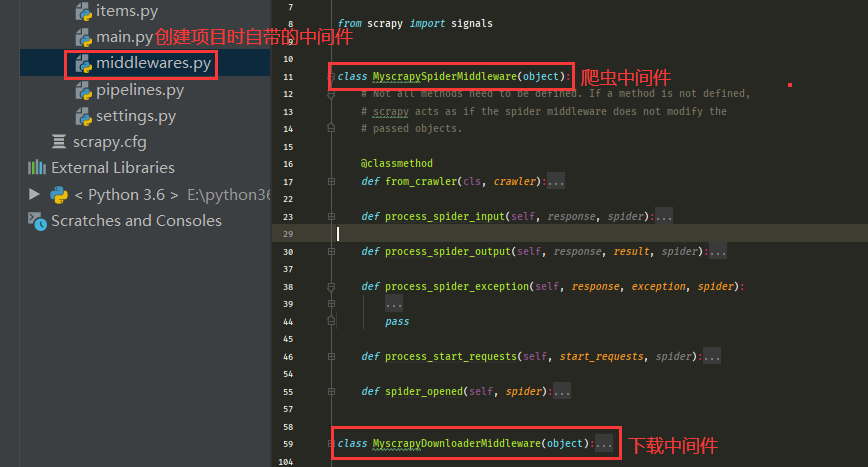
解析:
class DownMiddleware1(object):
def process_request(self, request, spider):
"""
请求需要被下载时,经过所有下载器中间件的process_request调用
:param request:
:param spider:
:return:
None,继续后续中间件去下载;
Response对象,停止process_request的执行,开始执行process_response
Request对象,停止中间件的执行,将Request重新调度器
raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception
"""
pass ```
def process_response(self, request, response, spider):
"""
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return:
Response 对象:转交给其他中间件process_response
Request 对象:停止中间件,request会被重新调度下载
raise IgnoreRequest 异常:调用Request.errback
"""
print('response1')
return response def process_exception(self, request, exception, spider):
"""
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常
:param response:
:param exception:
:param spider:
:return:
None:继续交给后续中间件处理异常;
Response对象:停止后续process_exception方法
Request对象:停止中间件,request将会被重新调用下载
"""
return None
```
下载器中间件
方法的使用
# 下载中间件
-使用cookie
-使用代理池
-集成selenium
-使用:
-写一个类:MyscrapyDownloaderMiddleware
-process_request
加代理,加cookie,集成selenium。。。。
return None,Response,Resquest
-process_response
-在setting中配置 -
DOWNLOADER_MIDDLEWARES = {
'myscrapy.middlewares.MyscrapyDownloaderMiddleware': 543,
}
from scrapy.http.response.html import HtmlResponse
#自己写
class MyscrapyDownloaderMiddleware(object):
@classmethod
def from_crawler(cls, crawler):
s = cls()
return s def process_request(self, request, spider): print('来了')
print(request.url)
#headers可以改
print(request.headers)
#从cookie池中取出cookie赋值进去
print(request.cookies)
#使用代理
# request.meta['download_timeout'] = 20
# request.meta["proxy"] = 'http://192.168.1.1:7878'
# print(request)
# print(spider)
# 返回值:None,Request对象,Response对象
#None 继续走下一个下载中间件
#Response 直接返回,进入spider中做解析
#Request 回到调度器,重新被调度
#可以使用selenium
return HtmlResponse(url="www.baidu.com", status=200, body=b'sdfasdfasfdasdfasf') def process_response(self, request, response, spider):
print('走了')
print(request)
print(spider)
print(type(response))
return response def process_exception(self, request, exception, spider):
print('代理%s,访问%s出现异常:%s' % (request.meta['proxy'], request.url, exception))
import time
time.sleep(5)
#删除代理
# delete_proxy(request.meta['proxy'].split("//")[-1])
#重新获取代理,放进去
# request.meta['proxy'] = 'http://' + get_proxy()
#return request 会放到调度器重新调度
return request def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
Spider Middleware
作用:Spider中间件是在引擎及Spider的特定钩子,处理spider的输入(response)和输出(item及requests).
爬虫中间件的方法介绍,内部封装以及实现的方法。
# 爬虫中间件
-写一个类MyscrapySpiderMiddleware
-写一堆方法
-在setting中配置
SPIDER_MIDDLEWARES = {
'myscrapy.middlewares.MyscrapySpiderMiddleware': 543,
}
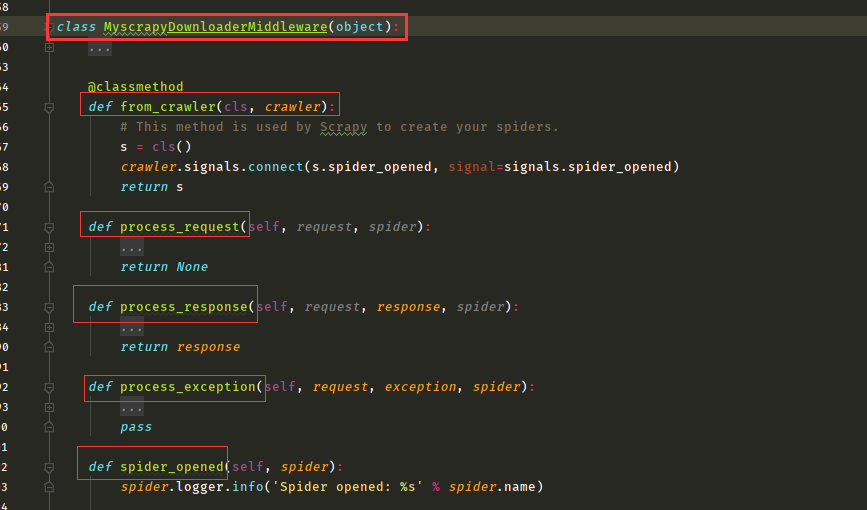
解析使用:控制item和
#自己写爬虫中间件
class MyscrapySpiderMiddleware(object): @classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s def process_spider_input(self, response, spider):
print('我进爬虫的解析')
return None def process_spider_output(self, response, result, spider):
print("我往外走")
for i in result:
yield i def process_spider_exception(self, response, exception, spider): pass def process_start_requests(self, start_requests, spider):
print("process_start_requests")
for r in start_requests:
yield r def spider_opened(self, spider):
print("spider_opened")
spider.logger.info('Spider opened: %s' % spider.name)
信号和配置信息
# 自定义扩展(与django的信号类似)
1、django的信号是django是预留的扩展,信号一旦被触发,相应的功能就会执行
2、scrapy自定义扩展的好处是可以在任意我们想要的位置添加功能,而其他组件中提供的功能只能在规定的位置执
#1、在与settings同级目录下新建一个文件,文件名可以为extentions.py,内容如下
from scrapy import signals class MyExtension(object):
def __init__(self, value):
self.value = value ```
@classmethod
def from_crawler(cls, crawler):
val = crawler.settings.getint('MMMM')
obj = cls(val) crawler.signals.connect(obj.spider_opened, signal=signals.spider_opened)
crawler.signals.connect(obj.spider_closed, signal=signals.spider_closed) return obj def spider_opened(self, spider):
print('=============>open') def spider_closed(self, spider):
print('=============>close') ``` #2、配置生效
EXTENSIONS = {
"Amazon.extentions.MyExtension":200
}

小结:
# 信号
-写一个类:class MyExtension(object):
-在from_crawler绑定一些信号
-当scrapy执行到信号执行点的时候,会自动触发这些函数
-在setting中配置
EXTENSIONS = {
'extentions.MyExtension': 100,
}
settings配置
#==>第一部分:基本配置<===
#1、项目名称,默认的USER_AGENT由它来构成,也作为日志记录的日志名
BOT_NAME = 'Amazon' #2、爬虫应用路径
SPIDER_MODULES = ['Amazon.spiders']
NEWSPIDER_MODULE = 'Amazon.spiders' #3、客户端User-Agent请求头
#USER_AGENT = 'Amazon (+http://www.yourdomain.com)' #4、是否遵循爬虫协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False #5、是否支持cookie,cookiejar进行操作cookie,默认开启
#COOKIES_ENABLED = False #6、Telnet用于查看当前爬虫的信息,操作爬虫等...使用telnet ip port ,然后通过命令操作
#TELNETCONSOLE_ENABLED = False
#TELNETCONSOLE_HOST = '127.0.0.1'
#TELNETCONSOLE_PORT = [6023,] #7、Scrapy发送HTTP请求默认使用的请求头
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} #===>第二部分:并发与延迟<===
#1、下载器总共最大处理的并发请求数,默认值16
#CONCURRENT_REQUESTS = 32 #2、每个域名能够被执行的最大并发请求数目,默认值8
#CONCURRENT_REQUESTS_PER_DOMAIN = 16 #3、能够被单个IP处理的并发请求数,默认值0,代表无限制,需要注意两点
#I、如果不为零,那CONCURRENT_REQUESTS_PER_DOMAIN将被忽略,即并发数的限制是按照每个IP来计算,而不是每个域名
#II、该设置也影响DOWNLOAD_DELAY,如果该值不为零,那么DOWNLOAD_DELAY下载延迟是限制每个IP而不是每个域
#CONCURRENT_REQUESTS_PER_IP = 16 #4、如果没有开启智能限速,这个值就代表一个规定死的值,代表对同一网址延迟请求的秒数
#DOWNLOAD_DELAY = 3 #===>第三部分:智能限速/自动节流:AutoThrottle extension<===
#一:介绍
from scrapy.contrib.throttle import AutoThrottle #http://scrapy.readthedocs.io/en/latest/topics/autothrottle.html#topics-autothrottle
设置目标:
1、比使用默认的下载延迟对站点更好
2、自动调整scrapy到最佳的爬取速度,所以用户无需自己调整下载延迟到最佳状态。用户只需要定义允许最大并发的请求,剩下的事情由该扩展组件自动完成 #二:如何实现?
在Scrapy中,下载延迟是通过计算建立TCP连接到接收到HTTP包头(header)之间的时间来测量的。
注意,由于Scrapy可能在忙着处理spider的回调函数或者无法下载,因此在合作的多任务环境下准确测量这些延迟是十分苦难的。 不过,这些延迟仍然是对Scrapy(甚至是服务器)繁忙程度的合理测量,而这扩展就是以此为前提进行编写的。 #三:限速算法
自动限速算法基于以下规则调整下载延迟
#1、spiders开始时的下载延迟是基于AUTOTHROTTLE_START_DELAY的值
#2、当收到一个response,对目标站点的下载延迟=收到响应的延迟时间/AUTOTHROTTLE_TARGET_CONCURRENCY
#3、下一次请求的下载延迟就被设置成:对目标站点下载延迟时间和过去的下载延迟时间的平均值
#4、没有达到200个response则不允许降低延迟
#5、下载延迟不能变的比DOWNLOAD_DELAY更低或者比AUTOTHROTTLE_MAX_DELAY更高 #四:配置使用
#开启True,默认False
AUTOTHROTTLE_ENABLED = True
#起始的延迟
AUTOTHROTTLE_START_DELAY = 5
#最小延迟
DOWNLOAD_DELAY = 3
#最大延迟
AUTOTHROTTLE_MAX_DELAY = 10
#每秒并发请求数的平均值,不能高于 CONCURRENT_REQUESTS_PER_DOMAIN或CONCURRENT_REQUESTS_PER_IP,调高了则吞吐量增大强奸目标站点,调低了则对目标站点更加”礼貌“
#每个特定的时间点,scrapy并发请求的数目都可能高于或低于该值,这是爬虫视图达到的建议值而不是硬限制
AUTOTHROTTLE_TARGET_CONCURRENCY = 16.0
#调试
AUTOTHROTTLE_DEBUG = True
CONCURRENT_REQUESTS_PER_DOMAIN = 16
CONCURRENT_REQUESTS_PER_IP = 16 #===>第四部分:爬取深度与爬取方式<===
#1、爬虫允许的最大深度,可以通过meta查看当前深度;0表示无深度
# DEPTH_LIMIT = 3 #2、爬取时,0表示深度优先Lifo(默认);1表示广度优先FiFo # 后进先出,深度优先
# DEPTH_PRIORITY = 0
# SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleLifoDiskQueue'
# SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.LifoMemoryQueue'
# 先进先出,广度优先 # DEPTH_PRIORITY = 1
# SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
# SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue' #3、调度器队列
# SCHEDULER = 'scrapy.core.scheduler.Scheduler'
# from scrapy.core.scheduler import Scheduler #4、访问URL去重
# DUPEFILTER_CLASS = 'step8_king.duplication.RepeatUrl' #===>第五部分:中间件、Pipelines、扩展<===
#1、Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'Amazon.middlewares.AmazonSpiderMiddleware': 543,
#} #2、Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
# 'Amazon.middlewares.DownMiddleware1': 543,
} #3、Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} #4、Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# 'Amazon.pipelines.CustomPipeline': 200,
} #===>第六部分:缓存<===
""" 1. 启用缓存
目的用于将已经发送的请求或相应缓存下来,以便以后使用 from scrapy.downloadermiddlewares.httpcache import HttpCacheMiddleware
from scrapy.extensions.httpcache import DummyPolicy
from scrapy.extensions.httpcache import FilesystemCacheStorage
"""
# 是否启用缓存策略
# HTTPCACHE_ENABLED = True # 缓存策略:所有请求均缓存,下次在请求直接访问原来的缓存即可
# HTTPCACHE_POLICY = "scrapy.extensions.httpcache.DummyPolicy"
# 缓存策略:根据Http响应头:Cache-Control、Last-Modified 等进行缓存的策略
# HTTPCACHE_POLICY = "scrapy.extensions.httpcache.RFC2616Policy" # 缓存超时时间
# HTTPCACHE_EXPIRATION_SECS = 0 # 缓存保存路径
# HTTPCACHE_DIR = 'httpcache' # 缓存忽略的Http状态码
# HTTPCACHE_IGNORE_HTTP_CODES = [] # 缓存存储的插件
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' #===>第七部分:线程池<===
REACTOR_THREADPOOL_MAXSIZE = 10 #Default: 10
#scrapy基于twisted异步IO框架,downloader是多线程的,线程数是Twisted线程池的默认大小(The maximum limit for Twisted Reactor thread pool size.) #关于twisted线程池:
http://twistedmatrix.com/documents/10.1.0/core/howto/threading.html #线程池实现:twisted.python.threadpool.ThreadPool
twisted调整线程池大小:
from twisted.internet import reactor
reactor.suggestThreadPoolSize(30) #scrapy相关源码:
D:\python3.6\Lib\site-packages\scrapy\crawler.py #补充:
windows下查看进程内线程数的工具:
https://docs.microsoft.com/zh-cn/sysinternals/downloads/pslist
或
https://pan.baidu.com/s/1jJ0pMaM ```
命令为:
pslist |findstr python ``` linux下:top -p 进程id #===>第八部分:其他默认配置参考<===
D:\python3.6\Lib\site-packages\scrapy\settings\default_settings.py
复制代码
分布式爬虫-scrapy-redis
什么是分布式爬虫?
1、分布式爬虫就是将可以在多台电脑上运行,这样可以提高爬虫速度和效率
2、普通的爬虫是将起始任务定义在本机的爬虫文件中,分布式是将起始任务定义在远端服务器上,可以同时多台电脑去取任务,进行爬取
原来scrapy的Scheduler维护的是本机的任务队列(存放Request对象及其回调函数等信息)+本机的去重队列(存放访问过的url地址)
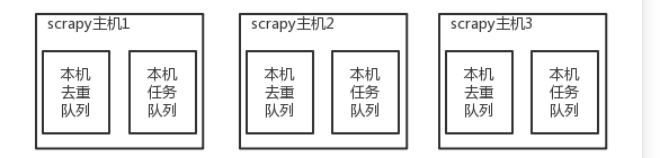
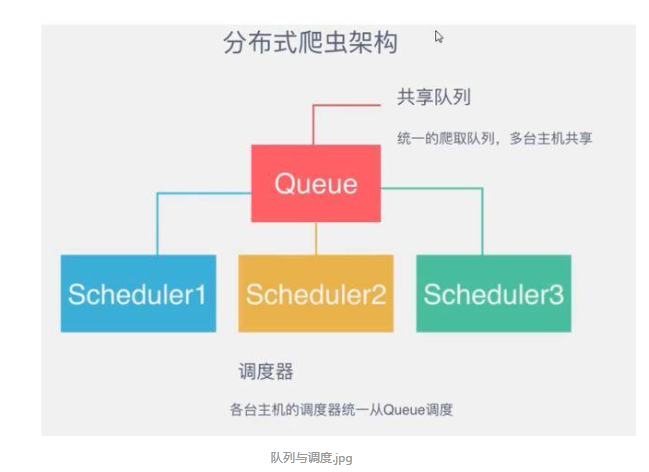
所以实现分布式爬取的关键就是,找一台专门的主机上运行一个共享的队列比如Redis,
然后重写Scrapy的Scheduler,让新的Scheduler到共享队列存取Request,并且去除重复的Request请求,所以总结下来,实现分布式的关键就是三点:
#1、共享队列
#2、重写Scheduler,让其无论是去重还是任务都去访问共享队列
#3、为Scheduler定制去重规则(利用redis的集合类型)
使用:
#安装:
pip3 install scrapy-redis #源码:
D:\python3.6\Lib\site-packages\scrapy_redis
用法:
GitHub提供
在您的项目中使用以下设置: #启用redis调度存储请求队列。
SCHEDULER = “ scrapy_redis.scheduler.Scheduler ” #确保所有蜘蛛通过redis共享相同的重复筛选器。
DUPEFILTER_CLASS = “ scrapy_redis.dupefilter.RFPDupeFilter ” #默认请求串行是泡菜,但它可以改变任何模块
#与负载和转储功能。需要注意的是咸菜不相互兼容
# Python版本。
#警告:在python 3.x中,序列化程序必须返回字符串键并支持
#个字节作为值。也因为这个原因的JSON或msgpack模块不会
#默认工作。在python 2.x中没有这样的问题,您可以使用
# 'json'或'msgpack'作为序列化程序。
# SCHEDULER_SERIALIZER = “scrapy_redis.picklecompat” #不清理redis队列,允许暂停/恢复爬网。
# SCHEDULER_PERSIST = TRUE #使用优先级队列调度请求。(默认)
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' #备用队列。
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue'
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue' #最大空闲时间,以防止在进行分布式爬网时关闭蜘蛛网。
#仅当队列类为SpiderQueue或SpiderStack时,此方法才有效。
#并可能在第一次启动Spider时阻止同一时间(因为队列为空)。
# SCHEDULER_IDLE_BEFORE_CLOSE = 10 #将抓取的项目存储在Redis中以进行后期处理。
ITEM_PIPELINES = {
' scrapy_redis.pipelines.RedisPipeline ': 300
} #项目管道对项目进行序列化并将其存储在此Redis密钥中。
# REDIS_ITEMS_KEY ='%(蜘蛛)S:项的 #默认情况下,项目序列化器为ScrapyJSONEncoder。您可以使用任何
#可导入路径到可调用对象。
# REDIS_ITEMS_SERIALIZER = 'json.dumps' #指定连接Redis时使用的主机和端口(可选)。
# REDIS_HOST = '本地主机'
# REDIS_PORT = 6379 #指定完整的Redis连接URL(可选)。
#如果设置,它将优先于REDIS_HOST和REDIS_PORT设置。
# REDIS_URL = '的Redis://用户:通过@主机名:9001' #定制Redis的客户参数(即:套接字超时等)
# REDIS_PARAMS = {}
#使用自定义Redis的客户端类。
# REDIS_PARAMS [ 'redis_cls'] = 'myproject.RedisClient' #如果为True,它将使用redis的``SPOP''操作。您必须使用``SADD``
#命令将URL添加到
Redis 队列中。如果您#要避免起始网址列表中出现重复项并且
#处理
的顺序无关紧要,这可能会很有用。# REDIS_START_URLS_AS_SET =假 #默认启动网址RedisSpider和RedisCrawlSpider关键。
# REDIS_START_URLS_KEY = '%(名)S:start_urls' #使用utf-8以外的其他编码进行redis。
# REDIS_ENCODING = 'latin1的'
注意 0.3版将请求序列化从更改marshal为cPickle,因此使用0.2版保留的请求将无法在0.3版上使用。 运行示例项目
此示例说明了如何在多个蜘蛛实例之间共享蜘蛛的请求队列,非常适合广泛的爬网。 在您的PYTHONPATH中设置scrapy_redis软件包 首次运行搜寻器,然后停止它: $ cd example-project
$ scrapy crawl dmoz
... [dmoz] ...
^ C
再次运行搜寻器以恢复停止的搜寻: $ scrapy crawl dmoz
... [dmoz]调试:恢复抓取(已安排9019个请求)
启动一个或多个其他抓取抓取工具: $ scrapy crawl dmoz
... [dmoz]调试:恢复抓取(已安排8712个请求)
启动一个或多个后处理工人: $ python process_items.py dmoz:items -v
...
处理:Kilani Giftware(http://www.dmoz.org/Computers/Shopping/Gifts/)
处理:NinjaGizmos.com(http://www.dmoz.org/Computers/Shopping/Gifts/)
...
主要配置三个:
# SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
I# TEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
代码:
import scrapy from scrapy_redis.spiders import RedisSpider
from scrapy import Request
class CnblogsSpider(RedisSpider):
name = 'cnblogs'
allowed_domains = ['www.cnblogs.com']
redis_key = 'cnblogs:start_urls' def parse_detail(self,response):
print(len(response.text))
def parse(self, response):
div_list=response.css('.post_item')
for div in div_list:
url=div.css('.post_item_body a::attr(href)').extract_first()
article_name=div.css('.titlelnk::text').extract_first()
auther_name=div.css('.post_item_foot a::text').extract_first()
commit_count=div.css('.post_item_foot span a::text').extract_first()
yield Request(url,callback=self.parse_detail) next_url=response.css('.pager a:last-child::attr(href)').extract_first()
#dont_filter=True 表示不去重,默认去重
print(next_url)
yield Request('https://www.cnblogs.com'+next_url)
小结:
分布式爬虫scrapy-redis
-pip3 install scrapy-redis
-在setting中配置:
-调度器:使用scrapy-redis提供的调度器
-去重规则:使用scrapy-redis提供的去重规则
-可选:
-pipelines配置成scrapy-redis提供的持久化类
-在爬虫类中:
-继承RedisSpider
-把start_url去掉
-新增:redis_key = 'cnblogs:start_urls' -lpush cnblogs:start_urls https://www.cnblogs.com 在redis终端插入url即可运行获取爬虫结果。
源码分析
# -connection.py redis的连接
-defaults.py 配置文件
-dupefilter.py 去重规则
-picklecompat.py 序列化相关
-pipelines.py 持久化
-queue.py 队列
-scheduler.py 调度器
-spiders.py 爬虫相关
-utils.py py2和py3兼容的
内部源码封装实现的方法

scrapy补充-分布式爬虫的更多相关文章
- Scrapy 框架 分布式 爬虫
分布式 爬虫 scrapy-redis 实现 原生scrapy 无法实现 分布式 调度器和管道无法被分布式机群共享 环境安装 - pip install scrapy_redis 导包:from sc ...
- scrapy进行分布式爬虫
今天,参照崔庆才老师的爬虫实战课程,实践了一下分布式爬虫,并没有之前想象的那么神秘,其实非常的简单,相信你看过这篇文章后,不出一小时,便可以动手完成一个分布式爬虫! 1.分布式爬虫原理 首先我们来看一 ...
- 16 Scrapy之分布式爬虫
redis分布式部署 1.scrapy框架是否可以自己实现分布式? - 不可以.原因有二. 其一:因为多台机器上部署的scrapy会各自拥有各自的调度器,这样就使得多台机器无法分配start_urls ...
- scrapy简单分布式爬虫
经过一段时间的折腾,终于整明白scrapy分布式是怎么个搞法了,特记录一点心得. 虽然scrapy能做的事情很多,但是要做到大规模的分布式应用则捉襟见肘.有能人改变了scrapy的队列调度,将起始的网 ...
- 基于scrapy的分布式爬虫抓取新浪微博个人信息和微博内容存入MySQL
为了学习机器学习深度学习和文本挖掘方面的知识,需要获取一定的数据,新浪微博的大量数据可以作为此次研究历程的对象 一.环境准备 python 2.7 scrapy框架的部署(可以查看上一篇博客的简 ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 四十四 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
1.elasticsearch(搜索引擎)的查询 elasticsearch是功能非常强大的搜索引擎,使用它的目的就是为了快速的查询到需要的数据 查询分类: 基本查询:使用elasticsearch内 ...
- python爬虫--分布式爬虫
Scrapy-Redis分布式爬虫 介绍 scrapy-redis巧妙的利用redis 实现 request queue和 items queue,利用redis的set实现request的去重,将s ...
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
随机推荐
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 字体图标(Glyphicons):glyphicon glyphicon-indent-right
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name ...
- ubuntu在虚拟机下的安装 ~~~ Hadoop的安装及配置 ~~~ Hdfs中eclipse的安装
前言 Hadoop是基于Java语言开发的,具有很好跨平台的特性.Hadoop的所要求系统环境适用于Windows,Linux,Mac系统,我们推荐选择使用Linux或Mac系统.而Linux系统则 ...
- UVA - 10954 Add All (全部相加)(Huffman编码 + 优先队列)
题意:有n(n <= 5000)个数的集合S,每次可以从S中删除两个数,然后把它们的和放回集合,直到剩下一个数.每次操作的开销等于删除的两个数之和,求最小总开销.所有数均小于10^5. 分析:按 ...
- 在MFC做DLL动态链接库时,使用boost,出现断言错误
建立的MFC DLL工程中有使用boost::thread,就会发生compile正常但是一程式执行或者直接编辑就出現ASSERT错误. 错误位置:dllinit.cpp,Line: 587,ASSE ...
- C++基础--引用的一点补充
这一篇是对引用的一点补充,内容基本上是来自<C++ primer plus>一书第八章的内容. 前面一篇介绍了引用的一点特点,这里补充一个,将引用用于类对象的时候,有一个体现继承的特征,就 ...
- maven项目中WEB-INF的父目录必须叫webapp吗?
这个并不是必须的,可以在pom配置文件中修改,如下所示: <webappDirectory>src/main/WebContent</webappDirectory> ...
- 五、CI框架之通过带路径的view视图路径访问
一.如果需要现在的某个目录的View界面,需要在controller中写入文件路径 二.访问http://127.0.0.1/CodeIgniter-3.1.10/index.php/显示如下: 不忘 ...
- javascript实现抽奖程序
昨天开年会的时候看到一个段子说唯品会年会抽奖,结果大奖都被写抽奖程序的部门得了,CTO现场review代码. 简单想了一下抽奖程序的实现,花了十几分钟写了一下,主要用到的知识有数组添加删除,以及ES5 ...
- .NET Core开发实战(第11课:文件配置提供程序)--学习笔记
11 | 文件配置提供程序:自由选择配置的格式 文件配置提供程序 Microsoft.Extensions.Configuration.Ini Microsoft.Extensions.Configu ...
- 洛谷 P2196 挖地雷
题目传送门 解题思路: 记忆化搜索,题目比较坑的地方在于,这是个有向图,给的边是单向边!!!!!!!! AC代码: #include<iostream> #include<cstdi ...