潭州课堂25班:Ph201805201 爬虫高级 第五课 sclapy 框架 日志和 settings 配置 模拟登录(课堂笔记)





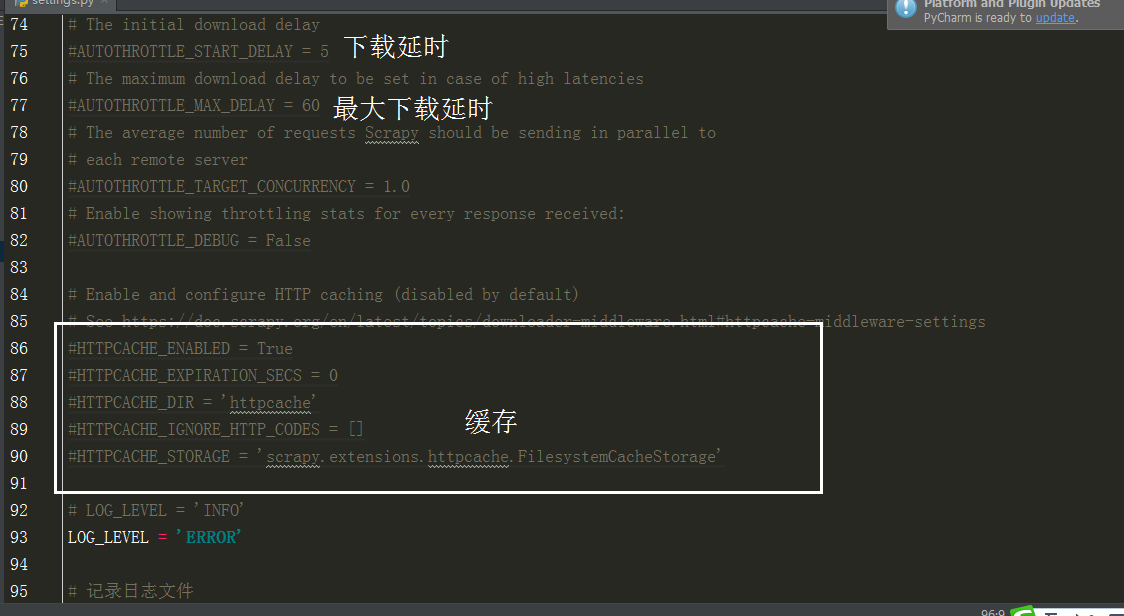
当要对一个页面进行多次请求时,
设 dont_filter = True 忽略去重
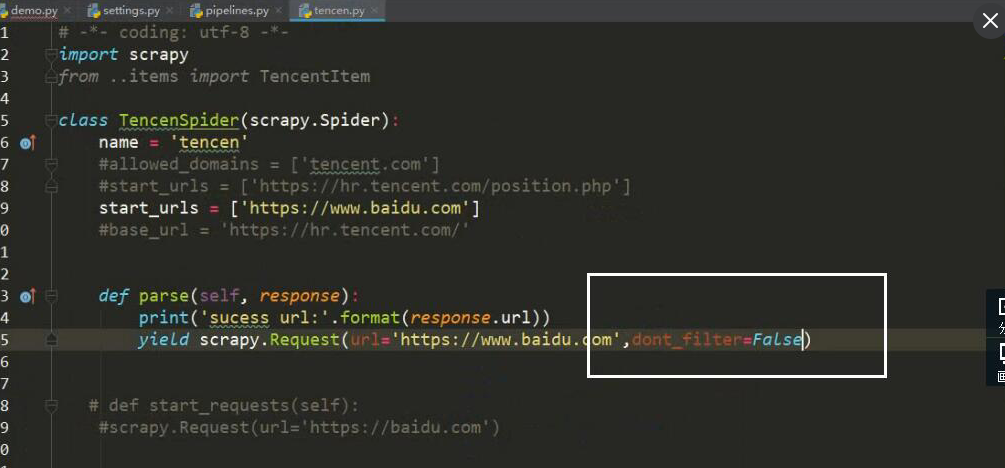
在 scrapy 框架中模拟登录
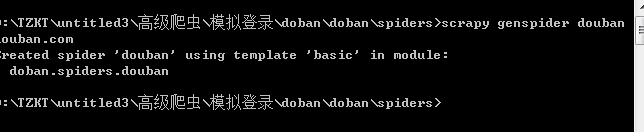
创建项目

创建运行文件
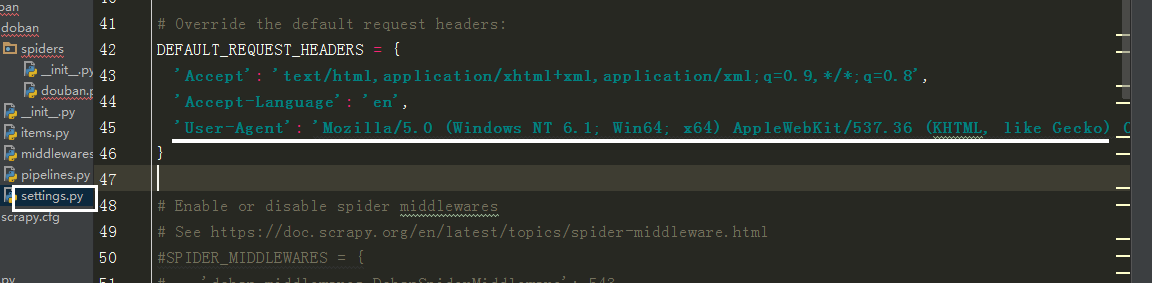
设请求头
# -*- coding: utf-8 -*-
import scrapy
import requests class DoubanSpider(scrapy.Spider):
name = 'douban'
# allowed_domains = ['douban.com']
# 登录页面
start_urls = ['https://accounts.douban.com/login']
log_url = 'https://accounts.douban.com/login'
c_g_url = 'https://www.douban.com/'
def parse(self, response):
# 如果出现验证码
# 验证码
captcha_url = response.xpath('//img[@id="captcha_image"]/@src').extract_first()
# 如果没有验证码
if not captcha_url:
print('没有验证码')
data = {
'source': 'index_nav',
'redir':'https://www.douban.com/people/184159212/',
'form_email': '13605938437',
'form_password': '17906808lmlmlm',
'login':'登录'
}
else:
print('出现验证码')
captcha_id = response.xpath('//input[@name="captcha-id"]/@value').extract_first()
# 下载图片验证码
with open('1.jpg','wb')as f:
f.write(requests.get(captcha_url).content)
captcha_solution = input('>>>>>')
data = {
'source': 'None',
'redir':'https://www.douban.com/',
'captcha-solution':captcha_solution,
'captcha-id':captcha_id,
'form_email': '账号',
'form_password': '密码',
'login':'登录'
} # 返回url , 参数 , 回调函数
yield scrapy.FormRequest(url=self.log_url,formdata=data,callback=self.login_after) def login_after(self,response):
# 判断是否登录成功
text ={
'ck': '7nL_',
'comment':' 哈哈....哈哈....哈哈....'
}
name = response.xpath('//*[@id="db-global-nav"]/div/div[1]/ul/li[2]/a/span[1]//text()').extract()
if name:
print('登录成功,当前用户是%s'%name)
yield scrapy.FormRequest(url=self.c_g_url,formdata=text)
else:print('登录失败')
潭州课堂25班:Ph201805201 爬虫高级 第五课 sclapy 框架 日志和 settings 配置 模拟登录(课堂笔记)的更多相关文章
- 潭州课堂25班:Ph201805201 爬虫高级 第七课 sclapy 框架 爬前程网 (课堂笔)
定时对该网页数据采集,所以每次只爬第一个页面就可以, 创建工程 scrapy startproject qianchen 创建运行文件 cd qianchenscrapy genspider qian ...
- 潭州课堂25班:Ph201805201 爬虫高级 第六课 sclapy 框架 中间建 与selenium对接 (课堂笔记)
因为每次请求得到的响应不一定是正常的, 也可以在中间建中与个类的方法,自动更换头自信,代理Ip, 在设置文件中添加头信息列表, 在中间建中导入刚刚的列表,和随机函数 class UserAgent ...
- 潭州课堂25班:Ph201805201 爬虫高级 第四课 sclapy 框架 crawispider类 (课堂笔记)
以上内容以 spider 类 获取 start_urls 里面的网页 在这里平时只写一个,是个入口,之后 通过 xpath 生成 url,继续请求, crawispider 中 多了个 rules ...
- 潭州课堂25班:Ph201805201 爬虫高级 第三课 sclapy 框架 腾讯 招聘案例 (课堂笔记)
到指定目录下,创建个项目 进到 spiders 目录 创建执行文件,并命名 运行调试 执行代码,: # -*- coding: utf-8 -*- import scrapy from ..items ...
- 潭州课堂25班:Ph201805201 爬虫高级 第十三 课 代理池爬虫检测部分 (课堂笔记)
1,通过爬虫获取代理 ip ,要从多个网站获取,每个网站的前几页2,获取到代理后,开进程,一个继续解析,一个检测代理是否有用 ,引入队列数据共享3,Queue 中存放的是所有的代理,我们要分离出可用的 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第十一课 Scrapy-redis分布 项目实战 (课堂笔
- 潭州课堂25班:Ph201805201 爬虫高级 第十课 Scrapy-redis分布 (课堂笔记)
利用 redis 数据库,做 request 队列,去重,多台数据共享, scrapy 调度 基于文件每户,默认只能在单机运行, scrapy-redis 默认把数据放到 redis 中,实现数据共享 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第八课 AP抓包 SCRAPY 的图片处理 (课堂笔记)
装好模拟器设置代理到 Fiddler 中, 代理 IP 是本机 IP, 端口是 8888, 抓包 APP斗鱼 用 format 设置翻页
- 潭州课堂25班:Ph201805201 爬虫基础 第五课 (案例) 豆瓣分析 (课堂笔记)
动态讲求 , 翻页参数: # -*- coding: utf-8 -*- # 斌彬电脑 # @Time : 2018/9/1 0001 3:44 import requests,json class ...
随机推荐
- IAR拷贝工程后,修改工程名的方法
在实际使用过程中,经常基于某个demo进行开发,但是demo的项目名往往不满足新项目的名称,如果重新建立工程,就需要进行一系列的配置,非常麻烦,其实可以直接修改项目名,做法如下; 1. 修改项目目录下 ...
- 身份证号校验原理及JavaScript实现
在网站中,总有各种各样的表单,用户使用表单来向服务器发送数据,进行交互. 然而,代代相传的经验是,永远不要信任用户的输入,一定要对数据进行验证.如果使用不经验证的表单,轻则会有大量无效提交 ...
- 提高CPU使用率100%
直接上脚本: #!/bin/bash while true do echo 2^2^20 | bc & >/dev/null done 查看CPU使用率用top命令即可 释放CPU: p ...
- linux源码Makefile详解(完整)
转自:http://www.cnblogs.com/Daniel-G/p/3286614.html 随着 Linux 操作系统的广泛应用,特别是 Linux 在嵌入式领域的发展,越来越多的人开始投身到 ...
- rabbitmq 源码安装
官网地址:rabbitmqhttp://www.rabbitmq.com/releases/rabbitmq-server/官网地址:erlanghttp://erlang.org/download/ ...
- 转载:小结(1.7)《深入理解Nginx》(陶辉)
原文:https://book.2cto.com/201304/19622.html 本章介绍了Nginx的特点以及在什么场景下需要使用Nginx,同时介绍了如何获取Nginx以及如何配置.编译.安装 ...
- 作业8_exer1128.txt
1.规范化理论是关系数据库进行逻辑设计的理论依据,根据这个理论,关系数据库中的关系必须满足:每 一个属性都是(B). A.长度不变的 B.不可分解的 C.互相关联的 D.互不相关的 2.已知关系模式R ...
- python包管理之Pip安装及使用-1
Python有两个著名的包管理工具easy_install.py和pip.在Python2.7的安装包中,easy_install.py是默认安装的,而pip需要我们手动安装. pip可以运行在Uni ...
- javascript如何从tr中分别获得每个td的元素
<html> <body> <table border="1" id="table1"> <tr id="r ...
- RabbitMQ(三): exchange 的使用
1. Exchange(交换机) 生产者只能发送信息到交换机,交换机接收到生产者的信息,然后按照规则把它推送到对列中. 一方面是接收生产者的消息,另一方面是像队列推送消息. 匿名转发 "&q ...