【转载】 深度强化学习处理cartpole为什么reward很难超过200?
原贴地址:
https://www.zhihu.com/question/266493753
一直在看强化学习方面的内容,cartpole是最简单的入门实验环境,最原始的评判标准是连续100次episode的奖励均值在195以上即可认定是到达最优,说明此问题得以解决,(但是有很多的研究是没有采用这个条件的,也就是按照训练的次数固定,在一定的训练次数后看测试时的奖励均值和方差)。如果我们不按照这个评价标准来运行该环境的话,那么我们需要对gym中的某些原始设定进行修改。
----------------------------------------------------------------------------------------

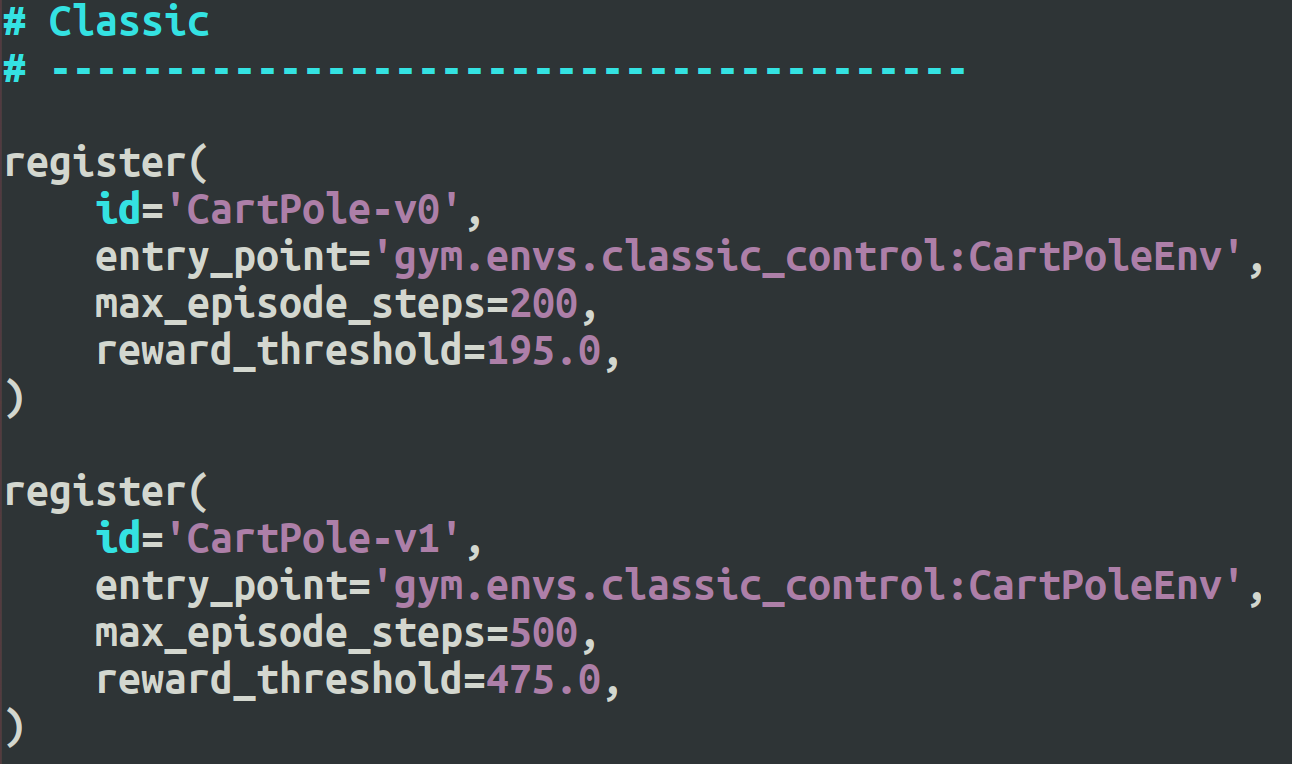
在文件gym/envs/__init__.py 中,限定了max_episode_steps
register(
id='CartPole-v0',
entry_point='gym.envs.classic_control:CartPoleEnv',
max_episode_steps=200,
reward_threshold=195.0,
)
作者:冰璐
链接:https://www.zhihu.com/question/266493753/answer/317795225
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

【转载】 深度强化学习处理cartpole为什么reward很难超过200?的更多相关文章
- 深度强化学习中稀疏奖励问题Sparse Reward
Sparse Reward 推荐资料 <深度强化学习中稀疏奖励问题研究综述>1 李宏毅深度强化学习Sparse Reward4 强化学习算法在被引入深度神经网络后,对大量样本的需求更加 ...
- 【转载】 强化学习(八)价值函数的近似表示与Deep Q-Learning
原文地址: https://www.cnblogs.com/pinard/p/9714655.html ------------------------------------------------ ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 【转载】 强化学习(七)时序差分离线控制算法Q-Learning
原文地址: https://www.cnblogs.com/pinard/p/9669263.html ------------------------------------------------ ...
- 深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird
深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-fu ...
- 强化学习之CartPole
0x00 任务 通过强化学习算法完成倒立摆任务,控制倒立摆在一定范围内摆动. 0x01 设置jupyter登录密码 jupyter notebook --generate-config jupyt ...
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm) 2017-12-25 16:29:19 对于 A3C 算法感觉自己总是一知半解,现将其梳理一下,记录在此,也 ...
- 【转载】 强化学习(五)用时序差分法(TD)求解
原文地址: https://www.cnblogs.com/pinard/p/9529828.html ------------------------------------------------ ...
- 深度强化学习day01初探强化学习
深度强化学习 基本概念 强化学习 强化学习(Reinforcement Learning)是机器学习的一个重要的分支,主要用来解决连续决策的问题.强化学习可以在复杂的.不确定的环境中学习如何实现我们设 ...
随机推荐
- 切换JDK版本时修改JAVA_HOME环境变量不生效(转)
当电脑上存在多个版本的JDK时,可能 会遇到想切换版本时无论你如何改JAVA_HOME的路径 进入cmd java -version 都无法得到最新设置的JDK版本 如果遇到类似以下信息 Regist ...
- git rebase commit 信息处理
pick:正常选中 reword:选中,并且修改提交信息: edit:选中,rebase时会暂停,允许你修改这个commit(参考这里) squash:选中,会将当前commit与上一个commit合 ...
- SpringBoot配置文件的加载位置
1.springboot启动会扫描以下位置的application.properties或者application.yml文件作为SpringBoot的默认配置文件 --file:/config/ - ...
- Redis分布式锁实例
maven依赖 <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</ ...
- JDK自带的keytool证书工具详解
一.生成证书 keytool -genkey -alias tomcat -keyalg RSA -keystore D:/tomcat.keystore -keypass 123456 -store ...
- DDR3和eMMC区别
DDR3内存条和eMMC存储器区别: 1. 存储性质不同:2. 存储容量不同:3. 运行速度不同:4. 用途不同. 具体区别如下: 1.存储性质不同:eMMC是非易失性存储器,不论在通电或断电状态下, ...
- html页面标题增加图标方法
有些网站的网页标题部分有图标,很带感.方法很简单: 在<head></head>部分增加下列一行代码即可. <link rel="shortcut icon&q ...
- 使用Jenkins自动编译 .net 项目
使用Jenkins自动编译我的.net 项目 1.Jenkins是什么? Jenkins是一个可扩展的持续集成的引擎,主要用于持续自动的构建.测试软件项目 监控一些定时执行的任务. 2.安装配 ...
- 深入margin
1.外边距叠加 外边距叠加是指两个垂直外边距相遇时,这两个外边距会合并成一个外边距,就是二变一,关键是叠加后的外边距会取值两个外边距最大的那个: 例子如下:创建A.B两个盒子,A定义一个margin- ...
- java泛型讲解
原文: https://blog.csdn.net/briblue/article/details/76736356 泛型,一个孤独的守门者. 大家可能会有疑问,我为什么叫做泛型是一个守门者.这其实是 ...