Hadoop3集群搭建之——hbase安装及简单操作
折腾了这么久,hbase终于装好了
-------------------------
上篇:
在安装之前,查了一下资料,关于hbase与hadoop兼容性的。
最开始看hadoop的时候,在好像慕课网上看的,hadoop全家桶之间的兼容性问题(以前被java web的各种jar包坑坏了的Java菜鸟,心理有点小阴影),还有特意出的cdh版本(Cloudera 公司出的,每个hadoop的cdh版本,都有对应的其他组件的cdh版本)
然后,感觉就坏了,我装的hadoop 3.0.1是最新出的,hbase的最新版本肯定对应不上啊。
然后我就发现了下面这张,hbase 兼容hadoop的版本图:
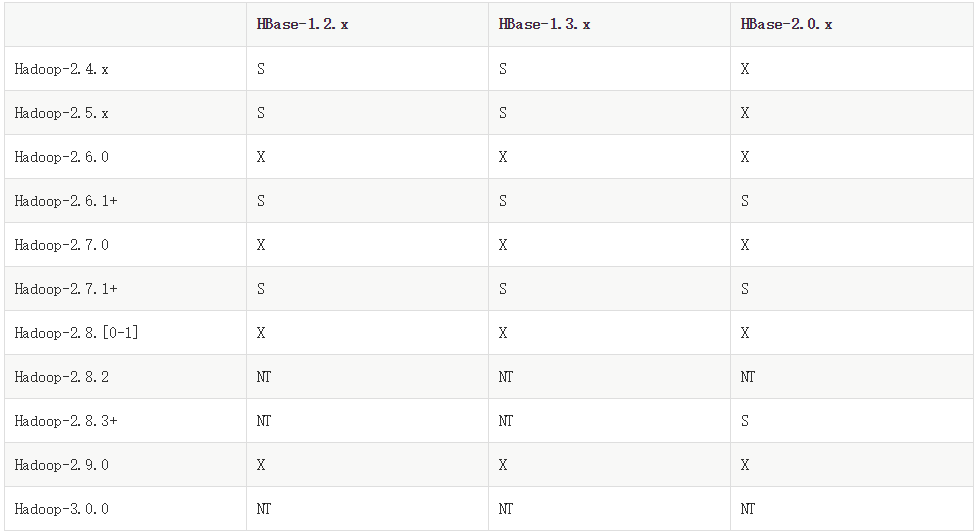
"S" = supported "X" = not supported "NT" = Not tested
果然,hadoop3没有对应的hbase版本
下载最新的hbase2.0.2,查看lib目录发现hadoop 的版本是: 2.7.4
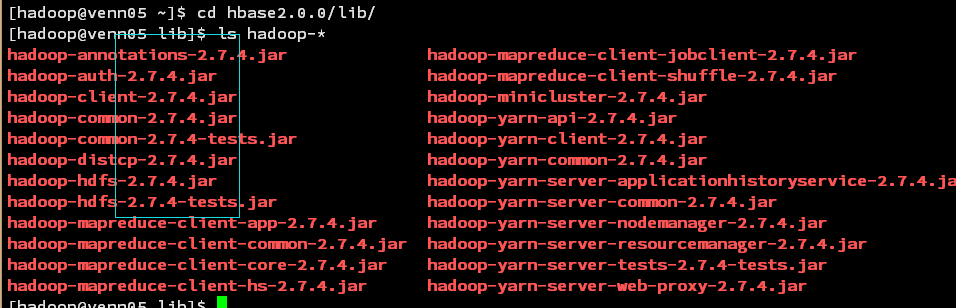
犹豫再三
突然想起,公司大神搭的新平台就是hadoop3,里面也有用到hbase,看下版本,得到如下答案:
hbase-1.2.
what fuck? 看不懂,不过不影响,模仿一下。/偷笑/偷笑
然后就去官网: 下载地址 下个了1.2.6。
安装步骤如下:
1、上传安装包到服务器、解压,重命名:
tar -zxvf hbase-1.2.-bin.tar.gz
mv hbase-1.2.6-bin.tar.gz hbase1.2.6
2、配置hbase环境变量
vi .baserc #添加如下内容
#hbase
HBASE_HOME=/opt/hadoop/hbase1.2.6
export PATH=$HBASE_HOME/bin:$PATH
#使配置文件生效
source .baserc
3、修改 /conf/hbase-env.sh
找到如下两行,关闭注释,修改如下:
export JAVA_HOME=/opt/hadoop/jdk1. #配置jdk路径 #使用hbase自带的zookeeper
export HBASE_MANAGES_ZK=true
4、修改/conf/hbase-site.xml
添加如下内容:
<configuration>
<property>
<name>hbase.rootdir</name> <!-- hbase存放数据目录 -->
<value>hdfs://venn05:8020/hbase/hbase_db</value> <!-- 端口要和Hadoop的fs.defaultFS端口一致-->
</property>
<property>
<name>hbase.cluster.distributed</name> <!-- 是否分布式部署 -->
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name> <!-- zookooper 服务启动的节点,只能为奇数个 -->
<value>venn05,venn06,venn07</value>
</property> <property><!--zookooper配置、日志等的存储位置,必须为以存在 -->
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/hadoop/hbase1.2.6/hbase/zookeeper</value>
</property>
<property><!--hbase web 端口 -->
<name>hbase.master.info.port</name>
<value></value>
</property>
</configuration>
注:zookeeper有这样一个特性:集群中只要有过半的机器是正常工作的,那么整个集群对外就是可用的。
也就是说如果有2个zookeeper,那么只要有1个死了zookeeper就不能用了,因为1没有过半,
所以2个zookeeper的死亡容忍度为0;同理,要是有3个zookeeper,一个死了,还剩下2个正常的,
过半了,所以3个zookeeper的容忍度为1;
同理你多列举几个:->;->;->;->;->2会发现一个规律,2n和2n-1的容忍度是一样的,
都是n-,所以为了更加高效,何必增加那一个不必要的zookeeper
5、配置slaver
修改 regionservers 文件,删除localhost,添加region server 的ip
[hadoop@venn05 conf]$ more regionservers
venn06
venn07
venn08
5、发送.baserc 和hbase到其他节点
scp .bashrc venn06:/opt/hadoop/
scp .bashrc venn07:/opt/hadoop/
scp .bashrc venn08:/opt/hadoop/
scp -r hbase1.2.6 venn06:/opt/hadoop/
scp -r hbase1.2.6 venn07:/opt/hadoop/
scp -r hbase1.2.6 venn08:/opt/hadoop/
配置完成,启动看下效果
hbase 启动命令:
start-all.sh #启动hadoop
start-hbase.sh #会自动启动其他节点
查看主节点进程:
[hadoop@venn05 conf]$ jps
NodeManager
Jps
NameNode
SecondaryNameNode
HMaster
Main
ResourceManager
HQuorumPeer
查看其他节点进程:
[hadoop@venn06 ~]$ jps
HQuorumPeer
HRegionServer
NodeManager
DataNode
Jps
查看web界面:
地址:http://venn05:16010 如下:
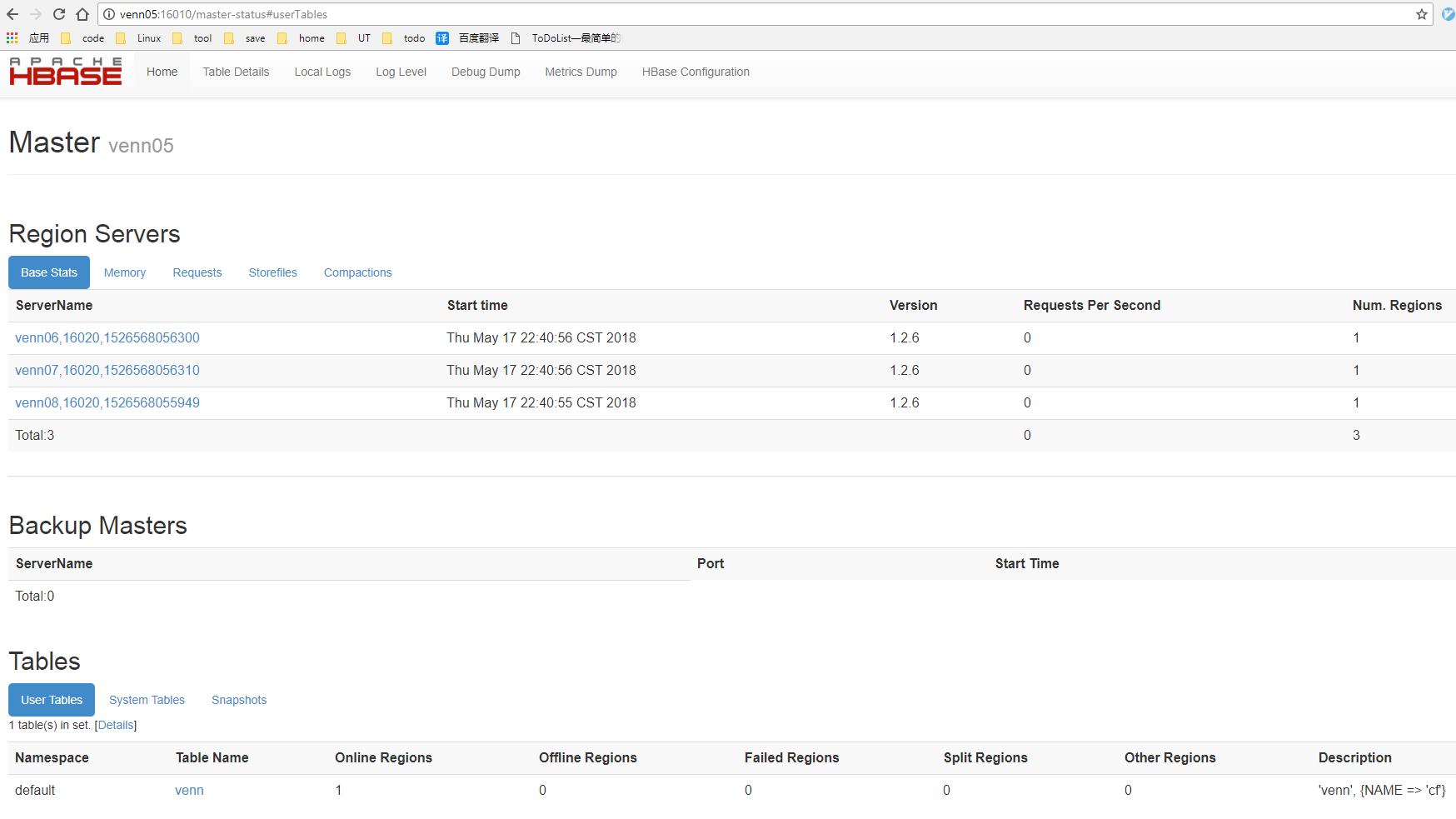
启动成功,尝试一下:
启动hbase 客户端:
[hadoop@venn05 ~]$ hbase shell #启动hbase客户端
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hadoop/hbase1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hive2.3.3/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.2.6, rUnknown, Mon May 29 02:25:32 CDT 2017
hbase(main):001:0> create 'test','cf' #创建一个test表,一个cf 列簇
0 row(s) in 2.4480 seconds
=> Hbase::Table - test
hbase(main):002:0> list #查看hbase 所有表
TABLE
test
venn
2 row(s) in 0.0280 seconds
=> ["test", "venn"]
hbase(main):003:0> put 'test','1000000000','cf:name','venn' #put一条记录到表test,rowkey 为 1000000000,放到 name列上
0 row(s) in 0.1650 seconds
hbase(main):004:0> put 'test','1000000000','cf:sex','male' #put一条记录到表test,rowkey 为 1000000000,放到 sex列上
0 row(s) in 0.0410 seconds
hbase(main):005:0> put 'test','1000000000','cf:age','26' #put一条记录到表test,rowkey 为 1000000000,放到 age列上
0 row(s) in 0.0170 seconds
hbase(main):006:0> count 'test' #查看表test 有多少条数据
1 row(s) in 0.1220 seconds
=> 1
hbase(main):007:0> get 'test','cf'
COLUMN CELL
0 row(s) in 0.0240 seconds
hbase(main):008:0> get 'test','1000000000' #获取数据
COLUMN CELL
cf:age timestamp=1526571007485, value=26
cf:name timestamp=1526571006326, value=venn
cf:sex timestamp=1526571006411, value=male
3 row(s) in 0.0250 seconds
hbase(main):009:0> disable 'test' #禁用表 test
0 row(s) in 2.2670 seconds
hbase(main):010:0> drop 'test' #删除表
0 row(s) in 1.2490 seconds
hbase(main):011:0> list
TABLE
venn
1 row(s) in 0.0100 seconds
=> ["venn"]
搞定,收工
Hadoop3集群搭建之——hbase安装及简单操作的更多相关文章
- Hadoop3集群搭建之——hive安装
Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hbase安装及简单操作 现在到 ...
- Hadoop3集群搭建之——虚拟机安装
现在做的项目是个大数据报表系统,刚开始的时候,负责做Java方面的接口(项目前端为独立的Java web 系统,后端也是Java web的系统,前后端系统通过接口传输数据),后来领导觉得大家需要多元化 ...
- BigData--hadoop集群搭建之hbase安装
之前在hadoop-2.7.3 基础上搭建hbase 详情请见:https://www.cnblogs.com/aronyao/p/hadoop.html 基础条件:先配置完成zookeeper 准备 ...
- Hadoop3集群搭建之——安装hadoop,配置环境
接上篇:Hadoop3集群搭建之——虚拟机安装 下篇:Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hive安装 Hadoop3集群搭建之——hbase安装及简单操作 上篇已 ...
- Hadoop3集群搭建之——hive添加自定义函数UDTF (一行输入,多行输出)
上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hive安装 Hadoo ...
- Hadoop3集群搭建之——hive添加自定义函数UDTF
上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hive安装 Hadoo ...
- Hadoop3集群搭建之——hive添加自定义函数UDF
上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hive安装 Hadoo ...
- Hadoop3集群搭建之——配置ntp服务
上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 下篇: Hadoop3集群搭建之——hive安装 Hadoop3集群搭建之——hbase安装及简 ...
- Hadoop集群搭建-03编译安装hadoop
Hadoop集群搭建-05安装配置YARN Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hado ...
随机推荐
- 通配符(WildCard)的使用
一.关于WildCard:一个web应用,有成千上万个action声明,可以利用struts2提供的映射机制把多个彼此相似的映射关系简化成一个映射关系,即通配符. 1.新建类 ActionWildCa ...
- MyEclipse中把JSP默认编码改为UTF-8
在MyEclispe中创建Jsp页面,Jsp页面的默认编码是“ISO-8859-1”,如下图所示: 在这种编码下编写中文是没有办法保存Jsp页面的,会出现如下的错误提示: 因此可以设置Jsp默认的编码 ...
- C# int可以表示的最大值
C#中int由4个字节组成,即由32个二进制数组成,由于最高位是用于表示正负数,所以实际上int所能表示的最大数为231-1=2147483647.
- 表达式树ExpressionTrees
简介 表达式树以树形数据结构表示代码,其中每一个节点都是一种表达式,比如方法调用和 x < y 这样的二元运算等.你可以对表达式树中的代码进行编辑和运算.这样能够动态修改可执行代码.在不同数据库 ...
- sum of powers
题意: 考虑所有的可重集{a1,a2,a3....ak} 满足a1+a2+....+ak=n,求所有a1^m+a2^m+a3^m的和 n,m,k<=5000 题解: part1: 考虑f[i][ ...
- 082 HBase的几种调优(GC策略,flush,compact,split)
一:GC的调优 1.jvm的内存 新生代:存活时间较短,一般存储刚生成的一些对象 老年代:存活时间较长,主要存储在应用程序中生命周期较长的对象 永久代:一般存储meta和class的信息 2.GC策略 ...
- hdu 6185 递推+【矩阵快速幂】
<题目链接> <转载于 >>> > 题目大意: 让你用1*2规格的地毯去铺4*n规格的地面,告诉你n,问有多少种不同的方案使得地面恰好被铺满且地毯不重叠.答案 ...
- HDU 1025 城市供应 【LIS】
题目链接:https://vjudge.net/contest/228455#problem/A 题目大意: 有2n个城市,其中有n个富有的城市,n个贫穷的城市,其中富有的城市只在一种资源富有,且富有 ...
- Egret 之 消除游戏 开发 PART 6 Egret elimination game development PART 6
Egret 之 消除游戏 开发 PART 6 Egret elimination game development PART 6 作者:韩梦飞沙 Author:han_meng_fei_sha 邮箱: ...
- bzoj3693: 圆桌会议 二分图 hall定理
目录 题目链接 题解 代码 题目链接 bzoj3693: 圆桌会议 题解 对与每个人构建二分,问题化为时候有一个匹配取了所有的人 Hall定理--对于任意的二分图G,G的两个部分为X={x1,x2,- ...