MapReduce计算模型二
之前写过关于Hadoop方面的MapReduce框架的文章MapReduce框架Hadoop应用(一) 介绍了MapReduce的模型和Hadoop下的MapReduce框架,此文章将进一步介绍mapreduce计算模型能用于解决什么问题及有什么巧妙优化。
MapReduce到底解决什么问题?
MapReduce准确的说,它不是一个产品,而是一种解决问题的思路,能够用分治策略来解决问题。例如:网页抓取、日志处理、索引倒排、查询请求汇总等等问题。通过分治法,将一个大规模的问题,分解成多个小规模的问题(分),多个小规模问题解决,再统筹小问题的解(合),就能够解决大规模的问题。最早在单机的体系下计算,当输入数据量巨大的时候,处理很慢。如何能够在短时间内完成处理,很容易想到的思路是,将这些计算分布在成百上千的主机上,但此时,会遇到各种复杂的问题,例如:并发计算、数据分发、错误处理、数据分布、负载均衡、集群管理与通信等,将这些问题综合起来将是比较复杂的问题了,而Google为了方便用户使用系统,提供给了用户很少的接口,去解决复杂的问题。
(1) Map函数接口:处理一个基于key/value(后简称k/v)的数据对(pair)数据集合,同时也输出基于k/v的数据集合。
(2) Reduce函数接口:用来合并Map输出的k/v数据集合
假设我们要统计大量文档中单词出现的次数。
Map
输入K/V:pair(文档名称,文档内容)
输出K/V:pair(单词,1)
Reduce
输入K/V:pair(单词,1)
输出K/V:pair(单词,总计数)
Map伪代码:
Map(list<pair($docName, $docContent)>){//如果有多个Map进程,输入可以是一个pair,不是一个list
foreach(pair in list)
foreach($word in $docContent)
print pair($word, 1); // 输出list<k,v>
}
Reduce伪代码:
Reduce(list<pair($word, $count)>){//大量(word,1)(即使有多个Reduce进程,输入也是list<pair>,因为它的输入是Map的输出)
map<string,int> result;
foreach(pair in list)
if result.isExist($word)
result[$word] += $count;
else
result[$word] = 1;
foreach($keyin result)
print pair($key, result[$key]); //输出list<k,v>
}
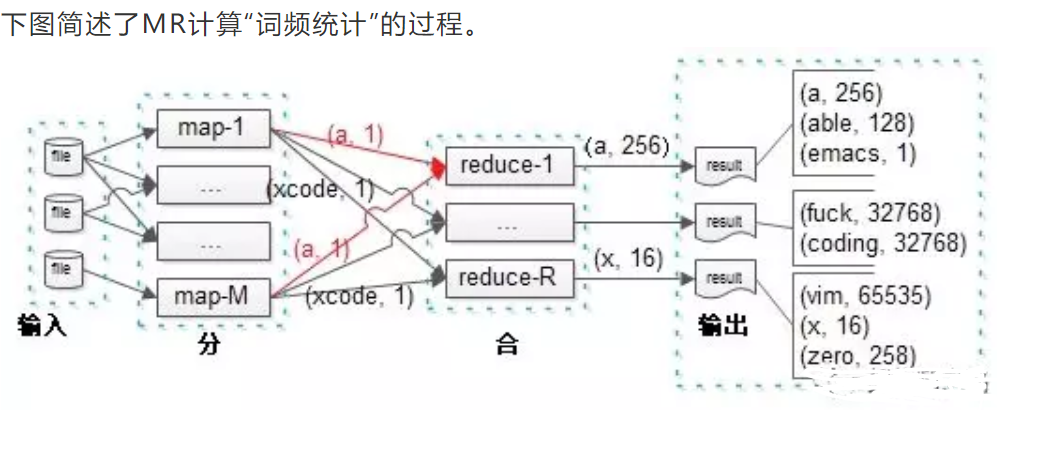
可以看到,R个reduce实例并发进行处理,直接输出最后的计数结果。需要理解的是,由于这是业务计算的最终结果,一个单词的计数不会出现在两个实例里。即:如果(a, 256)出现在了实例1的输出里,就一定不会出现在其他实例的输出里,否则的话,还需要合并,就不是最终结果。
再看中间步骤,map到reduce的过程,M个map实例的输出,会作为R个reduce实例的输入。
问题一:每个map都有可能输出(a, 1),而最终结果(a, 256)必须由一个reduce输出,那如何保证每个map输出的同一个key,落到同一个reduce上去呢?
这就是“分区函数”的作用。分区函数是使用MapReduce的用户按所需实现的,决定map输出的每一个key应当落到哪个reduce上的函数。如果用户没有实现,会使用默认分区函数。为了保证每一个reduce实例都能够差不多时间结束工作任务,分区函数的实现要点是:尽量负载均衡,即数据均匀分摊,防止数据倾斜造成部分reduce节点数据饥饿。如果数据不是负载均衡的,那么有些reduce实例处理的单词多,有些reduce处理的单词少,这样就可能出现所有reduce实例都处理结束,最后等待一个需要长时间处理的reduce情况。
问题二:每个map都有可能输出多个(a, 1),这样就增大了网络带宽资源以及reduce的计算资源,怎么办?
这就是“合并函数”的作用。有时,map产生的中间key的重复数据比重很大,可以提供给用户一个自定义函数,在一个map实例完成工作后,本地就做一次合并,这样将大大节约网络传输与reduce计算资源。合并函数在每个map任务结束前都会执行一次,一般来说,合并函数与reduce函数是一样的,区别是:合并函数是执行map实例本地数据合并,而reduce函数是执行最终的合并,会收集多个map实例的数据。对于词频统计应用,合并函数可以将:一个map实例的多个(a, 1)合并成一个(a, count)输出。
问题三:如何确定文件到map的输入呢?
随意即可,只要负载均衡,均匀切分输入文件大小就行,不用管分到哪个map实例都能正确处理。
问题四:map和reduce可能会产生很多磁盘io,将更适用于离线计算,完成离线作业。
MapReduce计算模型二的更多相关文章
- MapReduce计算模型的优化
MapReduce 计算模型的优化涉及了方方面面的内容,但是主要集中在两个方面:一是计算性能方面的优化:二是I/O操作方面的优化.这其中,又包含六个方面的内容. 1.任务调度 任务调度是Hadoop中 ...
- MapReduce计算模型
MapReduce计算模型 MapReduce两个重要角色:JobTracker和TaskTracker. MapReduce Job 每个任务初始化一个Job,没个Job划分为两个阶段:Map和 ...
- 【CDN+】 Spark入门---Handoop 中的MapReduce计算模型
前言 项目中运用了Spark进行Kafka集群下面的数据消费,本文作为一个Spark入门文章/笔记,介绍下Spark基本概念以及MapReduce模型 Spark的基本概念: 官网: http://s ...
- MapReduce 计算模型
前言 本文讲解Hadoop中的编程及计算模型MapReduce,并将给出在MapReduce模型下编程的基本套路. 模型架构 在Hadoop中,用于执行计算任务(MapReduce任务)的机器有两个角 ...
- 第四篇:MapReduce计算模型
前言 本文讲解Hadoop中的编程及计算模型MapReduce,并将给出在MapReduce模型下编程的基本套路. 模型架构 在Hadoop中,用于执行计算任务(MapReduce任务)的机器有两个角 ...
- 【MapReduce】二、MapReduce编程模型
通过前面的实例,可以基本了解MapReduce对于少量输入数据是如何工作的,但是MapReduce主要用于面向大规模数据集的并行计算.所以,还需要重点了解MapReduce的并行编程模型和运行机制 ...
- 【MapReduce】经常使用计算模型具体解释
前一阵子參加炼数成金的MapReduce培训,培训中的作业样例比較有代表性,用于解释问题再好只是了. 有一本国外的有关MR的教材,比較有用.点此下载. 一.MapReduce应用场景 MR能解决什么问 ...
- 第二步:将LAD结果的属性值二(多)值化,投入计算模型
一文详解LDA主题模型 - 达观数据 - SegmentFault 思否 https://segmentfault.com/a/1190000012215533 SELECT COUNT(1) FRO ...
- 重要 | Spark和MapReduce的对比,不仅仅是计算模型?
[前言:笔者将分上下篇文章进行阐述Spark和MapReduce的对比,首篇侧重于"宏观"上的对比,更多的是笔者总结的针对"相对于MapReduce我们为什么选择Spar ...
随机推荐
- 对flex深入研究一点
flex顶层设计 1.在任何流动的方向上(包括上下左右)都能进行良好的布局 2.可以以逆序 或者 以任意顺序排列布局 3.可以线性的沿着主轴一字排开 或者 沿着侧轴换行排列 4.可以弹性的在任意的容器 ...
- 学习经常遇到的浮动(float)
参考自 小辉随笔: https://www.cnblogs.com/lchsirblog/p/9582989.html 一.什么时候需要使用浮动 最常见的情景是:多个块级元素(如div)需要同一行显示 ...
- JavaScript的几种循环使用方式及性能解析
循环的类型 一:for var arr = [1, 2, 3, 4, 5, 6]; for (var i = 0, len = arr.length; i < len; i++) { conso ...
- React 项目中修改 Ant Design 的默认样式(Input Checkbox 等等
修改样式更符合项目的需求特别是在 Input 和 Checkbox 等等一系列 试过很的方式都有问题, 比如直接在行内添加样式会无法传递到特定的层级 最好的办法是添加 id 可行 渲染部分代码 < ...
- Java数据结构之排序---希尔排序
希尔排序的基本介绍: 希尔排序同之前的插入排序一样,它也是一种插入排序,只不过它是简单插入排序之后的一个优化的排序算法,希尔排序也被称为缩小增量排序. 希尔排序的基本思想: 希尔排序是把数组中给定的元 ...
- c++中的类(构造函数,析构函数的执行顺序)
类对象的初始化顺序 新对象的生成经历初始化阶段(初始化列表显式或者隐式的完成<这部分有点像java里面的初始化块>)——> 构造函数体赋值两个阶段 1,类对象初始化的顺序(对于没有父 ...
- Spring MVC 同一个方法同时返回view或json
https://blog.csdn.net/zzg1229059735/article/details/50854778 @RequestMapping(value = "/htmlorjs ...
- @清晰掉 GNU C __attribute__
__attribute__((packed))详解 1. __attribute__ ((packed)) 的作用就是告诉编译器取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐,是GCC特有 ...
- SQL Server Availability Group Failover 测试
兼容性测试: 测试脚本: 环境:windows failover cluster 主库执行脚本: USE [master]GOALTER AVAILABILITY GROUP [test_AG]MOD ...
- Text Classification
Text Classification For purpose of word embedding extrinsic evaluation, especially downstream task. ...