莫烦PyTorch学习笔记(五)——分类
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
# make fake data
n_data = torch.ones(, )
x0 = torch.normal(*n_data, ) #每个元素(x,y)是从 均值=*n_data中对应位置的取值,标准差为1的正态分布中随机生成的
y0 = torch.zeros() # 给每个元素一个0标签
x1 = torch.normal(-*n_data, ) # 每个元素(x,y)是从 均值=-*n_data中对应位置的取值,标准差为1的正态分布中随机生成的
y1 = torch.ones() # 给每个元素一个1标签
x = torch.cat((x0, x1), ).type(torch.FloatTensor) # shape (, ) FloatTensor = -bit floating
y = torch.cat((y0, y1), ).type(torch.LongTensor) # shape (,) LongTensor = -bit integer
# torch can only train on Variable, so convert them to Variable
x, y = Variable(x), Variable(y) # draw the data
plt.scatter(x.data.numpy()[:, ], x.data.numpy()[:, ], c=y.data.numpy())#c是一个颜色序列 #plt.show()
#神经网络模块
class Net(torch.nn.Module):#继承神经网络模块
def __init__(self,n_features,n_hidden,n_output):#初始化神经网络的超参数
super(Net,self).__init__()#调用父类神经网络模块的初始化方法,上面三行固定步骤,不用深究
self.hidden = torch.nn.Linear(n_features,n_hidden)#指定隐藏层有多少输入,多少输出
self.predict = torch.nn.Linear(n_hidden, n_output)#指定预测层有多少输入,多少输出
def forward(self,x):#搭建神经网络
x = F.relu(self.hidden(x))#积极函数激活加工经过隐藏层的x
x = self.predict(x)#隐藏层的数据经过预测层得到预测结果
return x
net = Net(,,)#声明一个类对象
print(net) plt.ion()#在Plt.ion和plt.ioff之间的代码,交互绘图
plt.show()
#神经网络优化器,主要是为了优化我们的神经网络,使他在我们的训练过程中快起来,节省社交网络训练的时间。
optimizer = torch.optim.SGD(net.parameters(),lr = 0.01)#其实就是神经网络的反向传播,第一个参数是更新权重等参数,第二个对应的是学习率
loss_func = torch.nn.CrossEntropyLoss()#标签误差代价函数 for t in range():
out = net(x)
loss = loss_func(out,y)#计算损失
optimizer.zero_grad()#梯度置零
loss.backward()#反向传播
optimizer.step()#计算结点梯度并优化,
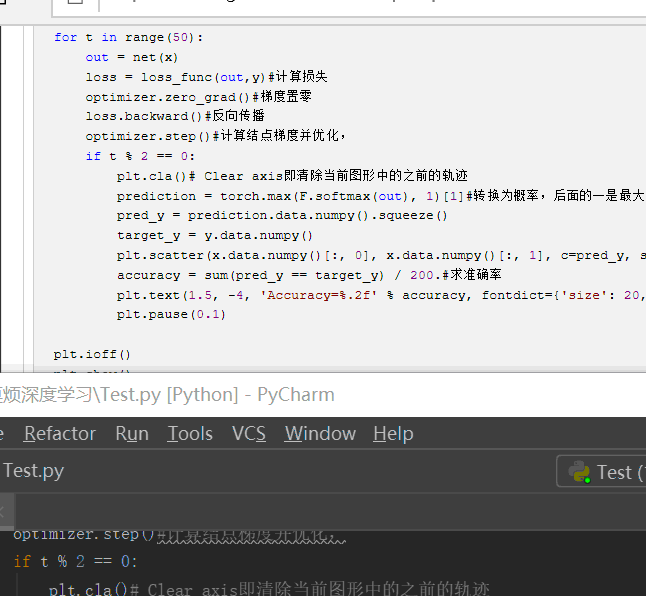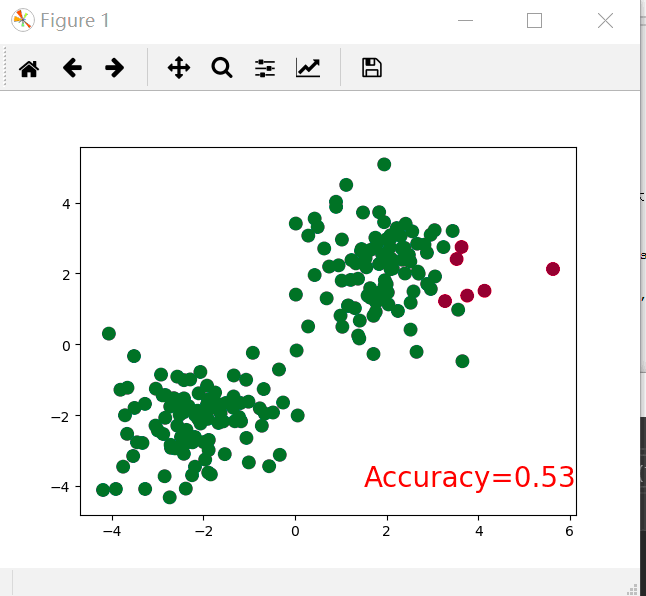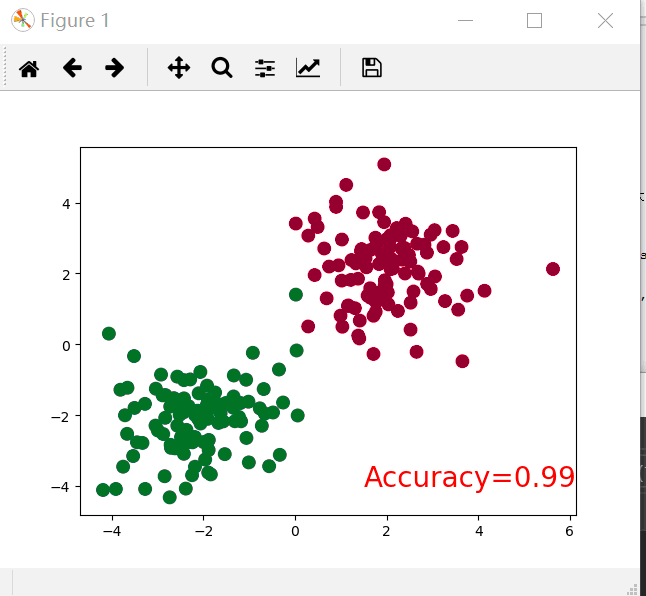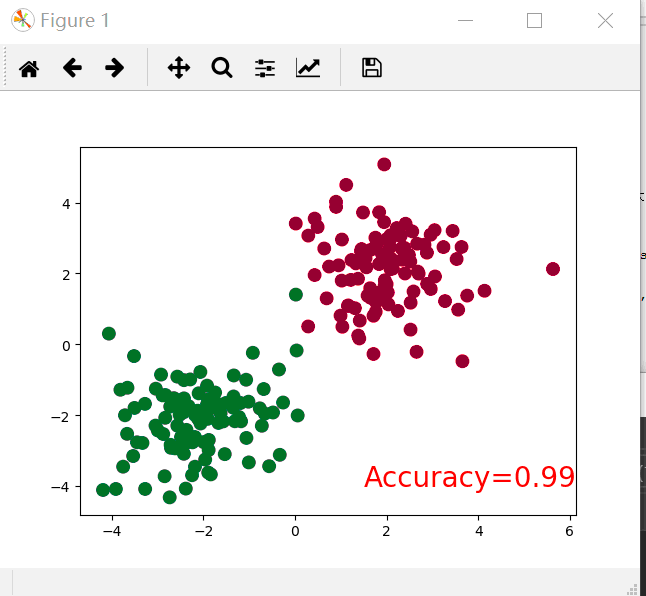
if t % == :
plt.cla()# Clear axis即清除当前图形中的之前的轨迹
prediction = torch.max(F.softmax(out), )[]#转换为概率,后面的一是最大值索引,如果为0则返回最大值
pred_y = prediction.data.numpy().squeeze()
target_y = y.data.numpy()
plt.scatter(x.data.numpy()[:, ], x.data.numpy()[:, ], c=pred_y, s=, lw=, cmap='RdYlGn')
accuracy = sum(pred_y == target_y) / .#求准确率
plt.text(1.5, -, 'Accuracy=%.2f' % accuracy, fontdict={'size': , 'color': 'red'})
plt.pause(0.1) plt.ioff()
plt.show()
下面的是一个比较快搭建神经网络的代码,在上面的代码进行修改,代码如下
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
# make fake data
n_data = torch.ones(, )
x0 = torch.normal(*n_data, ) #每个元素(x,y)是从 均值=*n_data中对应位置的取值,标准差为1的正态分布中随机生成的
y0 = torch.zeros() # 给每个元素一个0标签
x1 = torch.normal(-*n_data, ) # 每个元素(x,y)是从 均值=-*n_data中对应位置的取值,标准差为1的正态分布中随机生成的
y1 = torch.ones() # 给每个元素一个1标签
x = torch.cat((x0, x1), ).type(torch.FloatTensor) # shape (, ) FloatTensor = -bit floating
y = torch.cat((y0, y1), ).type(torch.LongTensor) # shape (,) LongTensor = -bit integer
# torch can only train on Variable, so convert them to Variable
x, y = Variable(x), Variable(y) # draw the data
plt.scatter(x.data.numpy()[:, ], x.data.numpy()[:, ], c=y.data.numpy())#c是一个颜色序列 #plt.show()
#神经网络模块
net2 = torch.nn.Sequential(
torch.nn.Linear(,),
torch.nn.ReLU(),
torch.nn.Linear(,)
) plt.ion()#在Plt.ion和plt.ioff之间的代码,交互绘图
plt.show()
#神经网络优化器,主要是为了优化我们的神经网络,使他在我们的训练过程中快起来,节省社交网络训练的时间。
optimizer = torch.optim.SGD(net.parameters(),lr = 0.01)#其实就是神经网络的反向传播,第一个参数是更新权重等参数,第二个对应的是学习率
loss_func = torch.nn.CrossEntropyLoss()#标签误差代价函数 for t in range():
out = net(x)
loss = loss_func(out,y)#计算损失
optimizer.zero_grad()#梯度置零
loss.backward()#反向传播
optimizer.step()#计算结点梯度并优化,
if t % == :
plt.cla()# Clear axis即清除当前图形中的之前的轨迹
prediction = torch.max(F.softmax(out), )[]#转换为概率,后面的一是最大值索引,如果为0则返回最大值
pred_y = prediction.data.numpy().squeeze()
target_y = y.data.numpy()
plt.scatter(x.data.numpy()[:, ], x.data.numpy()[:, ], c=pred_y, s=, lw=, cmap='RdYlGn')
accuracy = sum(pred_y == target_y) / .#求准确率
plt.text(1.5, -, 'Accuracy=%.2f' % accuracy, fontdict={'size': , 'color': 'red'})
plt.pause(0.1) plt.ioff()
plt.show()
莫烦PyTorch学习笔记(五)——分类的更多相关文章
- 莫烦PyTorch学习笔记(五)——模型的存取
import torch from torch.autograd import Variable import matplotlib.pyplot as plt torch.manual_seed() ...
- 莫烦pytorch学习笔记(八)——卷积神经网络(手写数字识别实现)
莫烦视频网址 这个代码实现了预测和可视化 import os # third-party library import torch import torch.nn as nn import torch ...
- 莫烦pytorch学习笔记(七)——Optimizer优化器
各种优化器的比较 莫烦的对各种优化通俗理解的视频 import torch import torch.utils.data as Data import torch.nn.functional as ...
- 莫烦PyTorch学习笔记(六)——批处理
1.要点 Torch 中提供了一种帮你整理你的数据结构的好东西, 叫做 DataLoader, 我们能用它来包装自己的数据, 进行批训练. 而且批训练可以有很多种途径. 2.DataLoader Da ...
- 莫烦pytorch学习笔记(二)——variable
.简介 torch.autograd.Variable是Autograd的核心类,它封装了Tensor,并整合了反向传播的相关实现 Variable和tensor的区别和联系 Variable是篮子, ...
- 莫烦PyTorch学习笔记(三)——激励函数
1. sigmod函数 函数公式和图表如下图 在sigmod函数中我们可以看到,其输出是在(0,1)这个开区间内,这点很有意思,可以联想到概率,但是严格意义上讲,不要当成概率.sigmod函数 ...
- 莫烦 - Pytorch学习笔记 [ 二 ] CNN ( 1 )
CNN原理和结构 观点提出 关于照片的三种观点引出了CNN的作用. 局部性:某一特征只出现在一张image的局部位置中. 相同性: 同一特征重复出现.例如鸟的羽毛. 不变性:subsampling下图 ...
- 莫烦 - Pytorch学习笔记 [ 一 ]
1. Numpy VS Torch #相互转换 np_data = torch_data.numpy() torch_data = torch.from_numpy(np_data) #abs dat ...
- 莫烦PyTorch学习笔记(四)——回归
下面的代码说明个整个神经网络模拟回归的过程,代码含有详细注释,直接贴下来了 import torch from torch.autograd import Variable import torch. ...
随机推荐
- sklearn中回归器性能评估方法
explained_variance_score() mean_absolute_error() mean_squared_error() r2_score() 以上四个函数的相同点: 这些函数都有一 ...
- 【ARC072E】Alice in linear land
题目 瑟瑟发抖,这竟然只是个蓝题 题意大概就是初始在\(0\),要到坐标为\(D\)的地方去,有\(n\)条指令,第\(i\)条为\(d_i\).当收到一条指令\(x\)后,如果向\(D\)方向走\( ...
- centos安装与配置R语言
Linux下安装R语言 一.编译安装 由于采用编译安装,所以需要用到gcc编译环境,在编译前check文件时还会用到libXt-devel和readline-devel两个依赖,所以在编译R语言源码时 ...
- ionic js 侧栏菜单 把主要内容区域从一边拖动到另一边,来让左侧或右侧的侧栏菜单进行切换
ionic 侧栏菜单 一个容器元素包含侧边菜单和主要内容.通过把主要内容区域从一边拖动到另一边,来让左侧或右侧的侧栏菜单进行切换. 效果图如下所示: 用法 要使用侧栏菜单,添加一个父元素<ion ...
- 解决Keep-Alive 和 Close 不能使用此属性设置
http://www.hejingzong.cn/blog/viewblog_86.aspx Keep-Alive 和 Close 不能使用此属性设置 public static void SetHe ...
- PHP算法之分割平衡字符串
在一个「平衡字符串」中,'L' 和 'R' 字符的数量是相同的. 给出一个平衡字符串 s,请你将它分割成尽可能多的平衡字符串. 返回可以通过分割得到的平衡字符串的最大数量. 示例 1: 输入:s = ...
- 如何优雅的在 vue 中添加权限控制
前言 在一个项目中,一些功能会涉及到重要的数据管理,为了确保数据的安全,我们会在项目中加入权限来限制每个用户的操作.作为前端,我们要做的是配合后端给到的权限数据,做页面上的各种各样的限制. 需求 因为 ...
- cacti ERROR: FILE NOT FOUND
Cacti 版本: 0.8a 在安装好 cacti之后,进入Settings -> Paths, 而且里面的路径在系统中都存在的,在这里显示ERROR: FILE NOT FOUND 参考1的博 ...
- 0908CSP-S模拟测试赛后总结
我早就料到昨天会考两场2333 话说老师终于给模拟赛改名了啊. 距离NOIP祭日还有60天hhh. 以上是废话. %%%DeepinC无敌神 -rank1 zkt神.kx神.动动神 -rank2 有钱 ...
- LUOGU P4253 [SCOI2015]小凸玩密室(树形dp)
传送门 解题思路 玄学树形\(dp\),题目描述极其混乱...看错了两次题,设首先根据每次必须点完子树里的灯才能点别的,那么点灯情况只有两种,第一种是点到某一个祖先,第二种是点到某一个祖先的兄弟.所以 ...