Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架
Python爬虫教程-30-Scrapy 爬虫框架介绍
- 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了
- 常见爬虫框架:
- scrapy
- pyspider
- crawley
- Scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中
- Scrapy 官方文档
Scrapy 的安装
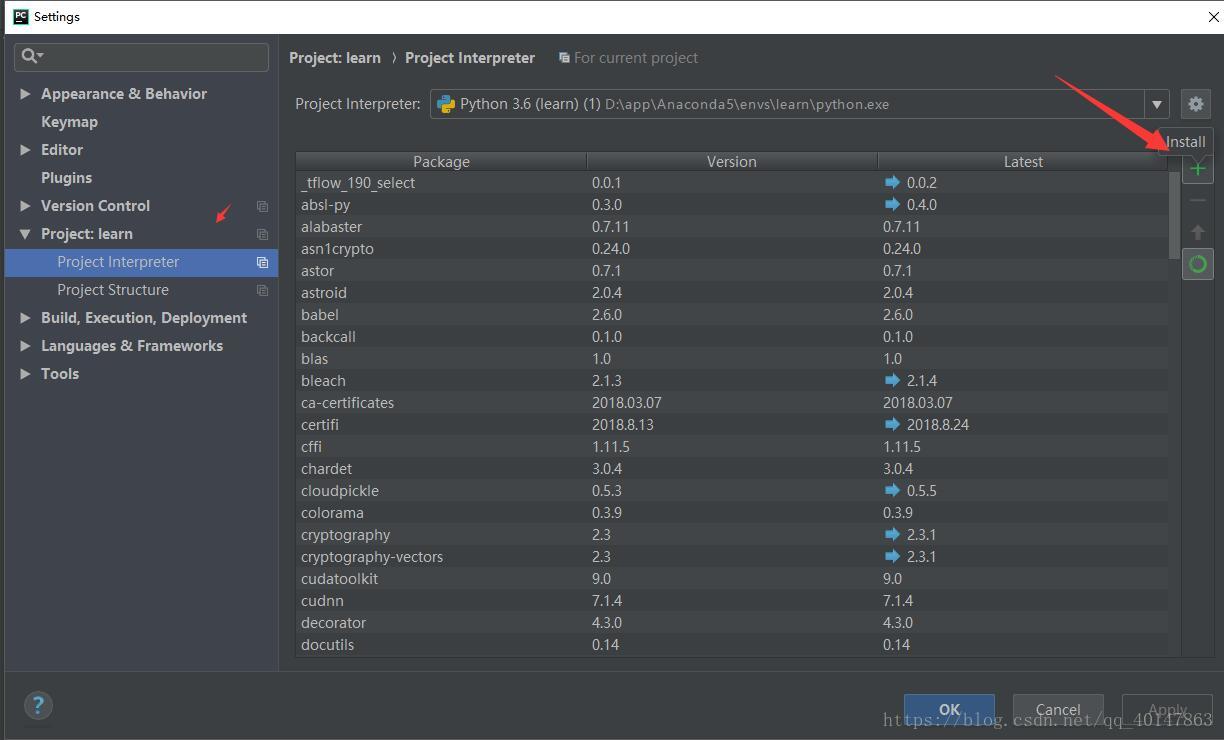
- 可以直接在 Pycharm 进行安装
- 【PyCharm】>【file】>【settings】>【Project Interpreter】>【+】 >【scrapy】>【install】
- 具体操作截图:
- 点击左下角 install 静静等待
测试 Scrapy 是否安装成功
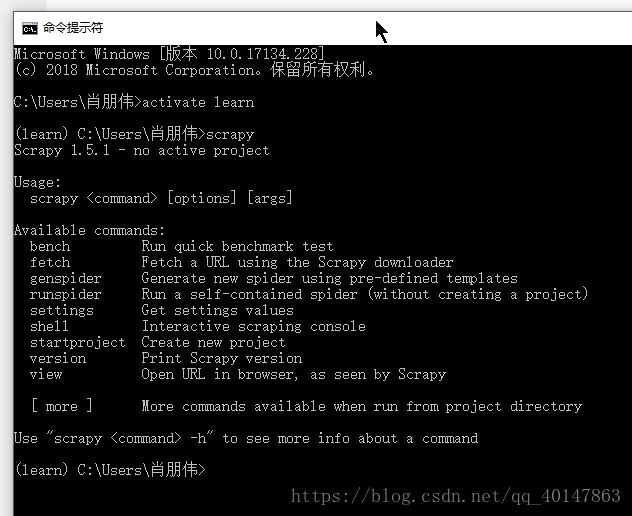
- 进入当前所在的环境
- 输入 scrapy 命令
- 截图:
- 这里就说明安装成功l
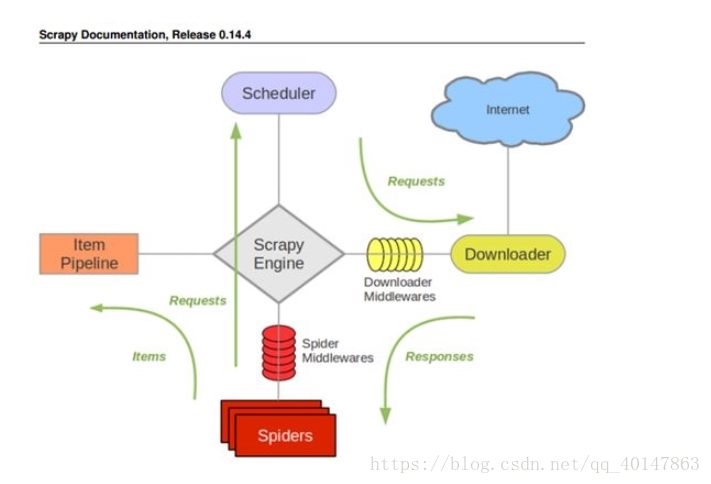
Scrapy 概述
- 包含各个部件
- ScrapyEngine:神经中枢,大脑,核心
- Scheduler 调度器:负责处理请求,引擎发来的 request 请求,调度器需要处理,然后交换引擎
- Downloader 下载器:把引擎发来的 requests 发出请求,得到 response
- Spider 爬虫:负责把下载器得到的网页/结果进行分解,分解成数据 + 链接
- ItemPipeline 管道:详细处理 Item
- DownloaderMiddleware 下载中间件:自定义下载的功能扩展组件
- SpiderMiddleware 爬虫中间件:对 spider 进行功能扩展
- 数据流图:
- 绿色箭头是数据的流向
- 由 Spider 开始 Requests, Requests, Responses, Items
爬虫项目大致流程
- 1.新建项目:scrapy startproject xxx项目名
- 2.明确需要爬取的目标/产品:编写 item.py
- 3.制作爬虫:地址 spider/xxspider.py 负责分解,提取下载的数据
- 4.存储内容:pipelines.py
模块介绍
- ItemPipeline
- 对应 pipelines 文件
- 爬虫提取出数据存入 item 后,item 中保存的数据需要进一步处理,比如清洗,去虫,存储等
- Pipeline 需要处理 process_item 函数
- process_item
- spider 提取出来的 item 作为参数传入,同时传入的还有 spider
- 此方法必须实现
- 必须返回一个 Item 对象,被丢弃的 item 不会被之后的 pipeline
- _ init _:构造函数
- 进行一些必要的参数初始化
- open_spider(spider):
- spider 对象对开启的时候调用
- close_spider(spider):
- 当 spider 对象被关闭的时候调用
- Spider
- 对应的是文件夹 spider 下的文件
- _ init _:初始化爬虫名称,start _urls 列表
- start_requests:生成 Requests 对象交给 Scrapy 下载并返回 response
- parse:根据返回的 response 解析出相应的 item,item 自动进入 pipeline:如果需要,解析 url,url自动交给 requests 模块,一直循环下去
- start_requests:此方法尽能被调用一次,读取 start _urls 内容并启动循环过程
- name:设置爬虫名称
- start_urls:设置开始第一批爬取的 url
- allow_domains:spider 允许去爬的域名列表
- start_request(self):只被调用一次
- parse:检测编码
- log:日志记录
中间件(DownloaderMiddlewares)
- 什么是中间件?
- 中间件是处于引擎和下载器中间的一层组件,可以有多个
- 参照上面的流程图,我们把中间件理解成成一个通道,简单说,就是在请求/响应等传输的时候,在过程中设一个检查哨,例如:
- 1.身份的伪装: UserAgent,我们伪装身份,不是在开始请求的时候就设置好,而是在请求的过程中,设置中间件,当检测到发送请求的时候,拦下请求头,修改 UserAgent 值
- 2.筛选响应数据:我们最开始得到的数据,是整个页面,假设某个操作,需要我们过滤掉所有图片,我们就可以在响应的过程中,设置一个中间件
- 比较抽象,可能不是很好理解,但是过程是其实很简单的
- 在 middlewares 文件中
- 需要在 settings 中设置以是生效
- 一般一个中间件完成一项功能
- 必须实现以下一个或者多个方法
- process_request (self, request, spider)
- 在请求的过程中被调用
- 必须返回 None 或 Response 或 Request 或 raise IgnoreRequest
- 如果返回 None:scrapy 将继续处理 request
- 如果返回 Request:scrapy 会停止调用 process_request 并冲洗调度返回的 request
- 如果返回 Response:scrapy 将不会调用其他的 process_request 或者 process _exception,直接将该 response 作为结果返回,同时会调用 process _response
- process_response (self, request, spider)
- 每次返回结果的时候自动调用
- process_request (self, request, spider)
- 下一篇链接:Python爬虫教程-31-创建 Scrapy 爬虫框架项目
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-30-Scrapy 爬虫框架介绍的更多相关文章
- golang学习笔记17 爬虫技术路线图,python,java,nodejs,go语言,scrapy主流框架介绍
golang学习笔记17 爬虫技术路线图,python,java,nodejs,go语言,scrapy主流框架介绍 go语言爬虫框架:gocolly/colly,goquery,colly,chrom ...
- Python爬虫教程-新浪微博分布式爬虫分享
爬虫功能: 此项目实现将单机的新浪微博爬虫重构成分布式爬虫. Master机只管任务调度,不管爬数据:Slaver机只管将Request抛给Master机,需要Request的时候再从Master机拿 ...
- [Python]基础教程(1)、介绍及环境搭建
一.Python简介 Python是一种解释型.面向对象.动态数据类型的高级程序设计语言,是一个高层次的结合了解释性.编译性.互动性和面向对象的脚本语言. Python 是一种解释型语言: 这意味着开 ...
- Scrapy爬虫框架的学习
第一步安装 首先得安装它,我使用的pip安装的 因为我电脑上面安装了两个python,一个是python2.x,一个是python3.x,所以为了区分,所以,在cmd中,我就使用命令:python2 ...
- 【Python大系】Python快速教程
感谢原作者:Vamei 出处:http://www.cnblogs.com/vamei 怎么能快速地掌握Python?这是和朋友闲聊时谈起的问题. Python包含的内容很多,加上各种标准库.拓展库, ...
- Python快速教程目录(转)
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 怎么能快速地掌握Python?这是和朋友闲聊时谈起的问题. Python包含的内容 ...
- python基础教程
转自:http://www.cnblogs.com/vamei/archive/2012/09/13/2682778.html Python快速教程 作者:Vamei 出处:http://www.cn ...
- Python快速教程(转载)
Python快速教程 作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 怎么能快速地掌握Python?这是和朋友闲聊时谈起的问题 ...
- Python快速教程
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 怎么能快速地掌握Python?这是和朋友闲聊时谈起的问题. Python包含的内容 ...
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 settings.py 文件的使用 想要详细查看 ...
随机推荐
- python学习,day3:示例,进度条
# coding=utf-8 # Author: RyAn Bi import sys,time for i in range(50): sys.stdout.write("#") ...
- DEM反应添加顺序注意问题
在含有DEM反应的dat中,均相反应的block要在DEM反应之前,例如: @(RXNS) (some reaction equations) @(END) @(DES_RXNS) (some rea ...
- 神奇的树上启发式合并 (dsu on tree)
参考资料 https://www.cnblogs.com/zhoushuyu/p/9069164.html https://www.cnblogs.com/candy99/p/dsuontree.ht ...
- stark - 介绍
总结下自己寒假所写的stark组件. 介绍: stark组件,是一个帮助开发者快速实现数据库表的增删改查+的组件. 目标: 1min 中完成实现一张表的增删改查等功能. 目录: stark - 1 ⇲ ...
- BellmanFord贝尔曼-福特算法
import java.util.ArrayList; import java.util.Scanner; /** * 贝尔曼-福特算法 * * Bellman - ford算法是求含负权图的单源最短 ...
- tess4j 注意事项
依赖: <dependency> <groupId>net.sourceforge.tess4j</groupId> <artifactId>tess4 ...
- 转帖 利用伪元素和css3实现鼠标移入下划线向两边展开效果
原帖地址 https://www.cnblogs.com/yangjunfei/p/6739683.html 感谢分享 一.思路: 将伪元素:before和:after定位到元素底部中间,设置宽度 ...
- 差分ADC到单端ADC
单片机可以处理单端ADC(不在电压范围内要进行分压),也可以处理差分ADC(但需要双路输入).差分信号在传输过程中抗共模干扰能力很强,所以传输中都用差分传输,到ADC时可以差分也可以单端(需要放大器处 ...
- Unity自动打包工具
转载 https://blog.csdn.net/ynnmnm/article/details/36774715 最开始有写打包工具的想法,是因为看到<啪啪三国>王伟峰分享的一张图,他们有 ...
- SpringMVC入门(一)
非注解的SpringMVC 1.创建一个web工程 2.导入工程需要的jar包 3.配置SpringMVC的前端控制器 前端控制器(DispatcherAdapter)需要在web.xml文件中进行 ...