Scrapy爬虫框架的学习
第一步安装
首先得安装它,我使用的pip安装的
因为我电脑上面安装了两个python,一个是python2.x,一个是python3.x,所以为了区分,所以,在cmd中,我就使用命令:python2 -m pip install Scrapy (注意我这里使用python2的原因是我给2个python重命名了一下)
安装之后,输入scrapy,出现如下图这样子的信息,表示成功安装了
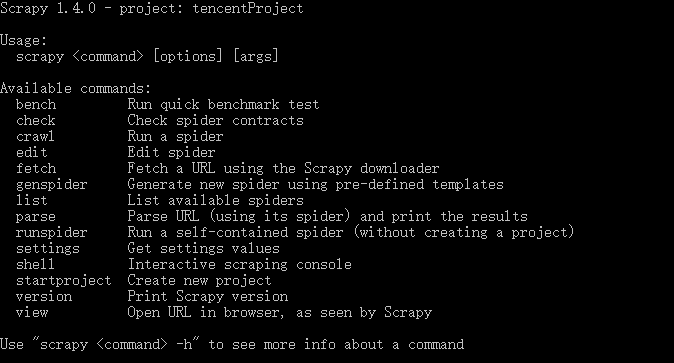
如果有错误,可以参考一下:http://www.cnblogs.com/angelgril/p/7511741.html ,有可能会有用
第二步新建项目
通过命令scrapy startproject xxx 来创建scrapy项目 (注意:你在哪个文件夹下面使用这个命令,项目就创建在哪个文件夹下面,你可以cd到某个你特定的文件夹下面,在使用该命令创建项目)
创建完后,用pycharm编辑器打开项目
项目结构如下图:

下面来简单介绍一下各个文件的作用:
scrapy.cfg :项目的配置文件
tencentProject/ :项目的Python模块,将会从这里引用代码
tencentProject/items.py :项目的items文件
tencentProject/pipelines.py :项目的pipelines文件
tencentProject/settings.py :项目的设置文件
tencentProject/spiders/ :存储爬虫的目录
scrapy 爬虫网站 一共需要4步:
新建项目 (Project):新建一个新的爬虫项目
明确目标 (Items):明确你想要抓取的目标
制作爬虫 (Spider):制作爬虫开始爬取网页
存储内容 (Pipeline):设计管道存储爬取内容
第三步明确目标
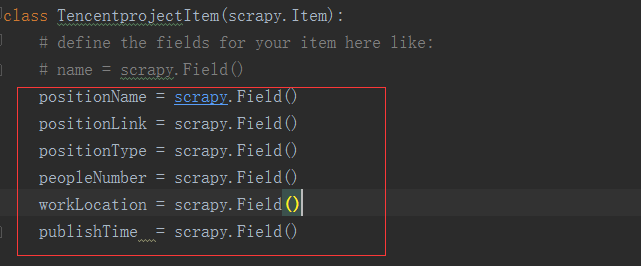
修改 tencentProject目录下的 items.py 文件,添加相应的属性,(注意:scrapy.Field(),是固定的,只要记住就行了)
刚开始看起来可能会有些看不懂,但是定义这些item能让你用其他组件的时候知道你的items到底是什么。可以把Item简单的理解成封装好的类对象
第四步制作爬虫
1、爬取
要建立一个Spider, 你必须用scrapy.spider.BaseSpider创建一个子类 ,并确定 三 个强制的属性:
name :爬虫的识别名称,必须是唯一的,在不同的爬虫中你必须定义不同的名字。
start_urls :爬取的URL列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会
从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
parse() :解析的方法,调用的时候传入从每一个URL传回的Response对象作为唯一参
数,负责解析并匹配抓取的数据(解析为item),跟踪更多的URL
可选设置的参数allow_domains 是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页。
在Scrapy里,使用一种叫做 XPath selectors 的机制,它基于 XPath 表达式,

下面我们来定义一只爬虫,命名为 tencent.py ,保存在 tencentProject\spiders 目录下。
tencent.py代码如下:
# -*- coding: utf-8 -*-
import scrapy
from tencentProject.items import TencentprojectItem class TencentSpider(scrapy.Spider):
# 爬虫名
name = 'tencent'
# 爬虫爬取数据的域范围
allowed_domains = ['tencent.com']
# 1. 需要拼接的url
baseURL = "http://hr.tencent.com/position.php?&start="
# 1. 需要拼接的url地址的偏移量
offset = 0
# 爬虫启动时,读取的url地址列表
start_urls = [baseURL + str(offset)] # 用来处理response
def parse(self, response):
# 提取每个response的数据
node_list = response.xpath("//tr[@class='even'] | //tr[@class='odd']") for node in node_list:
# 构建item对象,用来保存数据
item = TencentprojectItem()
# 提取每个职位的信息,并且将提取出的Unicode字符串编码为UTF-8编码
item['positionName'] = node.xpath("./td[1]/a/text()").extract()[0].encode("utf-8") item['positionLink'] = node.xpath("./td[1]/a/@href").extract()[0].encode("utf-8") if len(node.xpath("./td[2]/text()")):
item['positionType'] = node.xpath("./td[2]/text()").extract()[0].encode("utf-8")
else:
item['positionType'] = "NULL" item['peopleNumber'] = node.xpath("./td[3]/text()").extract()[0].encode("utf-8") item['workLocation'] = node.xpath("./td[4]/text()").extract()[0].encode("utf-8") item['publishTime'] = node.xpath("./td[5]/text()").extract()[0].encode("utf-8") # yield 的重要性,是返回数据后还能回来接着执行代码
yield item # 第一种写法:拼接url,适用场景:页面没有可以点击的请求连接,必须通过拼接url才能获取响应
# if self.offset < 2190:
# self.offset += 10
# url = self.baseURL + str(self.offset)
# yield scrapy.Request(url, callback = self.parse) # 第二种写法:直接从response获取需要爬取的连接,并发送请求处理,直到链接全部提取完
if len(response.xpath("//a[@class='noactive' and @id='next']")) == 0: url = response.xpath("//a[@id='next']/@href").extract()[0]
yield scrapy.Request("http://hr.tencent.com/" + url, callback = self.parse)
#def parse_next(self, response):
# pass
tencent.py
注意:里面的关键字yield 的作用是:返回数据后,还能继续去执行未完成的操作,它不像return,但是,它又有return的返回数据的功能
2、存储
在管道文件pipelines.py 去添加一下代码:
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json class TencentprojectPipeline(object): def __init__(self):
self.f=open("tencent.json","w")
def process_item(self, item, spider):
#设置完后,一定要去去掉settings.py文件中的注释,才能启用管道
'''
ITEM_PIPELINES = {
'tencentProject.pipelines.TencentprojectPipeline': 300,}
'''
content=json.dumps(dict(item),ensure_ascii=False)+",\n" #json.dumps()转换成json类型的字符串,ensure_ascii=False 表示遵循unicode编码来转换
self.f.write(content)
return item def close_spider(self,spider):
self.f.close()
Scrapy爬虫框架的学习的更多相关文章
- scrapy爬虫框架学习笔记(一)
scrapy爬虫框架学习笔记(一) 1.安装scrapy pip install scrapy 2.新建工程: (1)打开命令行模式 (2)进入要新建工程的目录 (3)运行命令: scrapy sta ...
- Scrapy 爬虫框架学习笔记(未完,持续更新)
Scrapy 爬虫框架 Scrapy 是一个用 Python 写的 Crawler Framework .它使用 Twisted 这个异步网络库来处理网络通信. Scrapy 框架的主要架构 根据它官 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- Scrapy爬虫框架中的两个流程
下面对比了Scrapy爬虫框架中的两个流程—— ① Scrapy框架的基本运作流程:② Spider或其子类的几个方法的执行流程. 这两个流程是互相联系的,可对比学习. 1 ● Scrapy框架的基本 ...
- 安装scrapy 爬虫框架
安装scrapy 爬虫框架 个人根据学习需要,在Windows搭建scrapy爬虫框架,搭建过程种遇到个别问题,共享出来作为记录. 1.安装python 2.7 1.1下载 下载地址 1.2配置环境变 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
随机推荐
- idea搭建ssm框架
1.file-->new-->project-->maven.... 2.建立后的目录: 3.pom.xml依赖建立: <?xml version="1.0" ...
- python安装selenium和下载浏览器驱动
1.安装selenium 方法一:可以用在cmd中用pip命令安装. python默认自带pip工具,如果在电脑上配置了pip的环境变量,打开cmd命令窗口后可以直接输入命令pip insta ...
- loadrunner 关联函数web_reg_save_param
当我们每次访问网站都需要提交从服务器获取的动态文本时就会需要用到关联函数,就好像每次乘坐火车票我们都需要用最新的火车票,如果用旧车票就不能做火车,如果我们采用了录制时的旧动态码如usersession ...
- program_options
[program_options] The program_options library allows program developers to obtain program options, t ...
- Mysql 存储过程批量建表
CREATE DEFINER=`root`@`%` PROCEDURE `createTables`() begin declare i int; declare suffix varchar(20) ...
- Java虚拟机运行时数据区域及垃圾回收算法
程序计数器 记录正在执行的虚拟机字节码指令的地址(如果正在执行的是本地方法则为空). Java 虚拟机栈 每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表.操作数栈.动态链接.方法出口 ...
- python——获取文件列表
"""-------------------------------------------------------- <<获取文件列表>> () ...
- 搞搞电脑微信表情的破解(.dat转png or jpg)
首先感谢:https://blog.csdn.net/weixin_42440768/ 因为狗子喜欢之前那个头像,但是没找到,于是我想看看我们之前的斗图过程中有没有发她的头像. 这是做这件事情的起因. ...
- Babel 配置选项
comments 是否去掉注释,true(默认)/false.
- excel 上传读写到数据库
<HTML> <div class="input-group"> <form id="abc" action="http ...