分布式算法-一致性HASH
分布式算法
参考:
https://blog.51cto.com/alanwu/1431397
https://blog.csdn.net/kojhliang/article/details/81205516
元数据问题
在分布式存储中面临的一个重要问题是如何在多个存储节点上分布数据。了解GFS之类文件系统的同学都知道可以采用元数据服务器(MS)的方式决定数据块在存储节点上的分布映射。采用元数据服务器方式可以很好的将数据和元数据分离,访问文件系统命令空间的时候,可以直接从元数据服务器上获取文件的映射信息。基于MS的分布式存储架构如下图所示:
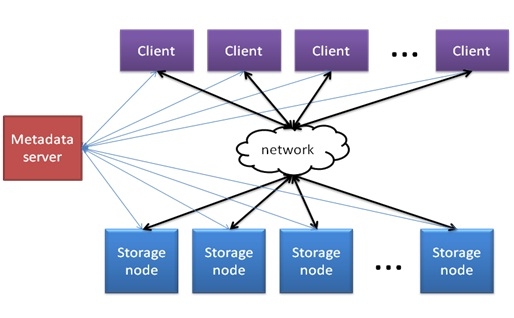
基于元数据服务器的方式是分布式存储的经典架构,虽然看起来很完美,但是还是存在如下两大主要问题:
1,可扩展性受限于元数据服务器的能力。所有的元数据信息都集中在元数据服务器上面,所以,当Client想要获取元数据时就需要访问该服务器。因此,整体的带载能力(Client的个数)就受限于元数据服务器的能力。元数据服务器就是整个分布式系统的潜在瓶颈点。特别当Client访问小文件时,会产生大量的元数据信息,此时元数据服务器就会成为系统性能瓶颈。
2,元数据服务器是分布式系统中的单点故障点。一旦元数据服务器发生故障,整个分布式存储系统将无法正常工作,因此,元数据服务器的可靠性尤为重要。
总结起来,基于元数据服务器的分布式存储架构最大的问题在于可扩展能力和可靠性。而且这些问题的核心点都在于元数据服务器上。对此也有很多的系统优化手段,例如,针对元数据服务器影响系统可扩展性能力的问题,可以采用分布式元数据服务器的手段进行缓解,但是,又会额外引入分布式元数据服务器之间数据同步和加锁互斥的问题。针对元数据服务器单点故障的问题,可以采用HA的手段增强系统可靠性,很多厂商在Hadoop分布式文件系统中做了很多元数据服务器HA的尝试。
分布式算法
但无论怎么优化,采用元数据服务器方式的分布式存储都不能达到线性可扩展的目的。基本上扩展能力呈现对数LOG的曲线方式。为了达到线性可扩展的能力,业界开始考虑如何去掉元数据服务器,即去中心化。其中发展出来的算法有HASH算法、一致性HASH算法、弹性HASH算法和CRUSH算法。此处重点讨论一致性HASH算法。
HASH算法
在谈到一致性HASH的时候,首先需要考虑HASH算法。在分布式存储中应用的HASH算法很简单,其可以描述如下:
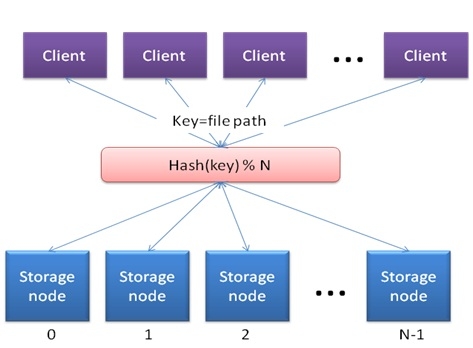
当Client需要将一个文件写入Storage的时候,可以将文件路径作为Key值算出一个HASH值,这个HASH算法需要有很好的分布特征。在得出这个HASH值之后,再和Storage Node的个数N做取余操作,得出的结果在0到N-1之间,该结果就是需要访问的Storage Node编号。从这种方法来看,一个文件在Storage Node中的布局不需要元数据服务器的介入,文件和存储节点之间的映射关系由HASH函数来决定,并且是可计算的。
HASH算法看起来非常的完美,但是,其问题在于如果动态增加一个节点之后,这种数据映射关系就会遭到破坏,原因在于HASH算法中的N发生了变化。为了建立新的映射关系,不得不需要引入大量的数据迁移操作,这在大规模分布式存储中是不允许发生的。为了解决这个问题,引入了一致性HASH算法。
一致性HASH
一致性HASH的核心思想是将HASH结果域做成一个空间,并且为所有的存储节点分配一个标签值,这些标签值属于这个HASH值空间。通常这种关系可以描述成一个哈希环,这个空间就构成了这个HASH环,所有存储节点是这个环上的一个点。可以描述如下:
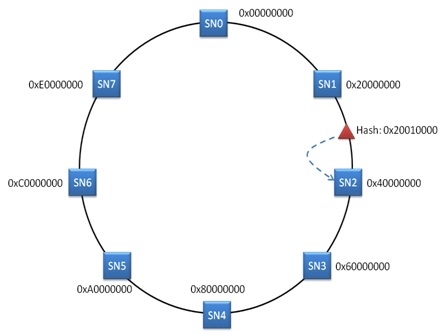
当Client需要将一个文件写入Storage的时候,同样可以将文件路径作为HASH函数的参数,然后得到一个HASH值。这个得到的HASH值肯定会属于HASH值空间,也就是说在HASH环上面肯定可以找到一个对应的点。例如,这个点位于SN1和SN2之间。按照协议,可以选择顺时针离HASH值最近的节点作为数据存储点。即新写入的文件可以存入SN2。
一致性HASH算法的最大优点在于避免添加存储节点之后的大规模数据迁移。例如在刚才的例子中,如果后来在SN1和SN2之间添加了一个SN8,那么原先存入SN2中的一部分数据需要迁移到SN8,但是,其余节点不需要做任何的数据迁移操作。
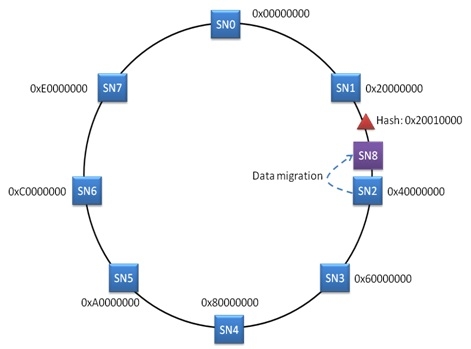
显然这种方法大大降低了数据迁移量,又能很好的避免元数据服务器带来的问题。因此,一致性HASH算法被广泛应用到了CDN系统、SWIFT对象存储系统、Amazon的dynamo存储系统中。
一致性HASH的改进
一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如系统中只有两台服务器,可能大量的数据都存在一台服务器,另一台服务器只存储了很少的数据。为了解决这种情况,可以增加虚拟环。
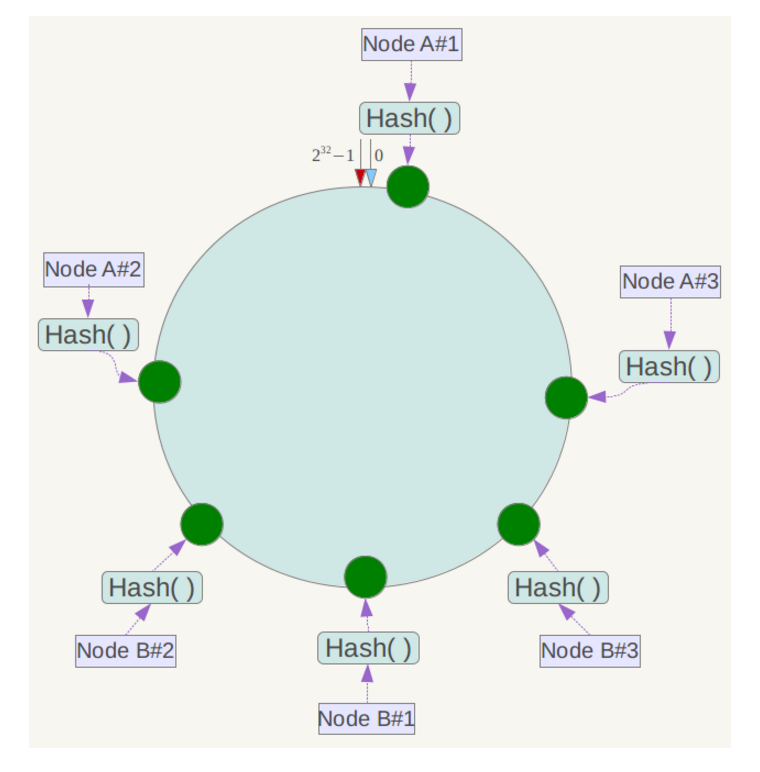
为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,注意,这里的多个哈希算法应该使得结果尽量分布均匀,才能最大程度减少数据倾斜的情况。每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值。同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
分布式算法-一致性HASH的更多相关文章
- 分布式算法(一致性Hash算法)
一.分布式算法 在做服务器负载均衡时候可供选择的负载均衡的算法有很多,包括: 轮循算法(Round Robin).哈希算法(HASH).最少连接算法(Least Connection).响应速度算法( ...
- 一致性Hash算法(分布式算法)
一致性哈希算法是分布式系统中常用的算法,为什么要用这个算法? 比如:一个分布式存储系统,要将数据存储到具体的节点(服务器)上, 在服务器数量不发生改变的情况下,如果采用普通的hash再对服务器总数量取 ...
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- 【转载】一致性hash算法释义
http://www.cnblogs.com/haippy/archive/2011/12/10/2282943.html 一致性Hash算法背景 一致性哈希算法在1997年由麻省理工学院的Karge ...
- 一致性Hash算法及使用场景
一.问题产生背景 在使用分布式对数据进行存储时,经常会碰到需要新增节点来满足业务快速增长的需求.然而在新增节点时,如果处理不善会导致所有的数据重新分片,这对于某些系统来说可能是灾难性的. 那 ...
- 分布式缓存技术memcached学习系列(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到"分布式一致性hash算法"这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前, ...
- [转载] 一致性hash算法释义
转载自http://www.cnblogs.com/haippy/archive/2011/12/10/2282943.html 一致性Hash算法背景 一致性哈希算法在1997年由麻省理工学院的Ka ...
- php一致性hash算法的应用
阅读这篇博客前首先你需要知道什么是分布式存储以及分布式存储中的数据分片存储的方式有哪些? 分布式存储系统设计(2)—— 数据分片 阅读玩这篇文章后你会知道分布式存储的最优方案是使用 一致性hash算法 ...
- 分布式一致性hash算法
写在前面 在学习Redis的集群内容时,看到这么一句话:Redis并没有使用一致性hash算法,而是引入哈希槽的概念.而分布式缓存Memcached则是使用分布式一致性hash算法来实现分布式存储. ...
随机推荐
- tornado的使用-数据库篇
tornado的使用-数据库篇
- java编程思想第四版第三章要点总结
1. 静态导入 使用import static方式导入一个类的所有方法. 例如: import static net.mindview.util.Print.*; 首先定义了一个Print类,里面有静 ...
- 【Java】面向对象之封装
面向对象编程是对客观世界的模拟,客观世界里成员变量都是隐藏在对象内部的,外界无法直接操作和修改.封装可以被认为是一个保护屏障,防止该类的代码和数据被其他类随意访问.要访问该类的数据,必须通过指定的方式 ...
- Pashmak and Buses(构造)
题目链接:http://codeforces.com/problemset/problem/459/C 题意:n个人, k辆车, d天,每天将所有 任意人安排到k辆车, 问怎样安排, 可时不存在 2人 ...
- PHP产生不重复随机数的5个方法总结
无论是Web应用,还是WAP或者移动应用,随机数都有其用武之地.在最近接触的几个小项目中,我也经常需要和随机数或者随机数组打交道,所以,对于PHP如何产生不重复随机数常用的几种方法小结一下 无论是We ...
- php Swoole实现毫秒级定时任务
项目开发中,如果有定时任务的业务要求,我们会使用linux的crontab来解决,但是它的最小粒度是分钟级别,如果要求粒度是秒级别的,甚至毫秒级别的,crontab就无法满足,值得庆幸的是swoole ...
- 建筑行业的新起之秀---BIM
近年来,BIM在国家在建筑行业的推进下逐渐走近人们的视线,而且BIM技术是作为建筑领域的一项新技术行业发展的越来越好,在很多的建筑场景都用到了BIM建模.施工.运维以及BIM+GIS等以BIM为 ...
- 【Flink】Flink基础之WordCount实例(Java与Scala版本)
简述 WordCount(单词计数)作为大数据体系的标准示例,一直是入门的经典案例,下面用java和scala实现Flink的WordCount代码: 采用IDEA + Maven + Flink 环 ...
- 2019-11-24:postgresql数据库安装,最后报错failed to load SQLModule 问题的解决方案
安装环境:Windows 10 问题描述:Failed to load sql modules into the database cluster 原因在于 Postgresql 没有安装完全. 解决 ...
- Altium Designer 18 画keepout层与将keepout层转换成Mechanical1层的方法
画keepout的方法 先选中Keepout层:然后 右键->Place->Keepout->然后选择要画圆还是线 Keepout层一般只用来辅助Layout,不能作为PCB的外形结 ...