Stanford机器学习笔记-7. Machine Learning System Design
7 Machine Learning System Design
Content
7 Machine Learning System Design
7.1 Prioritizing What to Work On
7.2 Error Analysis
7.3 Error Metrics for Skewed Classed
7.3.1 Precision/Recall
7.3.2 Trading off precision and recall: F1 Score
7.4 Data for machine learning
7.1 Prioritizing What to Work On
当我们着手针对某一实际问题设计机器学习系统时,我们应该在哪些方面花费较多的时间来使得系统的误差较少?以构建一个垃圾邮件分类器(a spam classifier)为例,我们可以从下面几个方面考虑:
- Collect lots of data
- E.g. "honeypot" project.
- Develop sophisticated features based on email routing information (from email header).
- Develop sophisticated features for message body, e.g. should "discount" and "discounts" be treated as the same word? How about "deal" and "Dealer"? Features about punctuation?
- Develop sophisticated algorithm to detect misspellings (e.g. m0rtgage, med1cine, w4tches.)
很难说上述的哪一种方式最有效,而且每一种方式往往需要花费很多时间去研究调查。
7.2 Error Analysis
解决机器学习问题的推荐做法是:
- Start with a simple algorithm that you can implement quickly. Implement it and test it on your cross-validation data.
- Plot learning curves to decide if more data, more features, etc. are likely to help.
- Error analysis: Manually examine the examples (in cross validation set) that your algorithm made errors on. See if you spot any systematic trend in what type of examples it is making errors on.
将误差转变为一个单一的数值非常重要,否则很难判断我们所是设计的学习算法的表现。
7.3 Error Metrics for Skewed Classed
有时很难说误差的减少是否真正改善了算法。以癌症分类为例:
我们训练了一个logistic回归模型来预测病人是否得癌症 (y = 1 if cancer, y = 0 otherwise),我们在测试集上测得误差为1%(即正确诊断率99%)。但是,事实上病人患癌症的概率只有0.50%,也就是如果我们完全忽略特征量,直接令所有的y = 0,那么该模型的错误率只有0.5%。我们辛苦得到模型的误差居然比直接令y=0的误差大。这很让人生气! 但是仔细想想,直接令y = 0真的比我们训练出的模型好吗? 假设我们需要预测一个事实上已经患癌症(y=1)的病人,那么前者完全不可能预测正确,而后者却是有机会预测正确的。从这个角度看,我们训练得到的模型似乎更好。这也就说明了算法1比算法2的误差小,不一定算法1就好。
7.3.1 Precision/Recall
上述的情况通常发生在skewed classes的情况,即一类的数据远比另一类的数据多。对于这种情况,我们需要采取另一种方式来衡量一个学习算法的性能。
我们定义准确率(Precision)和召回率(Recall)如下所示,它们分别从两种角度衡量算法的性能。

所以,当令y = 0时,Recall = 0 / (0 + #False neg) = 0, 即使它有很小的误差,但是它的召回率太低了。
注意,如果一个算法预测所有的情况都是negative,则Precision无定义,因为此时
#predicted positive = 0, 除0是无意义的。
7.3.2 Trading off precision and recall: F1 Score
在7.2节中我们提到,将误差转变为一个单一的数值非常重要,因为这样我们才能方便的比较不同算法之间的优劣。现在我们有precision和recall两个衡量标准,我们需要权衡两者。如果用Logistic回归模型预测病人是否患癌症,考虑下面的情况:
情况1: 假设考虑到一个正常人如果误判为癌症,将会承受不必要的心理和生理压力,所以我们要有很大把握才预测一个病人患癌症(y=1)。那么一种方式就是提高阙值(threshold),不妨设我们将阙值提高到0.7,即:
Predict 1 if: hθ(x)≥0.7
Predict 0 if: hθ(x)<0.7
在这种情况下,根据7.3.1节的定义,我们将会有较高的precision,但是recall将会变低。
情况2: 假设考虑到一个已经患癌症的病人如果误判为没有患癌症,那么病人可能将因不能及时治疗而失去宝贵生命,所以我们想要避免错过癌症患者的一种方式就是降低阙值,假设降低到0.3, 即
Predict 1 if: hθ(x)≥0.3
Predict 0 if: hθ(x)<0.3
在这种情况下,将得到较高的recall,但是precision将会下降。
情况1和情况2似乎是相互矛盾的,事实上,precision和recall往往是如下关系,并且高阙值对应高precision和低recall;低阙值对应低precision和高recall。
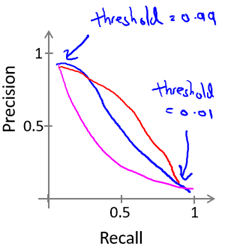
这样看来,我们不得不在precision和recall做出权衡。考虑下面的例子:
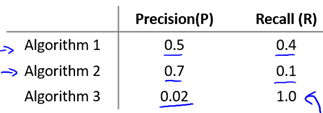
可以看出算法3是恒预测y=1(因为其recall = 1).
为了将precision(P)和recall(R)这两种度量方式转为一种单一的方式,一个简单的考虑是取二者的平均值,即: (P + R) / 2;但是这种方式似乎不太理想,因为如果这样,算法3将会被认为是最优的,而算法3是恒预测y=1,precision非常低。
事实上,一种更好的方式根据precision和recall的调和平均定义F1 Score如下:
1 / F1 = (1 / P + 1 / R) / 2
得 F1 = 2PR / (P + R)
要使F1较大,需要P和R同时较大,特别的,有:
- P = 0,R = 1,则F1 =0
- P = 1,R = 0,则F1 = 0
- P = 1,R = 1,则F1 = 1
注意:我们应该是在交叉检验集上测试F1的值,避免依赖测试集。
7.4 Data for machine learning
多少数据量对于我们训练学习算法是足够的呢?
通常来说,一个"劣等"算法(inferior algorithm),如果给它足够的数据来学习,它的表现往往优于一个缺乏数据学习的"优等"算法(superior algorithm)。所以在机器学习界有一个这样的共识:
"It's not who has the best algorithm that wins. It's who has the most data."
(我想这就是BIG DATA的魅力吧)
值得注意的是,为了充分利用数据,我们应该选择包含足够信息的特征量。通常一个判断参考是,给出输入x,一个人类的专家是否能够自信的预测出y。
- Large data rationale
数据量大能够起作用的基本原理是,可以使用一个具有大量参数的学习算法(e.g. logistic regression/linear regression with many features; neural network with many hidden units)来保证偏差较小,然后使用大量的训练集来大大减弱过拟合(方差较小),从而达到训练出一个在测试集上误差较小的,泛化能力强的模型。
Stanford机器学习笔记-7. Machine Learning System Design的更多相关文章
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 11—Machine Learning System Design 机器学习系统设计
Lecture 11—Machine Learning System Design 11.1 垃圾邮件分类 本章中用一个实际例子: 垃圾邮件Spam的分类 来描述机器学习系统设计方法.首先来看两封邮件 ...
- Coursera 机器学习 第6章(下) Machine Learning System Design 学习笔记
Machine Learning System Design下面会讨论机器学习系统的设计.分析在设计复杂机器学习系统时将会遇到的主要问题,给出如何巧妙构造一个复杂的机器学习系统的建议.6.4 Buil ...
- Machine Learning - XI. Machine Learning System Design机器学习系统的设计(Week 6)
http://blog.csdn.net/pipisorry/article/details/44119187 机器学习Machine Learning - Andrew NG courses学习笔记 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 6) Advice for Applying Machine Learning & Machine Learning System Design
(1) Advice for applying machine learning Deciding what to try next 现在我们已学习了线性回归.逻辑回归.神经网络等机器学习算法,接下来 ...
- Machine Learning - 第6周(Advice for Applying Machine Learning、Machine Learning System Design)
In Week 6, you will be learning about systematically improving your learning algorithm. The videos f ...
- 斯坦福第十一课:机器学习系统的设计(Machine Learning System Design)
11.1 首先要做什么 11.2 误差分析 11.3 类偏斜的误差度量 11.4 查全率和查准率之间的权衡 11.5 机器学习的数据 11.1 首先要做什么 在接下来的视频中,我将谈到机器 ...
- 斯坦福大学公开课机器学习:machine learning system design | error metrics for skewed classes(偏斜类问题的定义以及针对偏斜类问题的评估度量值:查准率(precision)和召回率(recall))
上篇文章提到了误差分析以及设定误差度量值的重要性.那就是设定某个实数来评估学习算法并衡量它的表现.有了算法的评估和误差度量值,有一件重要的事情要注意,就是使用一个合适的误差度量值,有时会对学习算法造成 ...
- 斯坦福大学公开课机器学习: machine learning system design | error analysis(误差分析:检验算法是否有高偏差和高方差)
误差分析可以更系统地做出决定.如果你准备研究机器学习的东西或者构造机器学习应用程序,最好的实践方法不是建立一个非常复杂的系统.拥有多么复杂的变量,而是构建一个简单的算法.这样你可以很快地实现它.研究机 ...
- 斯坦福大学公开课机器学习: machine learning system design | prioritizing what to work on : spam classification example(设计复杂机器学习系统的主要问题及构建复杂的机器学习系统的建议)
当我们在进行机器学习时着重要考虑什么问题.以垃圾邮件分类为例子.假如你想建立一个垃圾邮件分类器,看这些垃圾邮件与非垃圾邮件的例子.左边这封邮件想向你推销东西.注意这封垃圾邮件有意的拼错一些单词,就像M ...
随机推荐
- Mondrian – 开源的矢量图形 Web 应用程序
Mondrian 是一个免费矢量图形 Web 应用程序,类似 Adobe Illustrator 或 Inkscape.Mondrian 提供所有所需的工具来创建.修改和导出简单的 SVG 文件,过历 ...
- [deviceone开发]-基础文件管理器
一.简介 主要实现本地文件管理功能,主要功能为复制.粘贴.剪切目录或者文件. 二.效果 三.相关下载 https://github.com/do-project/code4do/tree/master ...
- VS 2015打开项目闪退,新建项目提示未将对象引用到实例
因为开发需要,要把开发工具换成visual studio2015,装完之后会有警告“js”安装的问题,打开VS也没有问题, 但是一打开项目就闪退,新建项目也不行,查看应用程序日志,报错提示如下: .N ...
- MyEclispe 2015 CI 15发布(附下载)
MyEclipse 2015 CI 15带来了一些程序上的改进,包括可外部部署的JavaScript调 试,改进了 REST Inspect 和 WebSphere 框架支持,新增服务器连接器,另外还 ...
- 智者当借力而行, 借助Autodesk应用程序商店实现名利双收
有没有注意到这个"精选应用"菜单?有没有想过这个菜单下的应用是从哪里来的?你的应用也可以出现在这里哦~ 如果你还不知道,Autodesk在几年前就发布了Autodesk应用程序商店 ...
- 国内最全最详细的hadoop2.2.0集群的MapReduce的最简单配置
简介 hadoop2的中的MapReduce不再是hadoop1中的结构已经没有了JobTracker,而是分解成ResourceManager和ApplicationMaster.这次大变革被称为M ...
- 操作系统开发系列—12.b.从Loader跳入保护模式
现在,内核已经被我们加载进内存了,该是跳入保护模式的时候了. 首先是GDT以及对应的选择子,我们只定义三个描述符,分别是一个0~4GB的可执行段.一个0~4GB的可读写段和一个指向显存开始地址的段: ...
- .Net控件经验集合
一.DropDownList默认选中 开始的笨方法: foreach (ListItem item in DropDownList1.Items) { ...
- 【代码笔记】iOS-剧幕拉开形的首页
一,工程图. 二,代码. RootViewController.h #import <UIKit/UIKit.h> #import "UIImage+SplitImageInto ...
- OC 类方法,对象方法,构造方法以及instancetype和id的异同
OC 类方法,对象方法,构造方法以及instancetype和id的异同 类方法: 类方法是可以直接使用类的引用,不需要实例化就可以直接使用的方法.一般写一些工具方法. 类方法: 声明和实现的时候,以 ...