ArrayList源码解析-JDK18
引言
ArrayList在JDK1.7和1.8中的差距并不大,主要差距以下几个方面:
JDK1.7
- 在JDK1.7中,使用ArrayList list = new ArrayList()创建List集合时,底层直接创建了长度是10的Object[]数组elementData;在接下来调用add()方法向集合中添加元素时,如果本次的添加导致底层elementData数组容量不足,则调用 ensureCapacity(int minCapacity) 方法进行扩容。默认情况下,扩容为原来的1.5倍(>>1),同时将原来数组中的所有数据复制到新的数组中。
- 故而,由此得到结论,在开发中,建议使用带参构造器创建List集合:ArrayList list = new ArrayList(int capacity),预估集合的大小,直接一次到位,避免中间的扩容,提高效率。
JDK1.8
- JDK 1.8和1.7中 ArrayList 最明显的区别就是底层数组在JDK1.8中,如果不指定长度,使用无参构造方法ArrayList list = new ArrayList()创建List集合时,底层的Object[] elementData初始化为{}(空的数组),并没有直接创建长度为10的数组;
- 而在第一次调用add()方法时,底层才创建了长度为10的数组,并将本次要添加的元素添加进去(这样做可节省内存消耗,因为在添加元素时数组名将指针指向了新的数组且老数组是一个空数组这样有利于System.gc(),并不会一直占据内存)。
- 后续的添加和扩容操作与JDK1.7无异。
继承与实现
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
具体继承与实现结构如下图所示:
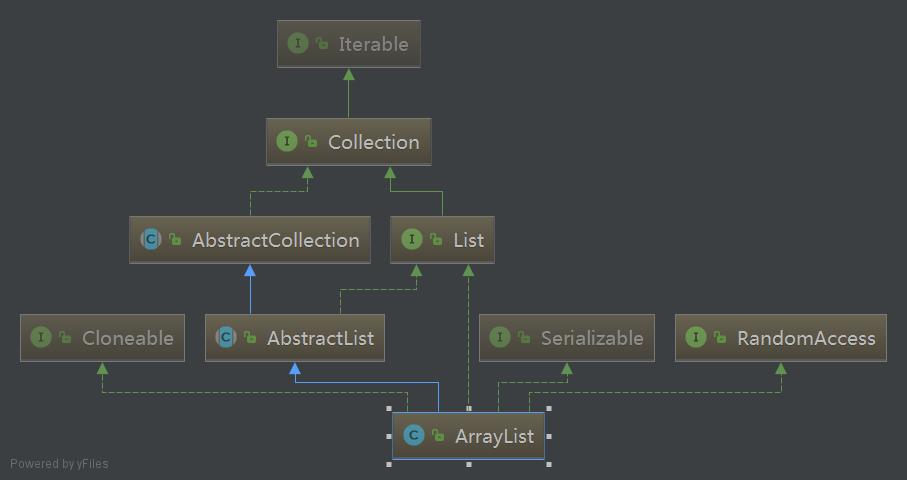
可以看到它继承了AbstractList抽象类,List、RandomAccess、Cloneable和Serializable接口。
与HashMap中一样,Cloneable和Serializable这两个接口都是标记接口,Cloneable用于标记该类可以被克隆,只有实现这个接口后,然后在类中重写Object中的clone方法,然后通过类调用clone方法才能进行克隆,而Serializable则是表示这个类可以被序列化。
与HashMap不同的是ArrayList还多了个RandomAccess接口,这个接口同样是标记接口,它用于标记实现该接口的类可以进行随机访问。
在这里还有一点需要注意,为什么要先继承AbstractList,而让AbstractList先实现List?而不是让ArrayList直接实现List?
这里是有一个思想,接口中全都是抽象的方法,而抽象类中可以有抽象方法,还可以有具体的实现方法,正是利用了这一点,让AbstractList是实现接口中一些通用的方法。
而具体的类,如ArrayList就继承这个AbstractList类,拿到一些通用的方法,然后自己在实现一些自己特有的方法,这样一来,让代码更简洁,就继承结构最底层的类中通用的方法都抽取出来,先一起实现了,减少重复代码。
所以一般看到一个类上面还有一个抽象类,就是这个作用。
常量属性
// 定义数组的初始容量
private static final int DEFAULT_CAPACITY = 10;
// 定义一个空的数组
private static final Object[] EMPTY_ELEMENTDATA = {};
// 定义一个默认的空数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
// 定义存储元素的数组,transient:表述序列化的时候该修饰符修饰的属性不被序列化
transient Object[] elementData; // non-private to simplify nested class access
// 数组最大容量
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// 数组中元素的个数
private int size;
// 数组被修改的次数,如添加删除元素都会加 1
protected transient int modCount = 0;
构造方法
ArrayList向我们提供了三种构造器:
- 无参构造器:public ArrayList()
- 带初始容量构造器:public ArrayList(int initialCapacity)
- 带集合参数的构造器:public ArrayList(Collection<? extends E> c)
无参构造
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
从源代码中我们可以看出,如果我们不带任何参数的去创建对象那么其内部会直接将一个默认的空数组赋值给ArrayList的数组(elementData)
带初始容量构造器
// 带参构造,initialCapacity:传入的初始容量
public ArrayList(int initialCapacity) {
// 1. 判断是否大于 0
if (initialCapacity > 0) {
// 2. 创建一个对应大小的数组
this.elementData = new Object[initialCapacity];
// 3. 是否等于 0
} else if (initialCapacity == 0) {
// 4. 赋值一个空的数组
this.elementData = EMPTY_ELEMENTDATA;
} else {
// 5. 传入的容量不合法
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
}
}
从上面两个构造器来看:
- 空参的时候
ArrayList中的数组是它:DEFAULTCAPACITY_EMPTY_ELEMENTDATA - 容量是 0 的时候
ArrayList中的数组是它:EMPTY_ELEMENTDATA
那么问题就简化到空容量和0容量的问题了,有的人会说这不一样的嘛
其实不是,这两个的区别还是蛮大的,我们一贯的思维就是不传值就是空容量数组,传值就是对应的容量数组,那我们有没有想过如果一个人他就是想创建一个容量为 0 的数组,而不是一来就给我默认扩容到 10 这个容量。
怎么样是不是有点道理了。
所以我们可以得一个结论,DEFAULTCAPACITY_EMPTY_ELEMENTDATA和EMPTY_ELEMENTDATA就是在扩容得时候区别出来到底是扩容为 10 还是从 0 开始一步步得扩容。
带集合参数的构造器
public ArrayList(Collection<? extends E> c) {
// 将传入得集合变成数组,赋值给ArrayList的数组
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// 将类型转为Object然后再次调用copyOf进行赋值
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// 传入的是空的集合,那么赋值一个容量为EMPTY_ELEMENTDATA类型的空数组
this.elementData = EMPTY_ELEMENTDATA;
}
}
在以上源码中需要注意elementData 的二次赋值,也就是Arrays.copyOf那边的逻辑,既然已经赋过值了elementData = c.toArray(),那为什么还要二次赋值?
其实关键在于toArray()方法,它返回的不是一个 Object[] ,而是 E[] 类型,意味着如果不转成 Object[] ,你想某个位置add一个Object的子类时,这个时候就会出现异常。
所以,该代码的功能就是将elementData数组中的所有元素变为Object类型,防止在向ArrayList中添加数据的时候抛错(ArrayStoreException)。
扩容方法
在介绍添加方法之前,先来介绍一下ArrayList最为重要的扩容方法。
ensureCapacityInternal(int minCapacity):数组容量判断,容量够就不做处理,容量不足就进行相应的扩容
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
我们可以看出它中间又调用了两个方法
calculateCapacity(elementData, minCapacity):确定数组容量ensureExplicitCapacity(object):进行相应的扩容
// 确定数组容量
private static int calculateCapacity(Object[] elementData, int minCapacity) {、
// 如果数组是默认的空数组
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 返回连个容量的最大值,就是DEFAULT_CAPACITY = 10
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
// 否者,数组不空,返回minCapacity
return minCapacity;
}
我们可以看出该方法有两个参数
- elementData:存放元素的数组
- minCapacity:可以放下元素的最小的容量
// 进行相应的扩容
private void ensureExplicitCapacity(int minCapacity) {
// 数组修改次数加一
modCount++;
// 计算的最小容量是否大于数组的长度
if (minCapacity - elementData.length > 0)
// 扩容
grow(minCapacity);
}
可以看出,该方法主要是判断其内部的数组是否允许再添加元素,如果容量不够则进行扩容从而保证元素的正常添加而不溢出。
那我们具体来分析一下grow(minCapacity)方法
// 真正扩容方法
private void grow(int minCapacity) {
// 获取数组的长度
int oldCapacity = elementData.length;
// 计算新得长度,新长度为旧长度的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 判断计算的新长度与传入的最小容量的大小
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 开始扩容
elementData = Arrays.copyOf(elementData, newCapacity);
}
从这个方法,我们就可以知道如果ArrayList中如果数组容量不足,则会扩容到原来的1.5倍,而具体的扩容操作这是要看Arrays.copyOf(elementData, newCapacity)这个方法的具体实现了。
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
再调用下面方法:
// 扩容方法的具体实现
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
// 创建指定长度的某种类型的数组。
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
// 调用本地方法将旧数组元素移动到新数组中
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
// 返回新数组
return copy;
}
在这里我们可以看到,它会先创建一个指定容量大小的数组,该数组就是扩容后的数组,并且需要被返回出去。
然后这个本地方法System.arraycopy()作用就是将旧数组元素移动到新数组中,注意这个方法是native方法,是C++编写的,这里使用native方法是为了追求效率,让扩容更快。
顺便再提一下ArrayList源码中多个方法用到的判断数组下标合法的方法
rangeCheckForAdd(index): 检查下标时候合理,如果合理不做处理,否则抛出异常
private void rangeCheck(int index) {
// 如果传入的下标大于等于数组中的元素个数,溢出
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
添加方法
有了上面扩容方法的分析,add方法就会更容易理解了!
ArrayList中向我们提供了四种添加元素的方法
- 向末尾添加元素:public boolean add(E e)
- 指定位置添添加元素:public void add(int index, E element)
- 添加一个集合元素:public boolean addAll(Collection<? extends E> c)
- 在指定位置添加集合元素:public boolean addAll(int index, Collection<? extends E> c)
add(E e)
public boolean add(E e) {
// 确保数组容量
ensureCapacityInternal(size + 1); // Increments modCount!!
// 在数组末尾添加元素
elementData[size++] = e;
// 返回添加成功
return true;
}
ensureCapacityInternal这个方法已经分析过了,它会确保我们添加元素的时候容量是充足的,然后就会直接添加元素到数组末尾,最后再返回成功标识。
在这里,我们也可以解释ArrayList为什么可以添加重复的值并且输出的值与我们输入的值顺序一致的问题。
add(int index, E element)
public void add(int index, E element) {
// 1. 检查下标
rangeCheckForAdd(index);
// 2. 保证容量
ensureCapacityInternal(size + 1); // Increments modCount!!
// 3. 开始移动元素,空出指定下标的位置出来
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
// 4. 在指定下标出赋值
elementData[index] = element;
// 5. 数组元素值加 1
size++;
}
addAll(Collection<? extends E> c)
// 添加一个集合到数组中
public boolean addAll(Collection<? extends E> c) {
// 将集合转为数组
Object[] a = c.toArray();
// 获取数组长度
int numNew = a.length;
// 保证容量
ensureCapacityInternal(size + numNew); // Increments modCount
// 开始向目标数组中,添加元素
System.arraycopy(a, 0, elementData, size, numNew);
// 设置元素个数
size += numNew;
// 返回结果
return numNew != 0;
}
向ArrayList中直接添加一个集合方法中我们可以看出集合元素会直接添加在末尾,和add方法基本类似。
addAll(int index, Collection<? extends E> c)
public boolean addAll(int index, Collection<? extends E> c) {
// 1. 检查下标
rangeCheckForAdd(index);
// 2. 将集合转为数组
Object[] a = c.toArray();
// 3. 获取数组长度
int numNew = a.length;
// 4. 保证容量
ensureCapacityInternal(size + numNew); // Increments modCount
// 5. 计算需要移动元素的开始下标
int numMoved = size - index;
if (numMoved > 0)
// 6. 开始移动元素
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
// 7. 开始向目标数组中添加元素
System.arraycopy(a, 0, elementData, index, numNew);
// 8. 设置元素个数
size += numNew;
// 9. 返回结果
return numNew != 0;
}
在指定下标处添加一个集合的元素,关键点在于要计算出一个区间的下标出来,存放添加的集合数据,该实现代码在步骤5,6处可以看出。
设置方法
public E set(int index, E element) {
// 检查下标
rangeCheck(index);
// 获取对应下标数据
E oldValue = elementData(index);
// 在对应下标处赋值
elementData[index] = element;
// 返回原始数据
return oldValue;
}
获取方法
public E get(int index) {
// 检查下标
rangeCheck(index);
// 返回对应下标值
return elementData(index);
}
移除方法
对于移除方法,ArrayList中提供了挺多的,分析几个常用的。
remove(int index)
public E remove(int index) {
// 检查下标
rangeCheck(index);
// 修改次数加一
modCount++;
// 获取对应下标值
E oldValue = elementData(index);
// 计算开始移动元素的下标
int numMoved = size - index - 1;
if (numMoved > 0)
// 开始移动元素
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
// 将数组最后元素置空,并且将元素大小减一
elementData[--size] = null; // clear to let GC do its work
// 返回旧元素
return oldValue;
}
remove(Object o)
// 根据元素移除对应的数据
public boolean remove(Object o) {
if (o == null) {
// 遍历,移除null的元素
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
// 移除
fastRemove(index);
// 返回成功
return true;
}
} else {
// 遍历,移除对应元素
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
// 移除
fastRemove(index);
// 返回成功
return true;
}
}
// 返回失败
return false;
}
方法中调用fastRemove方法移除
// 移除第一个遇到的相等的值
private void fastRemove(int index) {
// 修改次数加一
modCount++;
// 计算需要移动的开始下标
int numMoved = size - index - 1;
if (numMoved > 0)
// 开始将元素向前移动
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
// 最后的元素置为空
elementData[--size] = null; // clear to let GC do its work
}
从以上源码中我们可以知道,它只会移除第一个与对应的值相同的元素。
removeAll(Collection<?> c)
public boolean removeAll(Collection<?> c) {
// 判断集合时候为null
Objects.requireNonNull(c);
// 批量移除
return batchRemove(c, false);
}
移除ArrayList中对应集合中的元素,共分为两个步骤:
- 判断入参是否为null
- 开始批量移除
判断为null方法
public static <T> T requireNonNull(T obj) {
if (obj == null)
throw new NullPointerException();
return obj;
}
这个非常简单,就是简单的判空,如空则抛出空指针
批量移除方法
private boolean batchRemove(Collection<?> c, boolean complement) {
// 定义一个指向元素数组的对象
final Object[] elementData = this.elementData;
int r = 0, w = 0;
boolean modified = false;
try {
// 开始遍历
for (; r < size; r++)
// 如果要删除的集合中,不存在ArrayList中的元素
if (c.contains(elementData[r]) == complement)
// 将集合中的元素放入elementData中,complement=true就是放入存在的元素,否者就是不存在的元素
// w是元素个数
elementData[w++] = elementData[r];
} finally {
// c.contains()会抛出异常
// 在c.contains()抛出异常的时候将异常抛出之前确定的元素进行处理
if (r != size) {
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
if (w != size) {
// 将 w 下标以后的元素置空,方便垃圾回收,w下标以前的元素就是我们需要的结果
for (int i = w; i < size; i++)
elementData[i] = null;
// 记录修改次数
modCount += size - w;
// 元素个数
size = w;
// 成功
modified = true;
}
}
return modified;
}
清除方法
public void clear() {
modCount++;
// clear to let GC do its work
for (int i = 0; i < size; i++)
// 赋空
elementData[i] = null;
// 元素个数设为 0
size = 0;
}
elementData数组被修饰transient问题
ArrayList是支持序列化的,那为什么其中关键的存储元素的数组要被修饰成transient(序列化时忽略该数组),矛盾了。
其实不然,我们点进源码可以发现,ArrayList中自己重写了序列化和反序列化的方法,代码如下:
// 序列化
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
// 反序列化
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
那为什么要自己实现一套序列化呢!
ArrayList底层是基于动态数组实现的,数组的长度是动态变化的,当数组的长度扩容到很大的时候,其中的元素却是寥寥几个的话,那要是将这些没有用的空元素也序列化到内存中就比较浪费内存。
所以就是考虑到这一点,ArrayList才会自己实现一套序列化标准,只序列化有用的元素,这样可以节省空间。
至此,ArrayList的源码就全部分析完毕啦!
ArrayList源码解析-JDK18的更多相关文章
- ArrayList源码解析
ArrayList简介 ArrayList定义 1 public class ArrayList<E> extends AbstractList<E> implements L ...
- 顺序线性表 ---- ArrayList 源码解析及实现原理分析
原创播客,如需转载请注明出处.原文地址:http://www.cnblogs.com/crawl/p/7738888.html ------------------------------------ ...
- 面试必备:ArrayList源码解析(JDK8)
面试必备:ArrayList源码解析(JDK8) https://blog.csdn.net/zxt0601/article/details/77281231 概述很久没有写博客了,准确的说17年以来 ...
- ArrayList源码解析(二)
欢迎转载,转载烦请注明出处,谢谢. https://www.cnblogs.com/sx-wuyj/p/11177257.html 自己学习ArrayList源码的一些心得记录. 继续上一篇,Arra ...
- Java中的容器(集合)之ArrayList源码解析
1.ArrayList源码解析 源码解析: 如下源码来自JDK8(如需查看ArrayList扩容源码解析请跳转至<Java中的容器(集合)>第十条):. package java.util ...
- Collection集合重难点梳理,增强for注意事项和三种遍历的应用场景,栈和队列特点,数组和链表特点,ArrayList源码解析, LinkedList-源码解析
重难点梳理 使用到的新单词: 1.collection[kəˈlekʃn] 聚集 2.empty[ˈempti] 空的 3.clear[klɪə(r)] 清除 4.iterator 迭代器 学习目标: ...
- ArrayList源码解析--值得深读
ArrayList源码解析 基于jdk1.8 ArrayList的定义 类注释 允许put null值,会自动扩容: size isEmpty.get.set.add等方法时间复杂度是O(1): 是非 ...
- 【源码解析】- ArrayList源码解析,绝对详细
ArrayList源码解析 简介 ArrayList是Java集合框架中非常常用的一种数据结构.继承自AbstractList,实现了List接口.底层基于数组来实现动态容量大小的控制,允许null值 ...
- ArrayList源码解析(一)
源码解析系列主要对Java的源码进行详细的说明,由于水平有限,难免出现错误或描述不准确的地方,还请大家指出. 1.位置 ArrayList位于java.util包中. package java.uti ...
- Java集合-ArrayList源码解析-JDK1.8
◆ ArrayList简介 ◆ ArrayList 是一个数组队列,相当于 动态数组.与Java中的数组相比,它的容量能动态增长.它继承于AbstractList,实现了List, RandomAcc ...
随机推荐
- pikachu 基于表单的暴力破解(一)
Burte Force(暴力破解)概述 "暴力破解"是一攻击具手段,在web攻击中,一般会使用这种手段对应用系统的认证信息进行获取. 其过程就是使* 用大量的认证信息在认证接口进行 ...
- AvaloniaUI项目离线开发全攻略:IDE安装、模板应用与NuGet私有化部署一站式解决
1. 引言 在网络受限或完全离线的环境中开发.NET项目(本文示例为Avalonia UI项目),可能会遇到一些挑战.本文将为您提供一套完整的离线开发解决方案,包括IDE的安装.Avalonia UI ...
- 全链路追踪 & 性能监控工具 SkyWalking 实战
Skywalking介绍 Skywalking是一个国产的开源框架,2015年有吴晟个人开源,2017年加入Apache孵化器,国人开源的产品,主要开发人员来自于华为,2019年4月17日Apache ...
- Nuxt.js 应用中的 nitro:build:public-assets 事件钩子详解
title: Nuxt.js 应用中的 nitro:build:public-assets 事件钩子详解 date: 2024/11/5 updated: 2024/11/5 author: cmdr ...
- games101_Homework3
在Raster部分实现数值插值,然后实现四种不同的像素着色器 作业描述: 作业1:修改函数 rasterize_triangle(const Triangle& t) in rasterize ...
- MudBlazor:基于Material Design风格开源且强大的Blazor组件库
项目介绍 MudBlazor是一个基于Material Design风格开源.免费(MIT License).功能强大的Blazor组件框架,注重易用性和清晰的结构.它非常适合想要快速构建Web应用程 ...
- 前段生成二维码下载,打印 QrCode
首先引用js,一个是生成二维码一个是调用打印 2.直接上代码 <div class="container-div"> <div id="qrcodeCa ...
- js+jquery实现贪吃蛇经典小游戏
项目只使用到了html,css,js,jquery技术点,没有使用游戏框架,下载本地直接双击index.html 运行即可体验游戏效果. 项目展示 进入游戏 游戏开始 游戏暂停 html文件 < ...
- 曲线救国--访问dockerhub仓库
前言 由于dockerhub也被墙了,导致基础镜像没法拉取.后面解封了,又被墙了... 在这次被墙之前,访问国外的速度也是堪忧,甚至访问不了k8s的镜像,基于此,分享一下笔者经验 使用Daocloud ...
- 关于ConditionalOnClass注解
1. pom文件<optional>标签 在Java开发中,大家肯定在pom文件中添加过依赖(现在没有,以后也肯定会有的),不知道大家对<optional>标签的了解有多少,或 ...