python爬虫基础18-Chrome调试前端工具
01 Chrome调试
抓包工具原理
Chrome 开发者工具是一套内置在Google Chrome中Web开发和调试工具。使用开发者工具来重演,调试和剖析您的网站。
其中常用的有Elements(元素面板)、Console(控制台面板)、Sources(源代码面板)、Network(网络面板)。

设置断点
使用断点来暂停JavaScript代码,审查变量的值和在特定时刻所调用的堆栈。
设置断点的最基本的方法是在特定的代码行上手动添加一个断点。也可以将这些断点配置为仅在满足特定条件时触发。
例如事件,DOM更改。
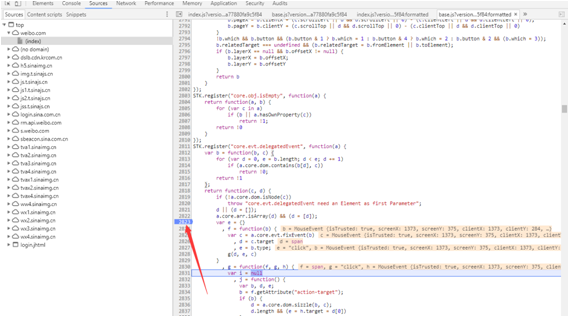
在源代码的左侧,您可以看到行号。这个区域称为line number gutter(行号槽)。单击行号槽中的行号,就会在该行代码上添加一个断点。
监测DOM变化的断点
DOM断点分为三种:
1.Subtree Modifications(子树修改) - 当当前选定节点的子节点被删除,添加或子节点的内容发生更改时触发。当子节点属性改变时,或当前选择的节点发生任何改变,都不会触发该类型的断点。
2.Attributes modifications(属性修改) - 当在当前选定的节点上添加或删除属性时,或当属性值改变时触发。
3.Node Removal(节点删除) -当当前选定的节点被删除时触发。
设置方法:在HTML元素上右键单击,然后选择Break on>Subtree Modifications(子树修改)。节点左侧的蓝色图标 DOM断点图标 表示在该节点上设置了DOM断点。
事件触发断点
当某事件(例如,click(点击))或事件类别(例如,任何mouse(鼠标)事件)被触发时,使用Sources(源文件)面板上的Event Listener Breakpoints(事件侦听器断点)窗格中断。
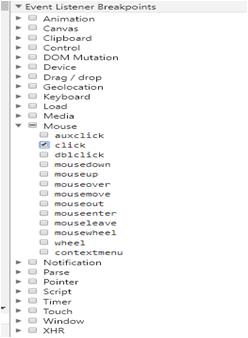
逐步调试功能
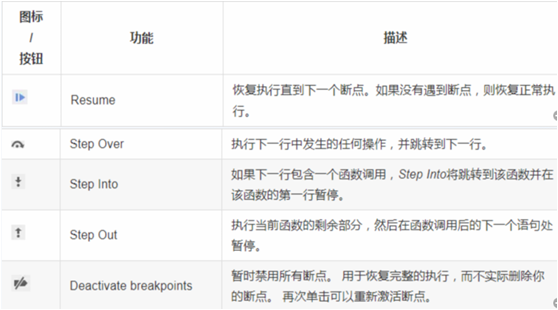
作用域
当脚本中断的时候,Scope(作用域)窗格将显示当前时刻所有当前定义的属性。
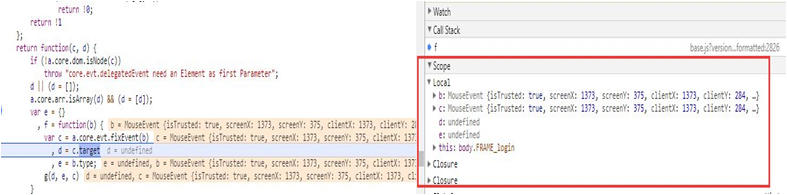
调用堆栈
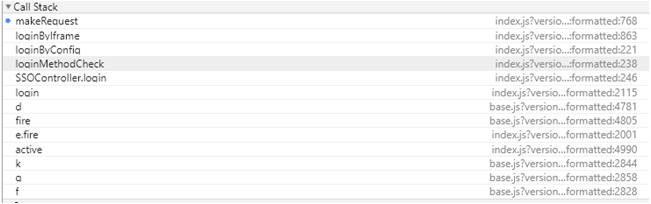
靠近边栏顶部的是Call Stack(调用堆栈)窗格。当代码在断点处暂停时,Call Stack(调用堆栈)窗格显示执行路径,按时间逆序,将代码带到该断点。这有助于理解现在执行到哪里,它是如何到达这里的,是调试的一个重要因素。
python爬虫基础18-Chrome调试前端工具的更多相关文章
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- Python爬虫基础(一)——HTTP
前言 因特网联系的是世界各地的计算机(通过电缆),万维网联系的是网上的各种各样资源(通过超文本链接),如静态的HTML文件,动态的软件程序······.由于万维网的存在,处于因特网中的每台计算机可以很 ...
- Python爬虫基础之认识爬虫
一.前言 爬虫Spider什么的,老早就听别人说过,感觉挺高大上的东西,爬网页,爬链接~~~dos黑屏的数据刷刷刷不断地往上冒,看着就爽,漂亮的校花照片,音乐网站的歌曲,笑话.段子应有尽有,全部都过来 ...
- 小白学 Python 爬虫(18):Requests 进阶操作
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- Python爬虫基础之requests
一.随时随地爬取一个网页下来 怎么爬取网页?对网站开发了解的都知道,浏览器访问Url向服务器发送请求,服务器响应浏览器请求并返回一堆HTML信息,其中包括html标签,css样式,js脚本等.我们之前 ...
随机推荐
- 关于EasyML的使用
一.安装IntelliJ Idea 具体安装过程比较简单.但是遇到一个问题,如今LInux版本的IntelliJ的安装需要jdk1.8及以上版本的支持,但是EasyML目前仅支持jdk1.7的环境. ...
- spirngmvc整合mybatis
一.建立一张简单的User表 CREATE TABLE `users` (`id` int(20) NOT NULL AUTO_INCREMENT,`name` varchar(20) NOT NUL ...
- CentOS7.5 搭建mycat1.6.6
1.环境及版本 操作系统: CentOS 7.5 数据库:MySQL 5.7.23 jdk:1.8.0_191 mycat:1.6.6.1 cat /etc/centos-release mysq ...
- Windows3
windows安装后的配置 没有网络适配器, 将USB中的驱动精灵的安装程序安装在win上, 启动精灵, 提示无法连接到网络, 使用Android类型的手机中的QQ浏览器扫码下载 win会有一些开机自 ...
- AJPFX浅析Java数组
数组(array)是相同类型变量的集合,可以使用共同的名字引用它.数组可被定义为任何类型,可以是一维或多维.数组中的一个特别要素是通过下标来访问它.数组提供了一种将有联系的信息分组的便利方法.注意:如 ...
- CF1166C A Tale of Two Lands
思路: 搞了半天发现和绝对值无关. http://codeforces.com/blog/entry/67081 实现: #include <bits/stdc++.h> using na ...
- restful之http讲解
HTTP(HyperText Transfer Protocol)是一套计算机通过网络进行通信的规则.计算机专家设计出HTTP,使HTTP客户(如Web浏览器)能够从HTTP服务器(Web服务器)请求 ...
- Appium基础三:Appium实现原理
1.web自动化测试用的selenium webdriver 是c/s模式,server端和client端是通过webdriver protocol实现的,而Appium是参考selenium开发的, ...
- Python3+Selenium3+webdriver学习笔记10(元素属性、页面源码)
#!/usr/bin/env python# -*- coding:utf-8 -*-'''Selenium3+webdriver学习笔记10(元素属性.页面源码)'''from selenium i ...
- python爬虫之路——初识函数与控制语句
介绍python函数的定义与使用方法,介绍Python的常用控制语句:判断和循环 函数: 格式 def 函数名(参数1,参数2): return ‘结果’ 判断语句:就是多选一 二选一: if c ...