selenium+谷歌无头浏览器爬取网易新闻国内板块
网页分析
首先来看下要爬取的网站的页面
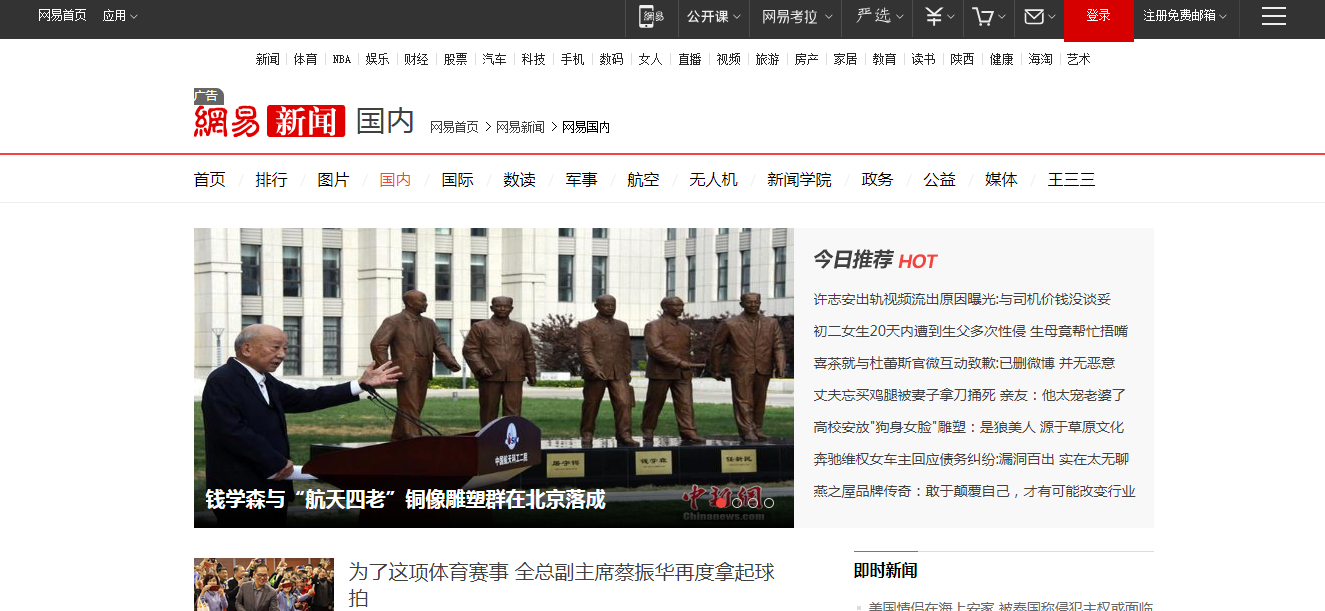
查看网页源代码:你会发现它是由js动态加载显示的
所以采用selenium+谷歌无头浏览器来爬取它
1 加载网站,并拖动到底,发现其还有个加载更多
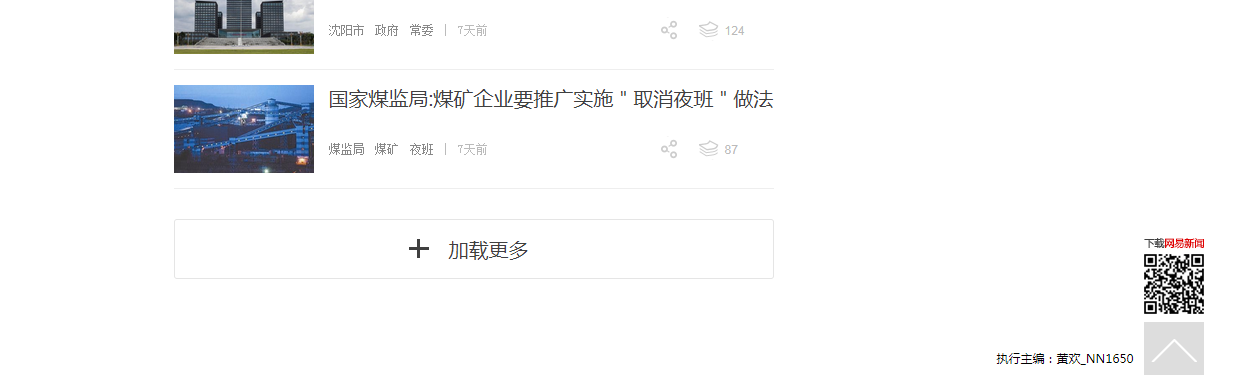
2 模拟点击它,然后再次拖动到底,,就可以加载完整个页面
示例代码
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from time import sleep
from lxml import etree
import os
import requests # 使用谷歌无头浏览器来加载动态js
def main():
# 创建一个无头浏览器对象
chrome_options = Options()
# 设置它为无框模式
chrome_options.add_argument('--headless')
# 如果在windows上运行需要加代码
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(chrome_options=chrome_options)
# 设置一个10秒的隐式等待
browser.implicitly_wait(10)
browser.get(url)
sleep(1)
# 翻到页底
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
# 点击加载更多
browser.find_element(By.CSS_SELECTOR, '.load_more_btn').click()
sleep(1)
# 再次翻页到底
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
# 拿到页面源代码
source = browser.page_source
browser.quit()
with open('xinwen.html', 'w', encoding='utf-8') as f:
f.write(source)
parse_page(source) # 对新闻列表页面进行解析
def parse_page(html):
# 创建etree对象
tree = etree.HTML(html)
new_lst = tree.xpath('//div[@class="ndi_main"]/div')
for one_new in new_lst:
title = one_new.xpath('.//div[@class="news_title"]/h3/a/text()')[0]
link = one_new.xpath('.//div[@class="news_title"]/h3/a/@href')[0]
write_in(title, link) # 将其写入到文件
def write_in(title, link):
print('开始写入篇新闻{}'.format(title))
response = requests.get(url=link, headers=headers)
tree = etree.HTML(response.text)
content_lst = tree.xpath('//div[@class="post_text"]//p')
title = title.replace('?', '')
with open('new/' + title + '.txt', 'a+', encoding='utf-8') as f:
for one_content in content_lst:
if one_content.text:
con = one_content.text.strip()
f.write(con + '\n') if __name__ == '__main__':
url = 'https://news.163.com/domestic/'
headers = {"User-Agent": 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0'}
if not os.path.exists('new'):
os.mkdir('new')
main()
得到结果:
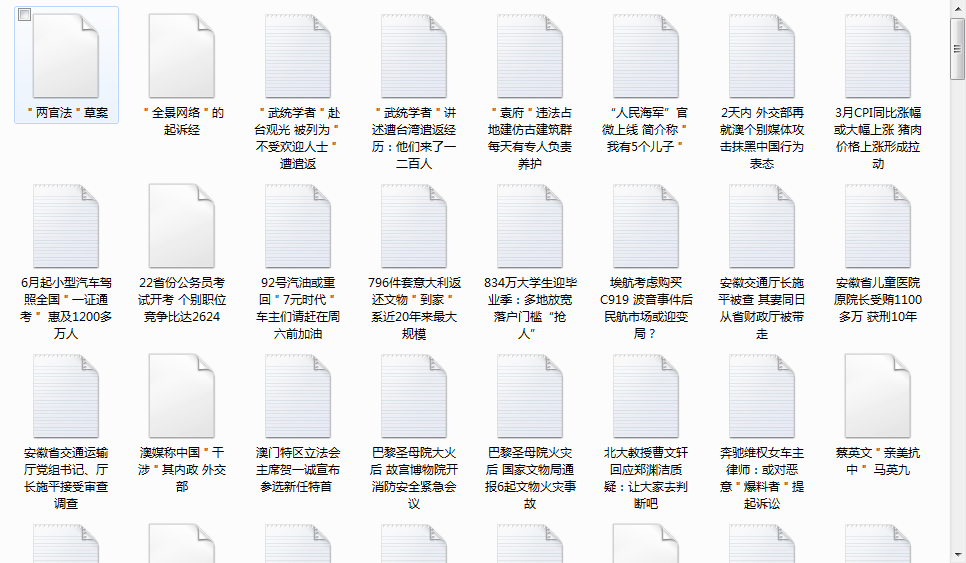
随意打开一个txt:

Scrapy版
wangyi.py
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from happy1.items import Happy1Item class WangyiSpider(scrapy.Spider):
name = 'wangyi'
# allowed_domains = ['https://news.163.com/domestic/']
start_urls = ['http://news.163.com/domestic/'] def __init__(self):
# 创建一个无头浏览器对象
chrome_options = Options()
# 设置它为无框模式
chrome_options.add_argument('--headless')
# 如果在windows上运行需要加代码
chrome_options.add_argument('--disable-gpu')
# 示例话一个浏览器对象(实例化一次)
self.bro = webdriver.Chrome(chrome_options=chrome_options) def parse(self, response):
new_lst = response.xpath('//div[@class="ndi_main"]/div')
for one_new in new_lst:
item = Happy1Item()
title = one_new.xpath('.//div[@class="news_title"]/h3/a/text()')[0].extract()
link = one_new.xpath('.//div[@class="news_title"]/h3/a/@href')[0].extract()
item['title'] = title
yield scrapy.Request(url=link,callback=self.parse_detail, meta={'item':item}) def parse_detail(self, response):
item = response.meta['item']
content_list = response.xpath('//div[@class="post_text"]//p/text()').extract()
item['content'] = content_list
yield item # 在爬虫结束后,关闭浏览器
def close(self, spider):
print('爬虫结束')
self.bro.quit()
pipelines.py
class Happy1Pipeline(object):
def __init__(self):
self.fp = None def open_spider(self, spider):
print('开始爬虫') def process_item(self, item, spider):
title = item['title'].replace('?', '')
self.fp = open('news/' + title + '.txt', 'a+', encoding='utf-8')
for one in item['content']:
self.fp.write(one.strip() + '\n')
self.fp.close()
return item
items.py
import scrapy class Happy1Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()
middlewares.py
def process_response(self, request, response, spider):
if request.url in ['http://news.163.com/domestic/']:
spider.bro.get(url=request.url)
time.sleep(1)
spider.bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
spider.bro.find_element(By.CSS_SELECTOR, '.load_more_btn').click()
time.sleep(1)
spider.bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
page_text = spider.bro.page_source
return HtmlResponse(url=spider.bro.current_url, body=page_text, encoding='utf-8', request=request)
else:
return response
settings.py
DOWNLOADER_MIDDLEWARES = {
'happy1.middlewares.Happy1DownloaderMiddleware': 543,
}
ITEM_PIPELINES = {
'happy1.pipelines.Happy1Pipeline': 300,
}
得到结果

总结:
1 其实主要的工作还是模拟浏览器来进行操作。
2 处理动态的js其实还有其他办法。
3 爬虫的方法有好多种,主要还是选择适合自己的。
4 自己的代码写的太烂了。
selenium+谷歌无头浏览器爬取网易新闻国内板块的更多相关文章
- 如何利用python爬取网易新闻
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: LSGOGroup PS:如有需要Python学习资料的小伙伴可以 ...
- Python爬虫实战教程:爬取网易新闻
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Amauri PS:如有需要Python学习资料的小伙伴可以加点击 ...
- Python爬虫实战教程:爬取网易新闻;爬虫精选 高手技巧
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. stars声明很多小伙伴学习Python过程中会遇到各种烦恼问题解决不了.为 ...
- Python 爬虫实例(4)—— 爬取网易新闻
自己闲来无聊,就爬取了网易信息,重点是分析网页,使用抓包工具详细的分析网页的每个链接,数据存储在sqllite中,这里只是简单的解析了新闻页面的文字信息,并未对图片信息进行解析 仅供参考,不足之处请指 ...
- 爬虫之 图片懒加载, selenium , phantomJs, 谷歌无头浏览器
一.图片懒加载 懒加载 : JS 代码 是页面自然滚动 window.scrollTo(0,document.body.scrollHeight) (重点) bro.execute_ ...
- Selenium+Chrome/phantomJS模拟浏览器爬取淘宝商品信息
#使用selenium+Carome/phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏 ...
- 爬虫之selenium模块;无头浏览器的使用
一,案例 爬取站长素材中的图片:http://sc.chinaz.com/tupian/gudianmeinvtupian.html import requests from lxml import ...
- 利用scrapy抓取网易新闻并将其存储在mongoDB
好久没有写爬虫了,写一个scrapy的小爬爬来抓取网易新闻,代码原型是github上的一个爬虫,近期也看了一点mongoDB.顺便小用一下.体验一下NoSQL是什么感觉.言归正传啊.scrapy爬虫主 ...
- Python实训day07pm【Selenium操作网页、爬取数据-下载歌曲】
练习1-爬取歌曲列表 任务:通过两个案例,练习使用Selenium操作网页.爬取数据.使用无头模式,爬取网易云的内容. ''' 任务:通过两个案例,练习使用Selenium操作网页.爬取数据. 使用无 ...
随机推荐
- composer安装以及更新问题,配置中国镜像源。
配置国内镜像源 中国镜像源 https://pkg.phpcomposer.com/ composer 中文官网地址 http://www.phpcomposer.com/ 下载 Composer 安 ...
- eclipse如何新建项目发布到git
1.首先去查询本地git仓库地址 2.找到项目位置 删除git版本 3.更换git提交目标地址 目标地址是新建的git仓库地址 4.提交
- AES在线加密解密-附AES128,192,256,CBC,CFB,ECB,OFB,PCBC各种加密解密源码
一.AES在线加密解密:AES 128/192/256位CBC/CFB/ECB/OFB/PCBC在线加密解密|在线工具|在线助手|在线生成|在线制作 http://www.it399.com/aes ...
- 关于<input type="date">这种取值的问题 【原创】
举例 <input type="date" id="date1"> var num = $("#date1").val(); a ...
- selenium chromedriver与谷歌浏览器版本映射表
chromedriver版本 支持的Chrome版本 v2.35 v62-64 v2.34 v61-63 v2.33 v60-62 v2.32 v59-61 v2.31 v58-60 v2.30 v5 ...
- vue 实践记录
打包后使用相对路径 在 build/webpack.prod.conf.js 的 output 节点添加配置:publicPath: './' 打包时使用shell复制文件 在入口 build/bui ...
- session.go
package { so.ttl = ttl } } } // WithContext assigns a context to the session ...
- bzoj5342 CTSC2018 Day1T3 青蕈领主
首先显然的是,题中所给出的n个区间要么互相包含,要么相离,否则一定不合法. 然后我们可以对于直接包含的关系建出一棵树,于是现在的问题就是给n个节点分配权值,使其去掉最后一个点后不存在非平凡(长度大于1 ...
- bzoj 3167 SAO
树dp 定义f[i][j]为i在其已合并子树内排名为j的方案数 O(n2)进行子树合并 转移时枚举他在已合并子树中的排名j和新合并子树中的排名k+1 当他比他儿子大的时候$f[x][j+k]=f[x] ...
- WPF 列表开启虚拟化的方式
正确开启虚拟化的方式 列表如ListBox,ListView,TreeView,GridView等,开启虚拟化 ScrollViewer设置CanContentScroll=True 直接在模板中,设 ...