爬虫(十三):scrapy中pipeline的用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理
每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或者被丢弃而不再进行处理
item pipeline的主要作用:
- 清理html数据
- 验证爬取的数据
- 去重并丢弃
- 讲爬取的结果保存到数据库中或文件中
编写自己的item pipeline
process_item(self,item,spider)
每个item piple组件是一个独立的pyhton类,必须实现以process_item(self,item,spider)方法
每个item pipeline组件都需要调用该方法,这个方法必须返回一个具有数据的dict,或者item对象,或者抛出DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理
下面的方法也可以选择实现
open_spider(self,spider)
表示当spider被开启的时候调用这个方法
close_spider(self,spider)
当spider挂去年比时候这个方法被调用
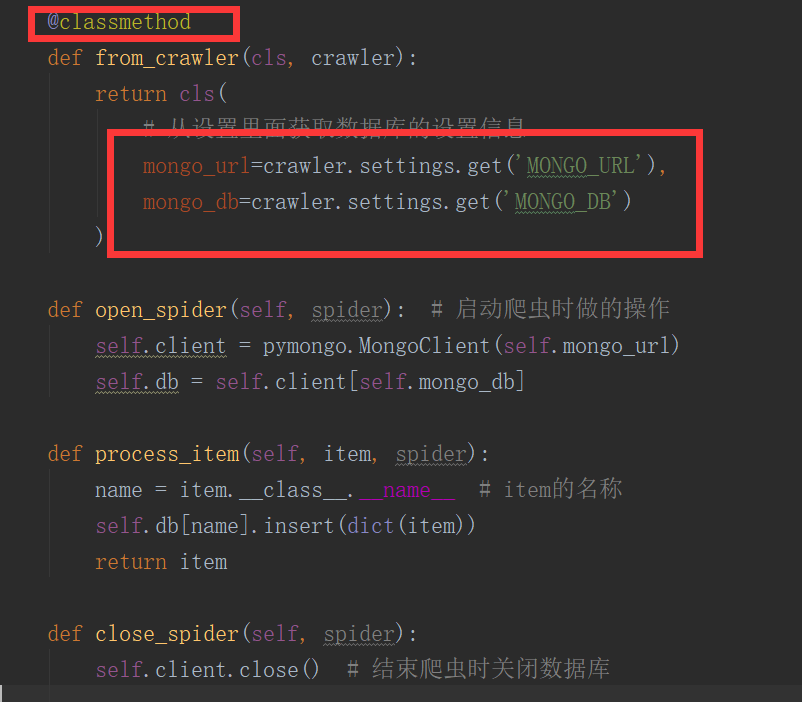
from_crawler(cls,crawler)
这个和我们在前面说spider的时候的用法是一样的,可以用于获取settings配置文件中的信息,需要注意的这个是一个类方法,用法例子如下:
一些item pipeline的使用例子(官网说明)
例子1
这个例子实现的是判断item中是否包含price以及price_excludes_vat,如果存在则调整了price属性,都让item['price'] = item['price'] * self.vat_factor,如果不存在则返回DropItem
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item['price']:
if item['price_excludes_vat']:
item['price'] = item['price'] * self.vat_factor
return item
else:
raise DropItem("Missing price in %s" % item)
例子2
这个例子是将item写入到json文件中
import json
class JsonWriterPipeline(object):
def __init__(self):
self.file = open('items.jl', 'wb')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
例子3
将item写入到MongoDB,同时这里演示了from_crawler的用法
import pymongo
class MongoPipeline(object):
collection_name = 'scrapy_items'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert(dict(item))
return item
例子4:去重
一个用于去重的过滤器,丢弃那些已经被处理过的item,假设item有一个唯一的id,但是我们spider返回的多个item中包含了相同的id,去重方法如下:这里初始化了一个集合,每次判断id是否在集合中已经存在,从而做到去重的功能
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
启用一个item Pipeline组件
在settings配置文件中y9ou一个ITEM_PIPELINES的配置参数,例子如下:
ITEM_PIPELINES = {
'myproject.pipelines.PricePipeline': 300,
'myproject.pipelines.JsonWriterPipeline': 800,
}
每个pipeline后面有一个数值,这个数组的范围是0-1000,这个数值确定了他们的运行顺序,数字越小越优先
爬虫(十三):scrapy中pipeline的用法的更多相关文章
- python爬虫之scrapy的pipeline的使用
scrapy的pipeline是一个非常重要的模块,主要作用是将return的items写入到数据库.文件等持久化模块,下面我们就简单的了解一下pipelines的用法. 案例一: items池 cl ...
- 爬虫(十二):scrapy中spiders的用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- scrapy中pipeline的一点综合知识
初次学习scrapy ,觉得spider代码才是最重要的,越往后学,发现pipeline中的代码也很有趣, 今天顺便把pipeline中三种储存方法写下来,算是对自己学习的一点鼓励吧,也可以为后来者的 ...
- 爬虫(scrapy中的ImagesPipeline)
在使用ImagesPipeline对妹子图网站图片进行下载时,遇到302错误,页面被强制跳转. 解决办法如下: # -*- coding: utf-8 -*- # Define your item p ...
- 爬虫(scrapy中调试文件)
在项目setting同级目录下创建py文件,代码如下: from scrapy.cmdline import execute import sys import os sys.path.append( ...
- Scrapy中选择器的用法
官方文档:https://doc.scrapy.org/en/latest/topics/selectors.html Using selectors Constructing selectors R ...
- 18.scrapy中selector的用法
Selector是一个独立的模块. Selector主要是与scrapy结合使用的. 开启Scrapy shell: 1.打开命令行cmd 2.scrapy shell http://doc.scra ...
- scrapy中对于item的把控
其实很简单,就是想要存储的位置发生改变.直接看例子,然后触类旁通. 以大众点评 评论的内容为例 ,位置:http://www.dianping.com/shop/77489519/review_mor ...
- Python爬虫从入门到放弃(十七)之 Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
随机推荐
- C++11(及现代C++风格)和快速迭代式开发
过去的一年我在微软亚洲研究院做输入法,我们的产品叫“英库拼音输入法” (下载Beta版),如果你用过“英库词典”(现已更名为必应词典),应该知道“英库”这个名字(实际上我们的核心开发团队也有很大一部分 ...
- Python——pip的安装与使用
pip 是 Python 包管理工具,该工具提供了对Python 包的查找.下载.安装.卸载的功能.目前如果你在 python.org 下载最新版本的安装包,则是已经自带了该工具.Python 2.7 ...
- 关于Vue中,父组件获取子组件的数据(子组件调用父组件函数)的方法
1. 父组件调用子组件时,在调用处传给子组件一个方法 :on-update="updateData" 2. 子组件在props中,接收这个方法并声明 props: { onUp ...
- ArduPilot存储管理 Storage EEPROM Flash
AP_HAL::Storage 此类可以应用于所有平台.PX4v1平台支持8k的EEPROM,Pixhawk平台支持16k的FRAM铁电存储器 存储大小定义:libraries/AP_HAL/AP_H ...
- 七、玩转select条件查询
前言: 电商中:我们想查看某个用户所有的订单,或者想查看某个用户在某个时间段内所有的订单,此时我们需要对订单表数据进行筛选,按照用户.时间进行过滤,得到我们期望的结果. 此时我们需要使用条件查询来对指 ...
- 【leetcode】496. Next Greater Element I
原题 You are given two arrays (without duplicates) nums1 and nums2 where nums1's elements are subset o ...
- 【20191118会议】针对华为云CCE 问题总结
针对华为云CCE问题总结 如何购买CCE集群 可以分为测试环境和生产环境,针对使用范围进行购买集群. 测试环境 可以进行公用 生产环境建议使用单独集群 尤其针对部门大 耦合性不高 ,生产环境 建议使用 ...
- JSON【1】
http://repo1.maven.org/maven2/com/fasterxml/jackson/core/ JSON[jar]包下载 JSON是什么? 是一种轻量级的数据交换格式,完全独 ...
- shell中判断前一个命令是否执行成功
]; then echo "fail" else echo "success" fi 或者 ]; then echo "success" e ...
- Codeforces Round #511 (Div. 2) C. Enlarge GCD (质因数)
题目 题意: 给你n个数a[1]...a[n],可以得到这n个数的最大公约数, 现在要求你在n个数中 尽量少删除数,使得被删之后的数组a的最大公约数比原来的大. 如果要删的数小于n,就输出要删的数的个 ...