python3 scrapy爬虫项目的诞生
前提安装好scrapy模块最好 requests和bs4模块都安装好
可以概括为五个步骤
步骤一:新建一个项目
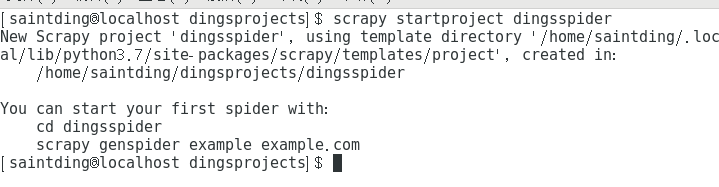
无论你用windows也好,linux也罢,在cmd或者终端 切换到目标文件夹,然后输入命令
scrapy startproject dingsspider(自定义的项目名)
步骤二:生成爬虫
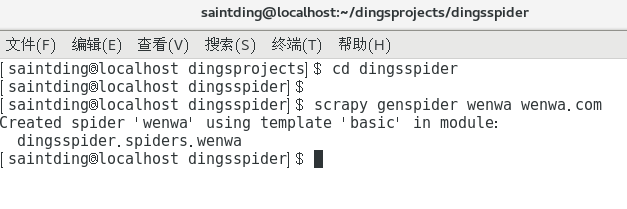
如同shell终端提示的那样,要生成爬虫
重要提示:执行命令时你有可能遇到一个错误,可能不是由于你的代码语法错误,而是来自源代码的错误,请看如下帖子
http://bbs.51cto.com/thread-1547185-1.html
解决方案截图如下:

解决上述问题后,运行命令
scrapy genspider wenwa wenwa.com
哟比~有了项目架构,我们就可以通过改写相关的爬虫类,实现爬虫的运转了
爬取一个网页,以著名编程知识网站runnoob为例,因为朕要学习php(找个python编程工作怎么就JB那么难,大爷的)
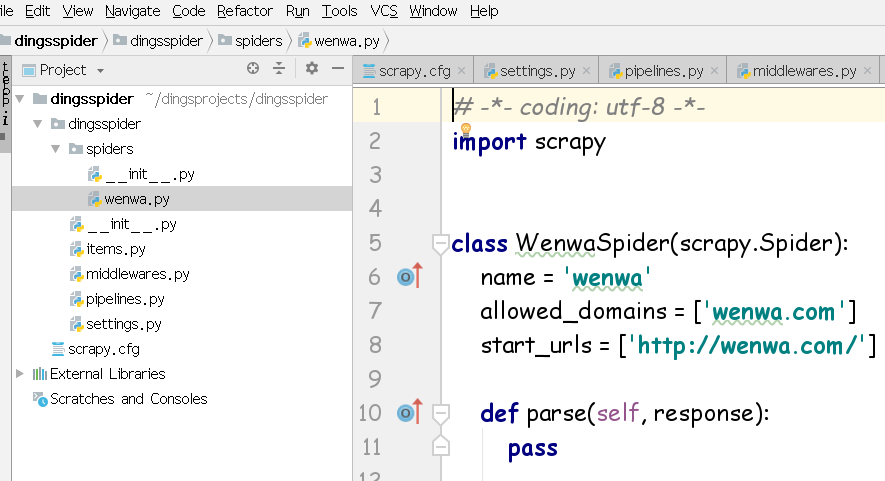
在步骤二中,已经通过genspider 命名了一个文件wenwa,那么在爬虫项目中找到同名文件wenwa.py,修改如下:
import scrapy
class WenwaSpider(scrapy.Spider):
name = 'wenwa'
allowed_domains = ['www.runoob.com']
start_urls = ['http://www.runoob.com/php/php-tutorial.html'] def parse(self, response):
filename = response.url.split("/")[-]+".html"
with open(filename,"wb") as p:
p.write(response.body)
allow_domians显示了要爬去的主域名,start_urls则是我们要爬取的页面,parse中filename完全是拆分start_urls后形成的列表里面,拿出一个元素给装载爬取结果的文件命名,如果觉得晕,随便取个名字就好
成功生成文件php.html,如下图

打开一看,瓦嗷~真tm丑,不过总算成功了,瓦卡卡
python3 scrapy爬虫项目的诞生的更多相关文章
- 在Pycharm中运行Scrapy爬虫项目的基本操作
目标在Win7上建立一个Scrapy爬虫项目,以及对其进行基本操作.运行环境:电脑上已经安装了python(环境变量path已经设置好), 以及scrapy模块,IDE为Pycharm .操作如下: ...
- 关于Scrapy爬虫项目运行和调试的小技巧(下篇)
前几天给大家分享了关于Scrapy爬虫项目运行和调试的小技巧上篇,没来得及上车的小伙伴可以戳超链接看一下.今天小编继续沿着上篇的思路往下延伸,给大家分享更为实用的Scrapy项目调试技巧. 三.设置网 ...
- 关于Scrapy爬虫项目运行和调试的小技巧(上篇)
扫除运行Scrapy爬虫程序的bug之后,现在便可以开始进行编写爬虫逻辑了.在正式开始爬虫编写之前,在这里介绍四种小技巧,可以方便我们操纵和调试爬虫. 一.建立main.py文件,直接在Pycharm ...
- Scrapy 爬虫项目框架
1. Scrapy 简介 2. Scrapy 项目开发介绍 3. Scrapy 项目代码示例 3.1 setting.py:爬虫基本配置 3.2 items.py:定义您想抓取的数据 3.3 spid ...
- python3+Scrapy爬虫使用pipeline数据保存到文本和数据库,数据少或者数据重复问题
爬取的数据结果是没有错的,但是在保存数据的时候出错了,出现重复数据或者数据少问题.那为什么会造成这种结果呢? 其原因是由于Spider的速率比较快,而scapy操作数据库操作比较慢,导致pipelin ...
- 第十六节:Scrapy爬虫框架之项目创建spider文件数据爬取
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取所设计的, 也可以应用在获取API所返回的数据或 ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(下)
前几天小编带大家学会了如何在Scrapy框架下创建属于自己的第一个爬虫项目(上),今天我们进一步深入的了解Scrapy爬虫项目创建,这里以伯乐在线网站的所有文章页为例进行说明. 在我们创建好Scrap ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- Scrapy爬虫框架第一讲(Linux环境)
1.What is Scrapy? 答:Scrapy是一个使用python语言(基于Twistec框架)编写的开源网络爬虫框架,其结构清晰.模块之间的耦合程度低,具有较强的扩张性,能满足各种需求.(前 ...
随机推荐
- 洛谷 题解 P1284 【三角形牧场】
状态: dp[i][j]表示用i和j的木板能否搭成,不用去管第三块,因为知道了两块的长度与周长,那就可以表示出第三块:c-i-j 转移 有点类似于背包 if((j-l[i]>=0&&am ...
- [转帖] 修改nginx 默认上传文件大小
nginx默认会限制上传文件的大小为1M https://blog.51cto.com/ycgit/1563307 艺晨光关注0人评论12037人阅读2014-10-13 15:29:50 htt ...
- k8s组件通信或者创建pod生命周期
Kubernetes 多组件之间的通信原理: apiserver 负责 etcd 存储的所有操作,且只有 apiserver 才直接操作 etcd 集群 apiserver 对内(集群中的其他组件)和 ...
- 训练技巧详解【含有部分代码】Bag of Tricks for Image Classification with Convolutional Neural Networks
训练技巧详解[含有部分代码]Bag of Tricks for Image Classification with Convolutional Neural Networks 置顶 2018-12-1 ...
- IDEA的常见的设置和优化(功能)
转载 原文:https://blog.csdn.net/zeal9s/article/details/83544074
- Oracle设置权限和还原数据库
Oracle还原数据库 ,在最高权限账户上,先将安装好的数据上创建一个账户 -- Create the user create user newsafe identified by newsafe d ...
- python matplotlib 折线图
1.绘制折线图,去上和右边框,显示中文 import numpy as np import matplotlib.pyplot as plt #plt.style.use('default') #pl ...
- 修改小程序checkbox样式
未选中时的样式 checkbox .wx-checkbox-input { border-radius: 50%; height: 30rpx; width: 30rpx; margin-top: - ...
- 通过hadoop上的hive完成WordCount
1.启动hadoop 打开所有命令:start-all.sh 2.Hdfs上创建文件夹 创建名为PGOne到user/hadoop 3.上传文件至hdfs 创建和修改508.txt文件,里面尽量多写一 ...
- Mac下安装Redis及Redis Desktop Manager
1.简介 Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库.缓存和消息中间件. 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表 ...