爬虫之requests库的使用
get基本请求
响应对象的属性:
# 获取响应对象中的内容是str格式
text
# 获取响应对象中的内容是二进制格式的
content
# 获取响应状态码
status_code
# 获取响应头信息
headers
# 获取请求的url
url
import requests
url = "https://www.cnblogs.com/songzhixue/p/10717975.html"
# 获得一个响应对象
response = requests.get(url=url)
# 调用响应对象中的text属性获取请求结果为字符串形式
print(response.text)
带参数的get请求
方式一:
import requests
url = "http://www.baidu.com/s?wd=周杰伦"
# requests模块可以自动将url中的汉字进行转码
response = requests.get(url).text
with open("./zhou.html","w",encoding="utf-8") as fp:
fp.write(response)
方式二:
将参数以字典的形式传给params参数
import requests
choice = input("请输入搜索条件>>>:").strip()
params = {
"wd":choice
}
# https://www.baidu.com/s?wd=周杰伦
url = "http://www.baidu.com/s?"
# 带参数的get请求
response = requests.get(url,params)
# 获取响应状态码
response.status_code
添加请求头信息
请求头以字典的方式传给headers参数
import requests
choice = input("请输入搜索条件>>>:").strip()
params = {
"wd":choice
}
# https://www.baidu.com/s?wd=周杰伦
url = "http://www.baidu.com/s?"
# 封装请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
# 带参数的get请求
response = requests.get(url,params,headers=headers)
# 获取响应状态码
response.status_code
post请求
豆瓣登录
开发者抓包工具抓取post请求的登录信息
基于Ajax的get请求
### 抓取豆瓣影评###
import json
import requests
# url = "https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=20"
# 获取ajax的请求网址(基于ajax的get请求)
url = 'https://movie.douban.com/j/search_subjects?'
# 自定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}
# 构建请求参数
params = {
'type': 'movie',
'tag': '热门',
'sort': 'recommend',
'page_limit': '1', # 显示多少数据
'page_start': '', # 从第几页开始显示
}
# 请求目标url
response = requests.get(url=url,params=params,headers=headers)
# 拿到响应数据,json格式的字符串
json_str = response.text
# 对响应数据反序列化得到字典
code = json.loads(json_str)
# 在字典中取出想要的数据
for dic in code["subjects"]:
rate = dic["rate"]
title = dic["title"]
print(title,rate)
基于Ajax的post请求
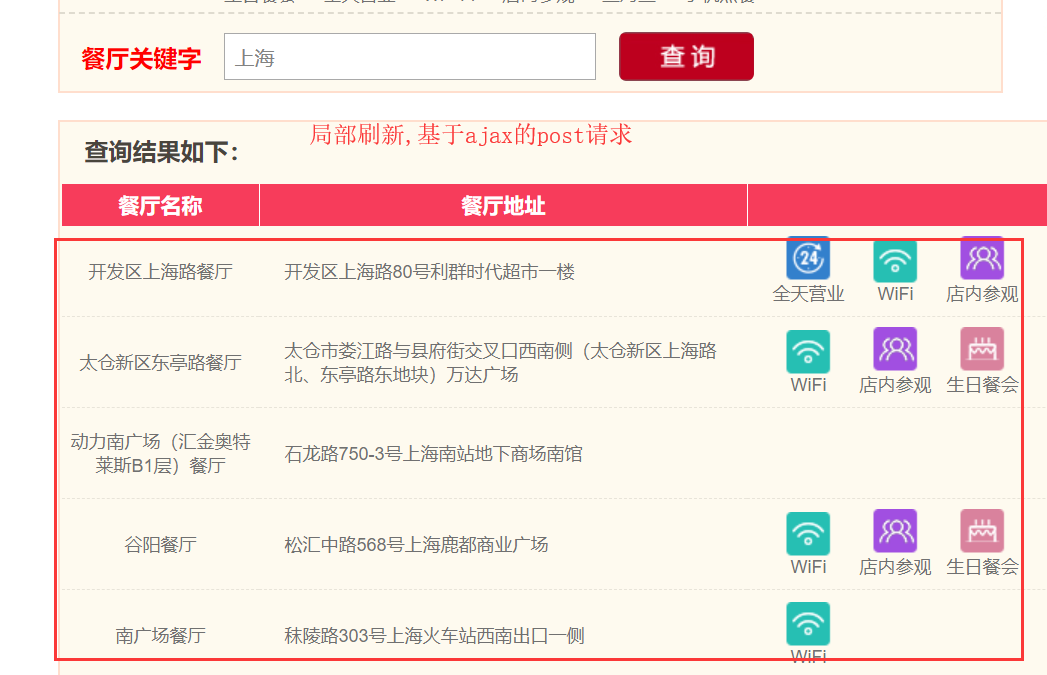
### 抓取肯德基餐厅位置信息###
import json
import requests
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
data = {
'cname': '',
'pid': '',
'keyword': '上海',# 查询城市
'pageIndex':'', # 显示第几页的数据
'pageSize': '', # 一页显示多少数据
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
response = requests.post(url=url,data=data,headers=headers)
response.text
使用代理
import requests
# www.goubanjia.com
# 快代理
# 西祠代理
url = "http://www.baidu.com/s?wd=ip"
prox = {
"http":"39.137.69.10:8080",
"http":"111.13.134.22:80",
}
# 参数proxies
response = requests.get(url=url,proxies=prox).text
with open("./daili.html","w",encoding="utf-8") as fp:
fp.write(response)
print("下载成功")
requests上传文件
https://blog.csdn.net/five3/article/details/74913742
爬虫之requests库的使用的更多相关文章
- Python爬虫之requests库介绍(一)
一:Requests: 让 HTTP 服务人类 虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 ...
- python爬虫之requests库
在python爬虫中,要想获取url的原网页,就要用到众所周知的强大好用的requests库,在2018年python文档年度总结中,requests库使用率排行第一,接下来就开始简单的使用reque ...
- 爬虫相关--requests库
requests的理想:HTTP for Humans 一.八个方法 相比较urllib模块,requests模块要简单很多,但是需要单独安装: 在windows系统下只需要在命令行输入命令 pip ...
- Python爬虫:requests 库详解,cookie操作与实战
原文 第三方库 requests是基于urllib编写的.比urllib库强大,非常适合爬虫的编写. 安装: pip install requests 简单的爬百度首页的例子: response.te ...
- Python爬虫之requests库的使用
requests库 虽然Python的标准库中 urllib模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests宣传是 "HTTP for ...
- 【Python爬虫】爬虫利器 requests 库小结
requests库 Requests 是一个 Python 的 HTTP 客户端库. 支持许多 HTTP 特性,可以非常方便地进行网页请求.网页分析和处理网页资源,拥有许多强大的功能. 本文主要介绍 ...
- 爬虫值requests库
requests简介 简介 Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库 ,使用起来比urllib简洁很多 因为是第三方库, ...
- (爬虫)requests库
一.requests库简介 urllib库和request库的作用一样,都是服务器发起请求数据,但是requests库比urllib库用起来更方便,它的接口更简单,选用哪种库看自己. 如果没有安装过这 ...
- 【Python爬虫】Requests库的基本使用
Requests库的基本使用 阅读目录 基本的GET请求 带参数的GET请求 解析Json 获取二进制数据 添加headers 基本的POST请求 response属性 文件上传 获取cookie 会 ...
- python网络爬虫之requests库
Requests库是用Python编写的HTTP客户端.Requests库比urlopen更加方便.可以节约大量的中间处理过程,从而直接抓取网页数据.来看下具体的例子: def request_fun ...
随机推荐
- k8s-secret用法
创建username和password文件: $ echo -n "admin" > ./username $ echo -n "1f2d1e2e67df" ...
- KeyValuePair<string, string>
; #region CUP Method /// <summary> /// 请求与响应的超时时间 /// </summary> static public int Timeo ...
- 【原创】大叔经验分享(77)openresty(nginx+lua)发http请求
openresty(nginx+lua)发http请求 利用location+proxy_pass间接实现 location ^~ /test/http { internal; proxy_pass ...
- uni-app的H5版使用注意事项
使用方式 打开uni-app项目下的vue文件 点击菜单 运行->运行到浏览器->Chrome 在Chrome內打开调试模式(右键->检查)开启设备模拟,模拟移动设备(如果UI变形刷 ...
- 【ASE高级软件工程】第一次结对作业
问题定义 具体规则见:讲义.大致规则如下: N个同学(N通常大于10),每人写一个0~100之间的有理数 (不包括0或100),交给裁判,裁判算出所有数字的平均值,然后乘以0.618(所谓黄金分割常数 ...
- 【SpringBoot】自动配置
一.取值 1.1 @Value 1.2 ConfigurationProperties 二.导入配置文件 2.1 @PropertySource 三.配置文件的加载 3.1 默认的加载顺序 3.2 外 ...
- vs code 开发小程序会用到的插件
主要介绍一下几个vscode插件,在vscode中搜索插件关键字点击安装即可. 1) vscode weapp api, 语法结构api; 2) minapp-vscode 3) vscode wx ...
- 01_Hive简介及其工作机制
1.Hive简介 Hive是一个基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一个表.并提供类SQL查询功能, 可以将sql语句转换为MapReduce任务运行.其优点是学习成本低, ...
- linux——目录说明
1) bin -> usr/bin : 这个目录存放最经常使用的命令 2) boot : 这个目录存放启动Linux时使用的一些核心文件,包括一些连接文件以及镜像文件 3) dev: de ...
- java 值传递还是引用传递
首先看一下这篇文章 -- 跳 这篇文章就进行了大致的介绍,以及一些简单的例子,但是还缺少一个关键的例子: public class QQ { public static void main(Strin ...