Python网络爬虫四大选择器(正则表达式、BS4、Xpath、CSS)总结
一、正则表达式
正则表达式为我们提供了抓取数据的快捷方式。虽然该正则表达式更容易适应未来变化,但又存在难以构造、可读性差的问题。当在爬京东网的时候,正则表达式如下图所示:
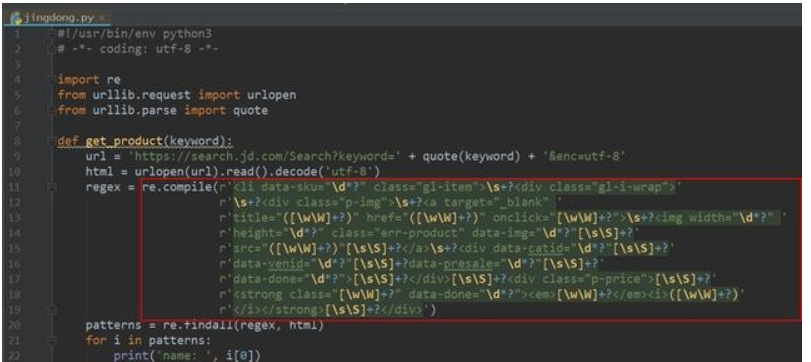
此外 ,我们都知道,网页时常会产生变更,导致网页中会发生一些微小的布局变化时,此时也会使得之前写好的正则表达式无法满足需求,而且还不太好调试。当需要匹配的内容有很多的时候,使用正则表达式提取目标信息会导致程序运行的速度减慢,需要消耗更多内存。
二、BeautifulSoup
BeautifulSoup是一个非常流行的 Pyhon 模块。该模块可以解析网页,并提供定位内容的便捷接口。通过'pip install beautifulsoup4'就可以实现该模块的安装了。
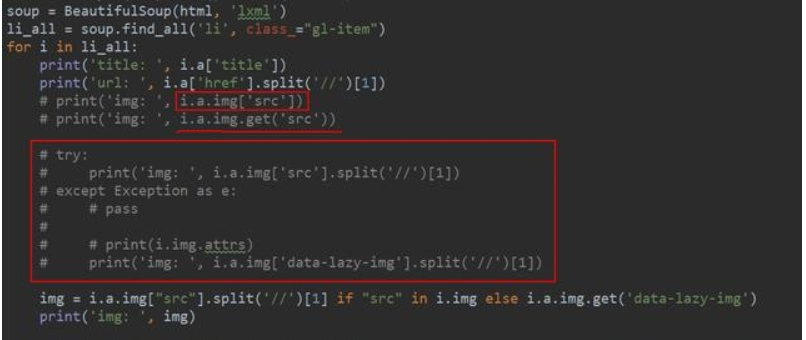
使用 BeautifulSoup的第一步是将己下载的 HTML 内容解析为 soup文档。由 于大多 数网 页都不具备良好的HTML 格式,因此BeautifulSoup需要对实际格式进行确定。BeautifulSoup能够正确解析缺失的引号并闭合标签,此外还会添加<html >和<body>标签使其成为完整的HTML文档。通常使用find() 和find_all()方法来定位我们需要的元素。如果你想了解BeautifulSoup全部方法和参数,可以查阅BeautifulSoup的官方文档。虽然BeautifulSoup在代码的理解上比正则表达式要复杂一些,但是其更加容易构造和理解。
三、Lxml
Lxml模块使用 C语言编写,其解析速度比 BeautiflSoup更快,而且其安装过程也更为复杂,在此小编就不赘述啦。XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。

使用 lxml 模块的第一步和BeautifulSoup一样,也是将有可能不合法的HTML 解析为 统一格式。 虽然Lxml可以正确解析属性两侧缺失的引号,并闭合标签,不过该模块没有额外添加<html >和<body>标签 。
在线复制Xpath表达式可以很方便的复制Xpath表达式。但是通过该方法得到的Xpath表达式放在程序中一般不能用,而且长的没法看。所以Xpath表达式一般还是要自己亲自上手。
四、CSS
CSS选择器表示选择元素所使用 的模式。BeautifulSoup整合了CSS选择器的语法和自身方便使用API。在网络爬虫的开发过程中,对于熟悉CSS选择器语法的人,使用CSS选择器是个非常方便的方法。

下面是一些常用的选择器示例。
- 选择所 有标签: *
- 选择<a>标 签: a
- 选择所有class=”link” 的元素: .l in k
- 选择 class=”link” 的<a>标签: a.link
- 选择 id= " home ” 的<a>标签: a Jhome
- 选择父元素为<a>标签的所有< span>子标签: a > span
- 选择<a>标签内部的所有<span>标签: a span
- 选择title属性为” Home ” 的所有<a>标签: a [title=Home]
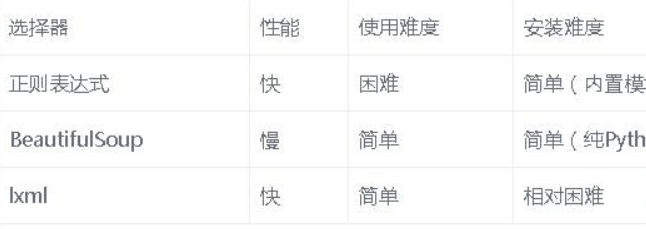
五、性能对比
lxml 和正则表达式模块都是C语言编写的,而BeautifulSoup则是纯Python 编写的。下表总结了每种抓取方法的优缺点。
六、总结
如果你的爬虫瓶颈是下载网页,而不是抽取数据的话,那么使用较慢的方法(如BeautifulSoup) 也不成问题。如果只需抓取少量数据,并且想要避免额外依赖的话,那么正则表达式可能更加适合。不过,通常情况下,l xml是抓取数据的最好选择,这是因为该方法既快速又健壮,而正则表达式和BeautifulSoup只在某些特定场景下有用。
Python网络爬虫四大选择器(正则表达式、BS4、Xpath、CSS)总结的更多相关文章
- Python网络爬虫四大选择器用法原理总结
前几天小编连续写了四篇关于Python选择器的文章,分别用正则表达式.BeautifulSoup.Xpath.CSS选择器分别抓取京东网的商品信息.今天小编来给大家总结一下这四个选择器,让大家更加深刻 ...
- python网络爬虫之三re正则表达式模块
""" re正则表达式,正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的 一些特定字符,及这些特定字符的组合,组成一个"规则字符串",然后用 ...
- python网络爬虫之解析网页的XPath(爬取Path职位信息)[三]
目录 前言 XPath的使用方法 XPath爬取数据 后言 @(目录) 前言 本章同样是解析网页,不过使用的解析技术为XPath. 相对于之前的BeautifulSoup,我感觉还行,也是一个比较常用 ...
- PYTHON网络爬虫与信息提取[正则表达式的使用](单元七)
正则表达式由字符和操作符构成 . 表示任何单个字符 []字符集,对单个字符给出取值范围 [abc]或者关系 [a-z]表示 [^abc]表示非这里面的东西 非字符集 * 表示星号之前的字符出现0次或 ...
- python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言 hello,大家好 本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json 所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去 ...
- 利用Python网络爬虫采集天气网的实时信息—BeautifulSoup选择器
相信小伙伴们都知道今冬以来范围最广.持续时间最长.影响最重的一场低温雨雪冰冻天气过程正在进行中.预计,今天安徽.江苏.浙江.湖北.湖南等地有暴雪,局地大暴雪,新增积雪深度4-8厘米,局地可达10-20 ...
- Python 正则表达式 (python网络爬虫)
昨天 2018 年 01 月 31 日,农历腊月十五日.20:00 左右,152 年一遇的月全食.血月.蓝月将今晚呈现空中,虽然没有看到蓝月亮,血月.月全食也是勉强可以了,还是可以想像一下一瓶蓝月亮洗 ...
- python 网络爬虫全流程教学,从入门到实战(requests+bs4+存储文件)
python 网络爬虫全流程教学,从入门到实战(requests+bs4+存储文件) requests是一个Python第三方库,用于向URL地址发起请求 bs4 全名 BeautifulSoup4, ...
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
随机推荐
- 【计算机视觉】纹理特征之LBP局部二值化模式
转自http://blog.csdn.NET/ty101/article/details/8905394 本文的PDF版本,以及涉及到的所有文献和代码可以到下列地址下载: 1.PDF版本以及文献:ht ...
- Java check是否是日期类型
boolean checkFormate(string parm){ Pattern pattern = Pattern.compile("([0-9]{4})(0[1-9]|1[0-2]) ...
- [转帖]Chrome中默认非安全端口
Chrome,你这坑人的默认非安全端口 https://www.cnblogs.com/soyxiaobi/p/9507798.html 之前遇到过 这个总结的比之前那篇要好呢. 今天用chrome打 ...
- 【坑】关于使用 maven 创建 web 项目以后,el 表达式不被识别的解决方法
问题描述: 在学习 Ajax 的时候,使用资源路径,博主本着不要硬编码,局使用 el 表达式进行读取项目名,然后发现 el 表达式没有被识别,而是当做字符串 ${pageContext.request ...
- 版本管理——Git和SVN的介绍及其优缺点
版本管理 概念:版本管理是软件配置管理的基础,它管理并保护开发者的软件资源. 好处:可以保留我们的历史版本,在代码开发到一半的时候,不至于无故丢失,还可以查看BUG的来龙去脉. 版本管理种类: ...
- ajax与jsonp中的几个封装函数
首先是ajax里的get 在页面上添加几个标签用作测试 <body> <input type="text" id="user"> < ...
- XDebug调试
安装 访问Xdebug 点击download 找到RELEASES,点击 custom installation instructions. 在白色框框内填入phpinfo()出来的源码 点击Anal ...
- linux下安装lnmp集成环境
linux下安装lnmp集成环境 教程地址:https://www.cnblogs.com/peteremperor/p/6750204.html 必须要用root用户,否则权限不够无法安装 安装最新 ...
- 深度学习-mnist手写体识别
mnist手写体识别 Mnist数据集可以从官网下载,网址: http://yann.lecun.com/exdb/mnist/ 下载下来的数据集被分成两部分:55000行的训练数据集(mnist.t ...
- 机器学习笔记--Hoeffding霍夫丁不等式
Hoeffding霍夫丁不等式 在<>第八章"集成学习"部分, 考虑二分类问题\(y \in \{-1, +1\}\) 和真实函数\(f\), 假定基分类器的错误率为\ ...