JAVA HashMap 解析
1.简介(其实是HashMap注释的大致翻译)
本文基于JDK1.8,与JDK1.7中的HashMap有一些区别,看官注意区别。
HashMap实现了Map接口,提供了高效的Key-Value访问。HashMap与HashTable非常类似,除了HashMap允许key和value为null,并且HashMap非线程安全,而HashTabel则是线程安全的。HashMap不保证插入键值对的顺序;也不保证在不断的插入和删除后,键值对的顺序会保持不变(保证顺序的有LinkedHashMap)。
如果HashMap中的元素均匀的分布在桶中,那么put和get操作能接近与常量级的时间消耗。在HashMap上进行迭代需要的时间收到容量的影响,所以不要在初始化时,把初始化容量设置的过大,或者负载因子设置的过小。
通常情况下,默认的负载因子,0.75能很好的权衡时间消耗和空间消耗。将负载因子设置大一些能提高空间利用率,但是也会提高查询时间的消耗。
如果会有很多的元素会存在HashMap当中,在创建时设置一个相对较大的值,来避免自动的扩容和rehashing,这样能提高效率。如果很多key具有相同的hashCode()值,会降低HashMap的性能。
注意HashMap不是线程安全的,如果想使用线程安全的Map,可以使用 Collections.synchronizedMap 、HashTable、ConcurrnetHashMap替代他。
HashMap返回的 iterator(迭代器)是快速失败的(fail-fast)。如果在迭代过程中,有其他线程修改了hashMap(put,remove),会抛出一个ConcurrentModificationException,但是使用迭代器本身的 remove方法不会。
2.HashMap内部数据结构和成员变量
HashMap成员变量有以下这些(不包括类变量):
transient Node<K,V>[] table;
transient Set<Map.Entry<K,V>> entrySet;
transient int size;
transient int modCount;
int threshold;
final float loadFactor;
table变量就是实际上存储元素的地方,是一个内部数据结构Node的数组。
entrySet实际上内部不保存元素,并且直到调用entrySet()之后才会真正的实例化,否则一直都是null。因为HashMap没有实现迭代器接口,table变量也不是单纯的数组,实际上会演变成数组+局部链表或数组+局部红黑树的结构。平常对HashMap的遍历,通常会调用entrySet()方法,获取entrySet变量,然后进行遍历。
size变量保存的是当前已经插入的元素数量,而不是table的长度。
modeCount被用来实现快速失败机制。在通过entrySet遍历时(entrySet().iterator(),无论是直接使用迭代器,还是使用 foreach循环,都是相当与调用了该方法),每次都会创建一个新的迭代器变量,其中保存了当时状态下的modCount,在调用HashMap的put、remove等方法时,modeCount都会递增,遍历下一个元素时(next()),会检查此时的modeCount是否和创建迭代时保存的modeCount是否一致,否则抛出异常。
threhold是容量 * 负载因子,当 size超过该值时会触发扩容和rehashing的操作。
loadFactor就是负载因子,决定了当HashMap达到“多满”是会进行扩容操作。
HashMap的内部数据结构有:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
}
这里只列举了两个,其他还有一些 entrySet的类,values方法返回值的类,keys方法返回的类,以及他们对应的迭代器,这里就不介绍了。
Node类,就是上述table中保存的实例的类,其中有 hash --不等同与hashCode()的值,但是与hashCode()值关系紧密,相同的hashCode()则对应相同的hash值;key就是键,通过key来查询保存的value;value就是保存进来的值;next指向了下一个节点,为元素冲突时提供了解决方案。可以看到,实际上HashMap中不仅仅会保存value,同样会保存一些必要的信息(废话!)。
TreeNode是Node的一个子类(LinkedHashMap.Entry继承自Node)。当HashMap中某一个桶位冲突太多,这个位置上的链表就会变得很长,降低了查询的效率,这时候需要将链表转化为一颗树,Node节点会转化为TreeNode作为子结点,提升查询的效率(为什么不一开始就是用树结构,维护树结构不要时间哒!),冲突的数量减少到一定量(remove),树会退化为链表,TreeNode也会转化Node。
3.HashMap逻辑存储结构
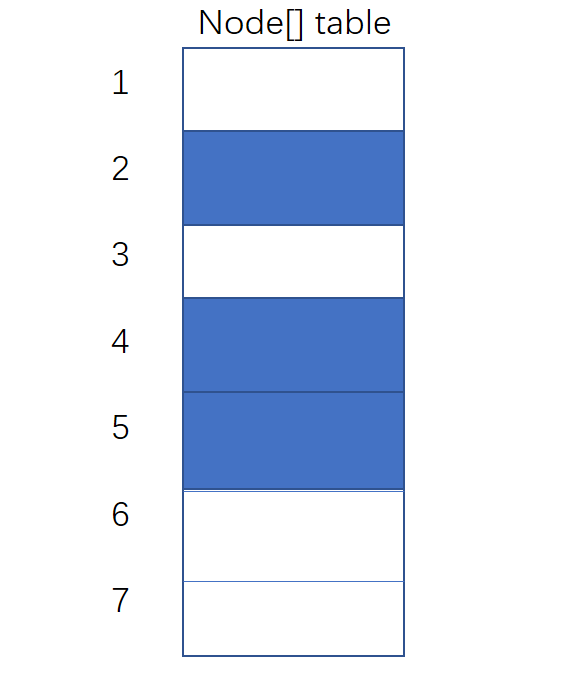
图一(鼠标移动到图上面就能看到对应的标题了)展示了无冲突情况下的table结构。
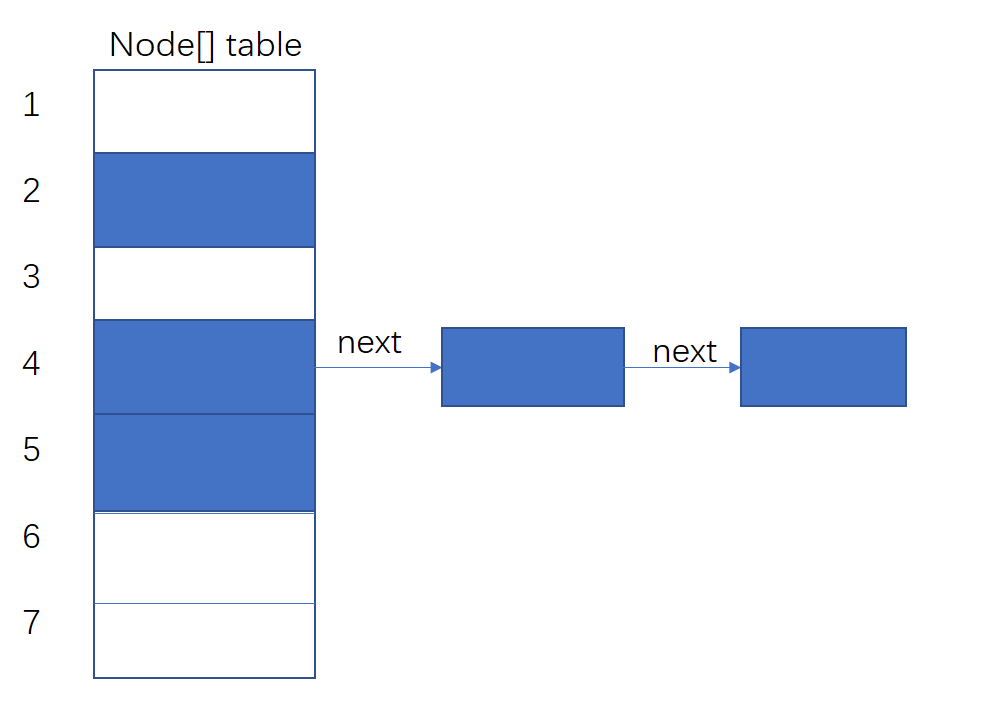
图二展示了某一个桶位置有一定量冲突情况下的table结构。
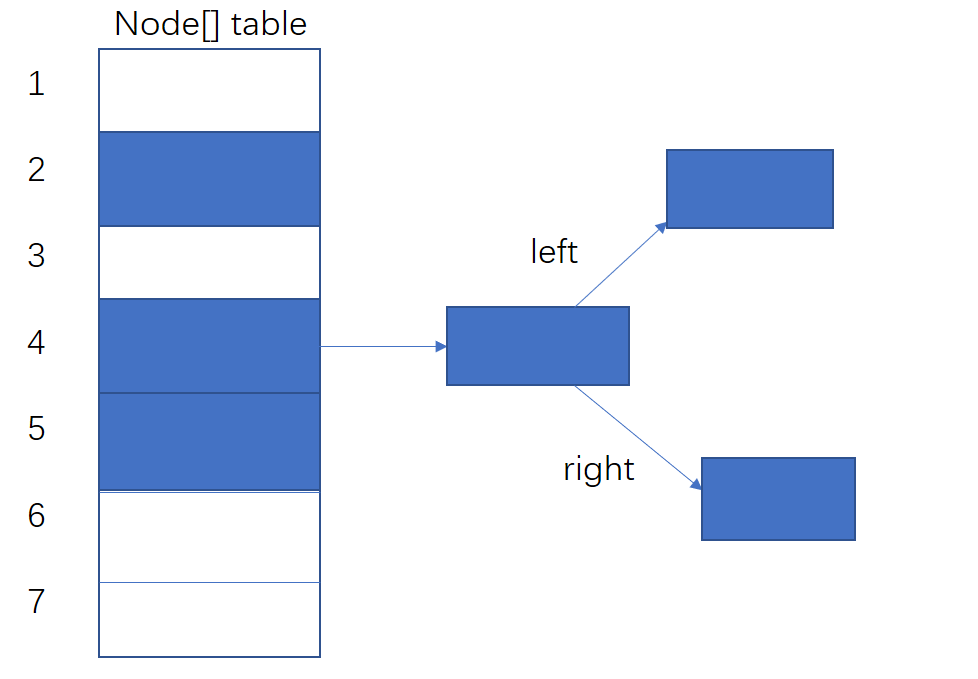
图三展示了某一个桶位置大量冲突,从链表转换为树结构。
(所谓的桶位就是table这个数组的某一个位置,三张图中蓝色表示已经一个不为null的Node)
4.HashMap实现原理
先从几个关键内部方法入口,再来探讨HashMap对外暴露的关键方法。
4.1 计算Table Size
计算 HashMap中table应该初始化或者扩容时的长度。HashMap中的table长度都是2的幂次方,为什么这么做,是为了能保证元素能够在table上面均匀分布,为什么能保证,课后作业~
代码的执行结果是获得一个 大于等于 cap的最小2的幂次方数。这个算法非常巧妙,分析如下:
首先cap的取值范围为,>=0;那么 n >=-1;
当 n = 0 时,在 return语句之前,n的值为0,最后返回结果为 1;
当 n = -1,应为最高位 一直是 1(不理解的复习一下 补码了),因此是个负数,最后返回结果为1;
当 n > 0时,任何一个 整数二进制可以表示为 001XXXXX (做个解释,这里的1是表示最高位的1,前导全部是0,而这里前导0数量并不表示一定是2个,简化一些,下面运算方便一点,后面的X表示,可能为1,也可能为0,实际上我们并不关心,但是整个二进制串的长度是32)
第一次运算: n | = n >>> 1,即:
001XXXXX |
0001XXXX =
0011XXXXX ; 现在我们能保证前导0之后至少有2个连续的1(或者说已经到此时保证除了前导0之外,全部都是1,下不赘述);
第二次运算: n |= n>>>2,即:
0011XXXXX |
000011XXX =
001111XXXX ;现在我们能保证前导0之后至少有4个连续的1。
依次类推,最后我们能得到一个数字,他除了前导0之外,全部都是1。
n+1 就是得到了 一个 2的幂次方,并且是大于等于 cap的最小 2的幂次方数。
为什么这里 要先将 cap -1呢?因为是为了防止 cap已经是 2的幂次方数,可以尝试一下上面的算法,如果不将cap -1,那么得到的树就会变为 cap的两倍,但是显然没必要,我们希望的是cap。
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
4.2 Hash算法
相较于1.7的Hash算法,1.8简单了不少。不直接使用hashCode()来作为hash值,是为了避免更少的冲突,(可以参考其他的博文),相对于1.7的计算方法,明显简化了很多。官方说法是,这样做是 综合考虑了 实用性,效率。(也就是这么做已经能保证大多数情况下较低的碰撞率,计算方法也相对简单高效,对了,碰撞的意思就是不同的key分配到相同的一个桶位,这样就不得不演变成链表或者树的形式)。
具体的算法就是,key == null 则返回0;否则 等于 key.hashCode() 亦或 key.hashCode()无符号右移16位。
static final int hash(Object key) {
int h;
//这里也间接证明了 key 可以为 null
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
4.3 计算桶位(该放到table数组的哪个位置)
1.8中没有将他独立成一个方法,从putVal()方法中截取一段。 n 就是 table的长度,hash就是 key通过上述的 hash算法计算出来的值。有的人可能会认为table的长度为 2的幂次方 是为了 能快速计算下标(使用 &运算符),并且计算出来的下标不会超过table长度。实际上不是的,事实上,table的长度为2的幂次方是为了最大化的降低冲突的概率,并且对于任何一个整数 n,都能使用 (n-1) & length 来计算下标,并且计算出来的结果小于n。
(n - 1) & hash
4.4 put方法(插入一个元素)
1.8 中,是直接调用
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict)
第一个参数是 我们前秒写的 hash方法计算出来的值;最后两个 boolean参数 这时候都是 false。
直接参照源码和注释理解这个方法。
4.5 resize 扩容
扩容操作,不仅仅需要扩大table的长度,Node所在的位置也会发生变化(实际上,如果原table的长度为n,Node所在下标为t,那么在新table中,一个Node所在的下标要么是 t,要么是t+n,没有其他选择)。为什么?
1. 原来的表 table 长度为 001000000;
2.那么新table 长度为 010000000 ;
3.在旧table 中下标 t = 000111111 & hash = 000XXXXX (x可能为1 也可能为 0)
4。在新table 中下标 T = 0011111 & hash = 00MXXXXX,和t相比,除了 M可能是1 可能 0 之外,每一个T中的X 和 t中的 X 都是一样的(想想为什么,应为都是 hash & 11111嘛,肯定是一样的嘛!)
5. 如果 M = 0,那么 T = 000XXXXX = t ; 如果 M =1 ,那么 T = 001XXXX = t + 0010000 = t + oldCap = t + 原 table的长度
6. 那么什么情况下 M 会是 0 呢? 什么情况下M 或是1呢?显然,当 hash = XX0XXXX的时候,M = 0,也就是说 hash & (newCap -1 ) = XX0XXXX & 00111111 = 000XXXXX = hash & (oldCap -1 );
可一继续推导一下,当 hash & oldCap = 0 的时候,那么 M = 0。(证明不是很严谨哈)
同样直接按照源码和注释理解这个方法。
final HashMap.Node<K,V>[] resize() {
//前面这一段没什么好说的,扩容 table长度的两倍,threshold通常情况下是 CAPACITY * LOAD_FACTOR;如果 table长度已经是
//最大了,那么 threshold也会变成 Integer.MAX_VALUE.
HashMap.Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
//这里因为只有变化了 threshode,容量没有变化,所以Node位置不需要发生变化,直接返回了。
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
//重新创建一个 新长度的数组
HashMap.Node<K,V>[] newTab = (HashMap.Node<K,V>[])new HashMap.Node[newCap];
table = newTab;
if (oldTab != null) {
//遍历老的 table
for (int j = 0; j < oldCap; ++j) {
HashMap.Node<K,V> e;
if ((e = oldTab[j]) != null) {
//老的 table已经不用了,因此直接赋值为null,可以回收掉
oldTab[j] = null;
//如果 e的下一个节点是 null,就是说 这里没有链表 或 树的结构,那么重新计算下表,赋值到新的table
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//树节点的变化,有空在分析
else if (e instanceof HashMap.TreeNode)
((HashMap.TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
//到这里就是对链表的重新分配了,注意,原Table中某些key会被计算到同一个下标,但在新的下表中却不一定
// 因此链表可能会拆散,变成0-2个链表,为什么,可以前面描述哈。
//所以这里定义两个node对,一个是 loHead,loTail;一个是 hiHead,hiTail
HashMap.Node<K,V> loHead = null, loTail = null;
HashMap.Node<K,V> hiHead = null, hiTail = null;
HashMap.Node<K,V> next;
do {
//循环遍历
next = e.next;
//e.hash & oldCap == 0 的Node 会被分配到同一个位置,确切来说,和原table的下标是一样的
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
//其余的节点会被分配到 另外一个 同一位置,确切来说是 原table下标 + oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//这里就没什么了,在对应的位置上赋值就可以
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
5. 常见面试题
Q: table数组什么时候获得初始化?
A: 第一次插入元素的时候
Q:new HashMap().put(),就是初始化hashMap之后,第一次放入元素,table的长度是多少
A:16
Q:new HashMap(19),创建的map中table数组长度会是多大。
初始化时实际上是 null,第一次插入元素时是32.
JAVA HashMap 解析的更多相关文章
- java集合框架之java HashMap代码解析
java集合框架之java HashMap代码解析 文章Java集合框架综述后,具体集合类的代码,首先以既熟悉又陌生的HashMap开始. 源自http://www.codeceo.com/arti ...
- 【转】Java HashMap 源码解析(好文章)
.fluid-width-video-wrapper { width: 100%; position: relative; padding: 0; } .fluid-width-video-wra ...
- java基础解析系列(五)---HashMap并发下的问题以及HashTable和CurrentHashMap的区别
java基础解析系列(五)---HashMap并发下的问题以及HashTable和CurrentHashMap的区别 目录 java基础解析系列(一)---String.StringBuffer.St ...
- 【java提高】---HashMap解析(一)
HashMap解析(一) 平时一直再用hashmap并没有稍微深入的去了解它,自己花点时间想往里面在深入一点,发现它比arraylist难理解很多,好多东西目前还不太能理解等以后自己知识更加丰富在过来 ...
- java提高(9)---HashMap解析
HashMap解析(一) 平时一直再用hashmap并没有稍微深入的去了解它,自己花点时间想往里面在深入一点,发现它比arraylist难理解很多. 数据结构中有数组和链表来实现对数据的存储,但这两者 ...
- java基础解析系列(三)---HashMap
java基础解析系列(三)---HashMap java基础解析系列 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析系列(二)-- ...
- Java - HashMap 多线程安全解析
HashMap多线程并发问题分析 多线程put后可能导致get死循环 从前我们的Java代码因为一些原因使用了HashMap这个东西,但是当时的程序是单线程的,一切都没有问题.后来,我们的程序性能有问 ...
- Java容器解析系列(11) HashMap 详解
本篇我们来介绍一个最常用的Map结构--HashMap 关于HashMap,关于其基本原理,网上对其进行讲解的博客非常多,且很多都写的比较好,所以.... 这里直接贴上地址: 关于hash算法: Ha ...
- Java学习笔记(二二)——Java HashMap
[前面的话] 早上起来好瞌睡哈,最近要注意一样作息状态. HashMap好好学习一下. [定义] Hashmap:是一个散列表,它存储的内容是键值对(key——value)映射.允许nul ...
随机推荐
- JavaScript笔记之第六天
JavaScript 库 JavaScript 库 - jQuery.Prototype.MooTools. jQuery jQuery 是目前最受欢迎的 JavaScript 框架. 它使用 CSS ...
- macaca web(4)
米西米西滴,吃过中午饭来一篇,话说,上回书说道macaca 测试web(3),参数驱动来搞,那么有小伙本又来给雷子来需求, 登录模块能不能给我给重新封装一下吗, 我说干嘛封装,现在不挺好,于是乎,接着 ...
- grunt之concat、cssmin、uglify
周末有点懒,跑去看了<智取威虎山>,手撕鬼子的神剧情节被徐老怪一条回忆线就解释过去了,牛到极致尽是这种四两拨千斤的处理方式,手撕加分,四星推荐. --------------------- ...
- .opt,frm,.MYD,.MYI文件如何转为.sql文件?
假如你是网站测试人员,数据库管理员从服务器上导出数据库,如下图: 你会发现这不是.sql文件,需要将其转化. 其实很简单,只要你本地比如D盘有安装“phpstudy”和“SQLyog”就可以,你可以直 ...
- HTML5 javascript 音乐 音频
<!doctype html> <html> <head> <meta charset="utf-8"> <title> ...
- 201521123068 《java程序设计》第8周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结集合与泛型相关内容. 1.2 选做:收集你认为有用的代码片段 泛型,即参数化类型,不考虑类型参数的继承关系,getClass方法的返 ...
- 201521123060 《Java程序设计》第7周学习总结
1. 本周学习总结 2. 书面作业 1.ArrayList代码分析 1.1 解释ArrayList的contains源代码 答:contains方法调用indexOf方法,遍历遍历内部用于保存数据的e ...
- 201521123114 《Java程序设计》第6周学习总结
1. 本章学习总结 1.1 面向对象学习暂告一段落,请使用思维导图,以封装.继承.多态为核心概念画一张思维导图,对面向对象思想进行一个总结. 2. 书面作业 Q1.clone方法 1.1 Object ...
- 201521123063 《Java程序设计》第三周学习总结
1.本周学习总结 初学面向对象,会学习到很多碎片化的概念与知识.尝试学会使用思维导图将这些碎片化的概念.知识组织起来.请使用纸笔或者下面的工具画出本周学习到的知识点.截图或者拍照上传. 2.书面作业 ...
- 201521123036 《Java程序设计》第2周学习总结
本周学习总结 java数据类型: 基本类型:整数,浮点,boolean类 引用类型:数组,类,接口,null类型 String类:String类的对象不可变,字符串API,大量修改字符串使用Strin ...