Python爬虫从入门到放弃(二十三)之 Scrapy的中间件Downloader Middleware实现User-Agent随机切换
总架构理解Middleware
通过scrapy官网最新的架构图来理解:
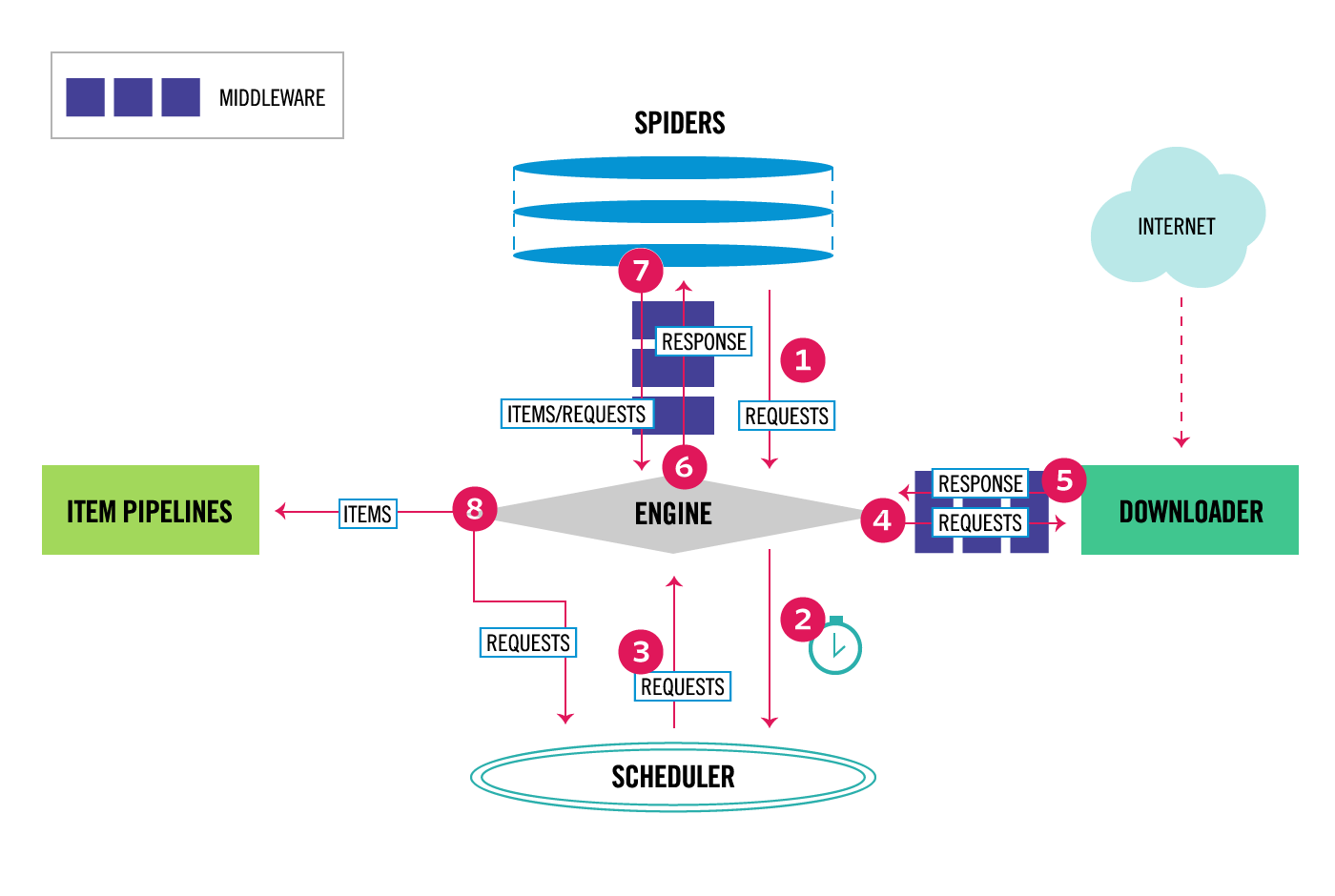
这个图较之前的图顺序更加清晰,从图中我们可以看出,在spiders和ENGINE提及ENGINE和DOWNLOADER之间都可以设置中间件,两者是双向的,并且是可以设置多层.
关于Downloader Middleware我在http://www.cnblogs.com/zhaof/p/7198407.html 这篇博客中已经写了详细的使用介绍。
如何实现随机更换User-Agent
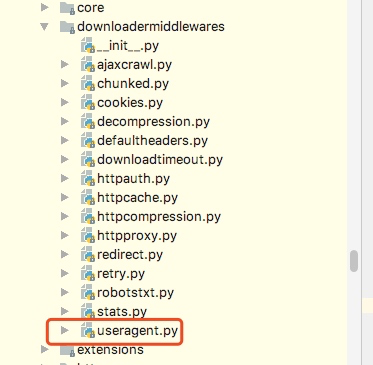
这里要做的是通过自己在Downlaoder Middleware中定义一个类来实现随机更换User-Agent,但是我们需要知道的是scrapy其实本身提供了一个user-agent这个我们在源码中可以看到如下图:
from scrapy import signals
class UserAgentMiddleware(object):
"""This middleware allows spiders to override the user_agent""" def __init__(self, user_agent='Scrapy'):
self.user_agent = user_agent @classmethod
def from_crawler(cls, crawler):
o = cls(crawler.settings['USER_AGENT'])
crawler.signals.connect(o.spider_opened, signal=signals.spider_opened)
return o def spider_opened(self, spider):
self.user_agent = getattr(spider, 'user_agent', self.user_agent) def process_request(self, request, spider):
if self.user_agent:
request.headers.setdefault(b'User-Agent', self.user_agent)
从源代码中可以知道,默认scrapy的user_agent=‘Scrapy’,并且这里在这个类里有一个类方法from_crawler会从settings里获取USER_AGENT这个配置,如果settings配置文件中没有配置,则会采用默认的Scrapy,process_request方法会在请求头中设置User-Agent.
关于随机切换User-Agent的库
github地址为:https://github.com/hellysmile/fake-useragent
安装:pip install fake-useragent
基本的使用例子:
from fake_useragent import UserAgent ua = UserAgent() print(ua.ie)
print(ua.chrome)
print(ua.Firefox)
print(ua.random)
print(ua.random)
print(ua.random)
这里可以获取我们想要的常用的User-Agent,并且这里提供了一个random方法可以直接随机获取,上述代码的结果为:

关于配置和代码
这里我找了一个之前写好的爬虫,然后实现随机更换User-Agent,在settings配置文件如下:
DOWNLOADER_MIDDLEWARES = {
'jobboleSpider.middlewares.RandomUserAgentMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
RANDOM_UA_TYPE= 'random'
这里我们要将系统的UserAgent中间件设置为None,这样就不会启用,否则默认系统的这个中间会被启用
定义RANDOM_UA_TYPE这个是设置一个默认的值,如果这里不设置我们会在代码中进行设置,在middleares.py中添加如下代码:
class RandomUserAgentMiddleware(object):
'''
随机更换User-Agent
'''
def __init__(self,crawler):
super(RandomUserAgentMiddleware, self).__init__()
self.ua = UserAgent()
self.ua_type = crawler.settings.get('RANDOM_UA_TYPE','random') @classmethod
def from_crawler(cls,crawler):
return cls(crawler) def process_request(self,request,spider): def get_ua():
return getattr(self.ua,self.ua_type)
request.headers.setdefault('User-Agent',get_ua())
上述代码的一个简单分析描述:
1. 通过crawler.settings.get来获取配置文件中的配置,如果没有配置则默认是random,如果配置了ie或者chrome等就会获取到相应的配置
2. 在process_request方法中我们嵌套了一个get_ua方法,get_ua其实就是为了执行ua.ua_type,但是这里无法使用self.ua.self.us_type,所以利用了getattr方法来直接获取,最后通过request.heasers.setdefault来设置User-Agent
通过上面的配置我们就实现了每次请求随机更换User-Agent
Python爬虫从入门到放弃(二十三)之 Scrapy的中间件Downloader Middleware实现User-Agent随机切换的更多相关文章
- Python爬虫从入门到放弃(十三)之 Scrapy框架的命令行详解
这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: localhost:spider zhaofan$ scrapy start ...
- Python之爬虫从入门到放弃(十三) Scrapy框架整体的了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- python爬虫从入门到放弃前奏之学习方法
首谈方法 最近在整理爬虫系列的博客,但是当整理几篇之后,发现一个问题,不管学习任何内容,其实方法是最重要的,按照我之前写的博客内容,其实学起来还是很点枯燥不能解决传统学习过程中的几个问题: 这个是普通 ...
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- Python爬虫从入门到放弃(十七)之 Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
- Python爬虫从入门到放弃 之 Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
- Python之爬虫(二十五) Scrapy的中间件Downloader Middleware实现User-Agent随机切换
总架构理解Middleware 通过scrapy官网最新的架构图来理解: 这个图较之前的图顺序更加清晰,从图中我们可以看出,在spiders和ENGINE提及ENGINE和DOWNLOADER之间都可 ...
- Python爬虫从入门到放弃(二十一)之 Scrapy分布式部署
按照上一篇文章中我们将代码放到远程主机是通过拷贝或者git的方式,但是如果考虑到我们又多台远程主机的情况,这种方式就比较麻烦,那有没有好用的方法呢?这里其实可以通过scrapyd,下面是这个scrap ...
随机推荐
- System.Runtime.Serialization.SerializationException”类型的未经处理的异常在 System.Runtime.Serialization.dll 中发生
异常信息: “System.Runtime.Serialization.SerializationException”类型的未经处理的异常在 System.Runtime.Serialization. ...
- PHP Startup: Unable to load dynamic library '/usr/lib64/php/modules/event.so'
这是因为启动apche 的时候重复加载了php的动态库模块了, 将:/etc/php.d/ 目录下的event.ini中的内容注释掉或者将文件删除即可
- apache 基本vhost配置
经常使用Apache虚拟主机进行开发和测试,但每次需要配置虚拟主机时都习惯性的ctrl+c和ctrl+v,这次由于重装系统,需要配置一个新的PHP开发环境虚拟主机,于是总结一下Apaceh配置http ...
- win 10 开机后无法显示桌面
我整理了几种方法,可以试一下 1> win + x 然后运行explorer.exe 2> 1/// shift + ctrl + esc 进入 任务管理器 2/// 点击 ...
- 【Android Developers Training】 2. 运行你的应用
注:本文翻译自Google官方的Android Developers Training文档,译者技术一般,由于喜爱安卓而产生了翻译的念头,纯属个人兴趣爱好. 原文链接:http://developer ...
- java登录时数据库验证账户密码-mysql
一:连接数据库: package login; import java.sql.*; public class conmysql { String drivername="com.mysql ...
- GCD 信号量 dispatch_semaphore_t
1.GCD知识讲解 1)dispatch_semaphore_create(long value) //创建一个信号量,总量为value,value不能小于0 2)dispatch_semaphore ...
- MyBatis源码解析【2】构建项目
有了之前的准备,今天就要开始构建学习使用的项目了.废话不多说.开始吧. 首先我用IDEA构建了一个空的maven项目,然后加入了Mybatis的依赖. <dependencies> < ...
- 关于移动APP与Web APP的测试重点以及区别
Web app测试重点: 1. 功能测试:功能的实现是否满足需求. 2. 性能测试: 2.1 链接速度测试:测试页面链接的速度 2.2 负载测试:web应用系统能允许多少个用户同时在线?超过这个数量会 ...
- 高效测试用例组织算法pairwise之Python实现
------------------------------------------本文专为<光荣之路培训 >原创,如有转载请注明出处--------------------------- ...