python网络爬虫之使用scrapy自动爬取多个网页
前面介绍的scrapy爬虫只能爬取单个网页。如果我们想爬取多个网页。比如网上的小说该如何如何操作呢。比如下面的这样的结构。是小说的第一篇。可以点击返回目录还是下一页
对应的网页代码:
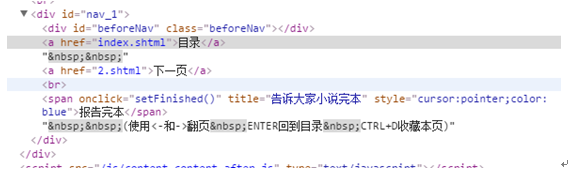
我们再看进入后面章节的网页,可以看到增加了上一页

对应的网页代码:
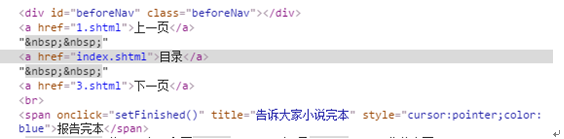
通过对比上面的网页代码可以看到. 上一页,目录,下一页的网页代码都在<div>下的<a>元素的href里面。不同的是第一章只有2个<a>元素,从二章开始就有3个<a>元素。因此我们可以通过<div>下<a>元素的个数来判决是否含有上一页和下一页的页面。代码如下

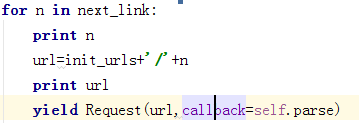
最终得到生成的网页链接。并调用Request重新申请这个网页的数据
那么在pipelines.py的文件中。我们同样需要修改下存储的代码。如下。可以看到在这里就不是用json. 而是直接打开txt文件进行存储
class Test1Pipeline(object):
def __init__(self):
self.file=''
def process_item(self, item, spider):
self.file=open(r'E:\scrapy_project\xiaoshuo.txt','wb')
self.file.write(item['content'])
self.file.close()
return item
完整的代码如下:在这里需要注意两次yield的用法。第一次yield后会自动转到Test1Pipeline中进行数据存储,存储完以后再进行下一次网页的获取。然后通过Request获取下一次网页的内容
class testSpider(Spider):
name="test1"
allowd_domains=['http://www.xunsee.com']
start_urls=["http://www.xunread.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/1.shtml"]
def parse(self, response):
init_urls="http://www.xunread.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615"
sel=Selector(response)
context=''
content=sel.xpath('//div[@id="content_1"]/text()').extract()
for c in content:
context=context+c.encode('utf-8')
items=Test1Item()
items['content']=context
count = len(sel.xpath('//div[@id="nav_1"]/a').extract())
if count > 2:
next_link=sel.xpath('//div[@id="nav_1"]/a')[2].xpath('@href').extract()
else:
next_link=sel.xpath('//div[@id="nav_1"]/a')[1].xpath('@href').extract()
yield items
for n in next_link:
url=init_urls+'/'+n
print url
yield Request(url,callback=self.parse)
对于自动爬取网页scrapy有个更方便的方法:CrawlSpider
前面介绍到的Spider中只能解析在start_urls中的网页。虽然在上一章也实现了自动爬取的规则。但略显负责。在scrapy中可以用CrawlSpider来进行网页的自动爬取。
爬取的规则原型如下:
classscrapy.contrib.spiders.Rule(link_extractor, callback=None, cb_kwargs=None, follow=None,process_links=None, process_request=None)
LinkExtractor.:它的作用是定义了如何从爬取到的的页面中提取链接
Callback指向一个调用函数,每当从LinkExtractor获取到链接时将调用该函数进行处理,该回调函数接受一个response作为第一个参数。注意:在用CrawlSpider的时候禁止用parse作为回调函数。因为CrawlSpider使用parse方法来实现逻辑,因此如果使用parse函数将会导致调用失败
Follow是一个判断值,用来指示从response中提取的链接是否需要跟进
在scrapy shell中提取www.sina.com.cn为例

LinkExtractor中的allow只针对href属性:
例如下面的链接只针对href属性做正则表达式提取
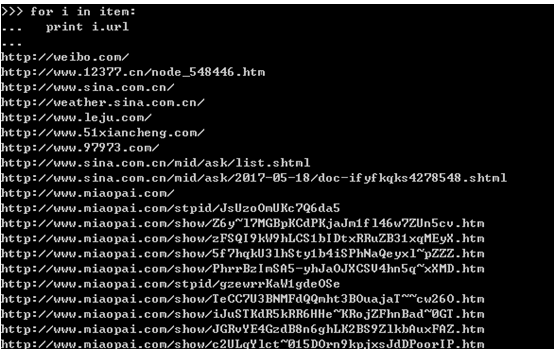
结构如下:可以得到各个链接。
可以通过restrict_xpaths对各个链接加以限制,如下的方法:

实例2:还是以之前的迅读网为例
提取网页中的下一节的地址:
网页地址:
http://www.xunread.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/1.shtml
下一页的的相对URL地址为2.shtml。
通过如下规则提取出来
>>> item=LinkExtractor(allow=('\d\.shtml')).extract_links(response)
>>> for i in item:
... print i.ur
...
http://www.xunread.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/2.shtml

也通过导航页面直接获取所有章节的链接:
C:\Users\Administrator>scrapy shell http://www.xunread.com/article/8c39f5a0-ca54
-44d7-86cc-148eee4d6615/index.shtml
from scrapy.linkextractors import LinkExtractor
>>> item=LinkExtractor(allow=('\d\.shtml')).extract_links(response)
>>> for i in item:
... print i.url
得到如下全部的链接
那么接下来构造在scrapy中的代码,如下
class testSpider(CrawlSpider):
name="test1"
allowd_domains=['http://www.xunsee.com']
start_urls=["http://www.xunsee.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/1.shtml"]
rules=(Rule(LinkExtractor(allow=('\d\.shtml')),callback='parse_item',follow=True),)
print rules
def parse_item(self, response):
print response.url
sel=Selector(response)
context=''
content=sel.xpath('//div[@id="content_1"]/text()').extract()
for c in content:
context=context+c.encode('utf-8')
items=Test1Item()
items['content']=context
yield items
关键的是rules=(Rule(LinkExtractor(allow=('\d\.shtml')),callback='parse_item',follow=True),) 这个里面规定了提取网页的规则。以上面的例子为例。爬取的过程分为如下几个步骤:
1 从http://www.xunsee.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/1.shtml开始,第一调用parse_item,用xpath提取网页内容,然后用Rule提取网页规则,在这里提取到2.shtml。
2 进入2.shtml.进入2.shtml后再重复运行第一步的过程。直到Rules中提取不到任何规则
我们也可以做一下优化,设置start_urls为页面索引页面
http://www.xunsee.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/index.shtml
这样通过Rule可以一下提取出所有的链接。然后对每个链接调用parse_item进行网页信息提取。这样的效率比从1.shtml要高效很多。
python网络爬虫之使用scrapy自动爬取多个网页的更多相关文章
- python网络爬虫之使用scrapy自动登录网站
前面曾经介绍过requests实现自动登录的方法.这里介绍下使用scrapy如何实现自动登录.还是以csdn网站为例. Scrapy使用FormRequest来登录并递交数据给服务器.只是带有额外的f ...
- 爬虫(二)Python网络爬虫相关基础概念、爬取get请求的页面数据
什么是爬虫 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程. 哪些语言可以实现爬虫 1.php:可以实现爬虫.php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆 ...
- Python网络爬虫第三弹《爬取get请求的页面数据》
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- 【Python网络爬虫四】通过关键字爬取多张百度图片的图片
最近看了女神的新剧<逃避虽然可耻但有用>,同样男主也是一名程序员,所以很有共鸣 被大只萝莉萌的一脸一脸的,我们来爬一爬女神的皂片. 百度搜索结果:新恒结衣 本文主要分为4个部分: 1.下载 ...
- Python网络爬虫案例(二)——爬取招聘信息网站
利用Python,爬取 51job 上面有关于 IT行业 的招聘信息 版权声明:未经博主授权,内容严禁分享转载 案例代码: # __author : "J" # date : 20 ...
- python网络爬虫之使用scrapy爬取图片
在前面的章节中都介绍了scrapy如何爬取网页数据,今天介绍下如何爬取图片. 下载图片需要用到ImagesPipeline这个类,首先介绍下工作流程: 1 首先需要在一个爬虫中,获取到图片的url并存 ...
- 【python 网络爬虫】之scrapy系列
网络爬虫之scripy系列 [scrapy网络爬虫]之0 爬虫与反扒 [scrapy网络爬虫]之一 scrapy框架简介和基础应用 [scrapy网络爬虫]之二 持久化操作 [scrapy网络爬虫]之 ...
- Python 网络爬虫 008 (编程) 通过ID索引号遍历目标网页里链接的所有网页
通过 ID索引号 遍历目标网页里链接的所有网页 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 Python 的集成开发环境:PyChar ...
- python3编写网络爬虫14-动态渲染页面爬取
一.动态渲染页面爬取 上节课我们了解了Ajax分析和抓取方式,这其实也是JavaScript动态渲染页面的一种情形,通过直接分析Ajax,借助requests和urllib实现数据爬取 但是javaS ...
随机推荐
- libpng处理png图片(一)
一:libpng库的编译 环境:windows10 + VS2013 需要下载:libpng, zlib两个库 下载地址: libpng:http://libmng.com/pub/png/libpn ...
- WPF报表自定义通用可筛选列头-WPF特工队内部资料
由于项目需要制作一个可通用的报表多行标题,且可实现各种类型的内容显示,包括文本.输入框.下拉框.多选框等(自定的显示内容可自行扩展),并支持参数绑定转换,效果如下: 源码结构 ColumnItem类: ...
- Linux 通过端口转发来访问内网服务
Rinetd是为在一个Unix和Linux操作系统中为重定向传输控制协议(TCP)连接的一个工具,系统内部服务受系统网服限制外部无法访问,需要通过rinetd映射将内网服务转发出来. 1. 下载解压 ...
- Java类加载和卸载的跟踪
博客搬家自https://my.oschina.net/itsyizu/blog/ 什么是类的加载和卸载 Java程序的运行离不开类的加载,为了更好地理解程序的执行,有时候需要知道系统加载了哪些类.一 ...
- 【less和sass的区别,你了解多少?】
在介绍less和sass的区别之前,我们先来了解一下他们的定义: 一.Less.Sass/Scss是什么? 1.Less: 是一种动态样式语言. 对CSS赋予了动态语言的特性,如变量.继承.运算.函数 ...
- 响应式网站-全屏banner响应的2中方法 - 被吃掉的banner
通常来讲, 设计师们喜欢把banner设计成全屏(1920px或以上) 主题内容控制在一定的范围内一般在1200px左右 这样的设计即可以在宽屏上的表现很好.也能向下兼容一些小屏幕的设备: 如下图(所 ...
- 13、Java菜单条、菜单、菜单项
13.Java菜单条.菜单.菜单项 一般用Java做界面时,都得牵涉到菜单条.菜单.菜单项的设计.菜单项放在菜单里,菜单放在菜单条里,且其字体均可设置. 13.1.菜单条(Menubar) Frame ...
- 5、Java Swing布局管理器(FlowLayout、BorderLayout、CardLayout、BoxLayout、GirdBagLayout 和 GirdLayout)
5.Java-Swing常用布局管理器 应用布局管理器都属于相对布局,各组件位置可随界面大小而相应改变,不变的只是其相对位置,布局管理器比较难以控制,一般只在界面大小需要改是才用,但即使这 ...
- html学习笔记 - 列表
<!-- 无序列表 --> <ul type = square> <li><a href="https://www.baidu.com"& ...
- 开涛spring3(6.5) - AOP 之 6.5 AspectJ切入点语法详解
6.5.1 Spring AOP支持的AspectJ切入点指示符 切入点指示符用来指示切入点表达式目的,,在Spring AOP中目前只有执行方法这一个连接点,Spring AOP支持的Aspect ...