2018年排名前20的数据科学Python库
Python 在解决数据科学任务和挑战方面继续处于领先地位。业已证明最有帮助的Python库,我们选择 20 多个库,因为其中一些库是相互替代的,可以解决相同的问题。因此,我们将它们放在同一个分组。
核心库和统计数据
1. NumPy (提交:17911,撰稿人:641)
官网:http://www.numpy.org/
NumPy 是科学应用程序库的主要软件包之一,用于处理大型多维数组和矩阵,它大量的高级数学函数集合和实现方法使得这些对象执行操作成为可能。
2. SciPy (提交:19150,撰稿人:608)
官网:https://scipy.org/scipylib/
科学计算的另一个核心库是 SciPy。它基于 NumPy,其功能也因此得到了扩展。SciPy 主数据结构又是一个多维数组,由 Numpy 实现。这个软件包包含了帮助解决线性代数、概率论、积分计算和许多其他任务的工具。此外,SciPy 还封装了许多新的 BLAS 和 LAPACK 函数。
3. Pandas (提交:17144,撰稿人:1165
官网:https://pandas.pydata.org/
Pandas 是一个 Python 库,提供高级的数据结构和各种各样的分析工具。这个软件包的主要特点是能够将相当复杂的数据操作转换为一两个命令。Pandas包含许多用于分组、过滤和组合数据的内置方法,以及时间序列功能。
4. StatsModels (提交:10067,贡献者:153)
官网:http://www.statsmodels.org/devel/
Statsmodels 是一个 Python 模块,它为统计数据分析提供了许多机会,例如统计模型估计、执行统计测试等。在它的帮助下,你可以实现许多机器学习方法并探索不同的绘图可能性。
Python 库不断发展,不断丰富新的机遇。因此,今年出现了时间序列的改进和新的计数模型,即 GeneralizedPoisson、零膨胀模型(zero inflated models)和 NegativeBinomialP,以及新的多元方法:因子分析、多元方差分析以及方差分析中的重复测量。
可视化
5. Matplotlib (提交:25747,撰稿人:725)
官网:https://matplotlib.org/index.html
Matplotlib 是一个用于创建二维图和图形的底层库。藉由它的帮助,你可以构建各种不同的图标,从直方图和散点图到费笛卡尔坐标图。此外,有许多流行的绘图库被设计为与matplotlib结合使用。
6. Seaborn(提交人:2044,撰稿人:83)
官网:https://seaborn.pydata.org/
Seaborn 本质上是一个基于 matplotlib 库的高级 API。它包含更适合处理图表的默认设置。此外,还有丰富的可视化库,包括一些复杂类型,如时间序列、联合分布图(jointplots)和小提琴图(violin diagrams)。
7. Plotly (提交:2906,撰稿人:48)
官网:https://plot.ly/python/
Plotly 是一个流行的库,它可以让你轻松构建复杂的图形。该软件包适用于交互式 Web 应用程,其卓越的可视化效果包括轮廓图形,三元图和3D图表。
8. Bokeh (提交:16983,撰稿人:294)
官网:https://bokeh.pydata.org/en/latest/
Bokeh 库使用 JavaScript 小部件在浏览器中创建交互式和可缩放的可视化。该库提供了多种图表集合,样式可能性(styling possibilities),链接图、添加小部件和定义回调等形式的交互能力,以及许多更有用的特性。
9. Pydot (提交:169,撰稿人:12)
官网:https://pypi.org/project/pydot/
Pydot 是一个用于生成复杂的定向图和无向图的库。它是用纯 Python 编写的Graphviz 接口。在它的帮助下,可以显示图形的结构,这在构建神经网络和基于决策树的算法时经常用到。
机器学习
10. Scikit-learn (提交:22753,撰稿人:1084)
官网:http://scikit-learn.org/stable/
这个基于 NumPy 和 SciPy 的 Python 模块是处理数据的最佳库之一。它为许多标准的机器学习和数据挖掘任务提供算法,如聚类、回归、分类、降维和模型选择。
Data Science School:http://datascience-school.com/
11. XGBoost / LightGBM / CatBoost (提交:3277/1083/1509,撰稿人:280/79/61)
官网:
http://xgboost.readthedocs.io/en/latest/http://lightgbm.readthedocs.io/en/latest/Python-Intro.htmlhttps://github.com/catboost/catboost
梯度增强算法是最流行的机器学习算法之一,它是建立一个不断改进的基本模型,即决策树。因此,为了快速、方便地实现这个方法而设计了专门库。就是说,我们认为 XGBoost、LightGBM 和 CatBoost 值得特别关注。它们都是解决常见问题的竞争者,并且使用方式几乎相同。这些库提供了高度优化的、可扩展的、快速的梯度增强实现,这使得它们在数据科学家和 Kaggle 竞争对手中非常流行,因为在这些算法的帮助下赢得了许多比赛。
12. Eli5 (提交:922,撰稿人:6)
官网:https://eli5.readthedocs.io/en/latest/
通常情况下,机器学习模型预测的结果并不完全清楚,这正是 Eli5 帮助应对的挑战。它是一个用于可视化和调试机器学习模型并逐步跟踪算法工作的软件包,为 scikit-learn、XGBoost、LightGBM、lightning 和 sklearn-crfsuite 库提供支持,并为每个库执行不同的任务。
深度学习
13. TensorFlow(提交:33339,撰稿人:1469)
官网:https://www.tensorflow.org/
TensorFlow 是一个流行的深度学习和机器学习框架,由 Google Brain 开发。它提供了使用具有多个数据集的人工神经网络的能力。在最流行的 TensorFlow应用中有目标识别、语音识别等。在常规的 TensorFlow 上也有不同的 leyer-helper,如 tflearn、tf-slim、skflow 等。
14. PyTorch(提交:11306,撰稿人:635)
官网:https://pytorch.org/
PyTorch 是一个大型框架,它允许使用 GPU 加速执行张量计算,创建动态计算图并自动计算梯度。在此之上,PyTorch 为解决与神经网络相关的应用程序提供了丰富的 API。该库基于 Torch,是用 C 实现的开源深度学习库。在Lua中有一个包装器。Python API于2017年推出,从那时起,该框架越来越受欢迎并吸引了越来越多的数据科学家。
15. Keras (提交人:4539,撰稿人:671)
官网:https://keras.io/
Keras 是一个用于处理神经网络的高级库,运行在 TensorFlow、Theano 之上,
现在作为新版本的结果,它也可以使用CNTK和MxNet作为后端。它简化了许多特定任务,并大大减少了单调代码的数量。但是,它可能不适合某些复杂的事情。
该库面临性能,可用性,文档和API改进。一些新功能是Conv3DTranspose 层,新的MobileNet 应用程序和自我规范化网络。
分布式深度学习
16. Dist-keras / elephas / spark-deep-learning(提交:1125/170/67,撰稿人:5/13/11)
官网:
http://joerihermans.com/work/distributed-keras/https://pypi.org/project/elephas/https://databricks.github.io/spark-deep-learning/site/index.html
随着越来越多的用例需要花费大量的精力和时间,深度学习问题变得越来越重要。然而,使用像 Apache Spark 这样的分布式计算系统,处理如此多的数据要容易得多,这再次扩展了深入学习的可能性。因此,dist-keras、elephas 和 spark-deep-learning 都在迅速流行和发展,而且很难挑出一个库,因为它们都是为解决共同的任务而设计的。这些包允许你在 Apache Spark 的帮助下直接训练基于 Keras 库的神经网络。Spark-deep-learning 还提供了使用 Python 神经网络创建管道的工具。
自然语言处理
17. NLTK(提交:13041,撰稿人:236)
官网:https://www.nltk.org/
NLTK 是一组库,一个用于自然语言处理的完整平台。在 NLTK 的帮助下,你可以以各种方式处理和分析文本,对文本进行标记和标记,提取信息等。NLTK 也用于原型设计和建立研究系统。
18. SpaCy (提交:8623,撰稿人:215)
官网:https://spacy.io/
SpaCy 是一个具有优秀示例、API 文档和演示应用程序的自然语言处理库。这个库是用 Cython 语言编写的,Cython 是 Python 的 C 扩展。它支持近 30 种语言,提供了简单的深度学习集成,保证了健壮性和高准确率。SpaCy 的另一个重要特性是专为整个文档处理设计的体系结构,无须将文档分解成短语。
19. Gensim (提交人:3603,撰稿人:273)
官网:https://radimrehurek.com/gensim/
Gensim 是一个用于健壮语义分析、主题建模和向量空间建模的 Python 库,构建在Numpy和Scipy之上。它提供了流行的NLP算法的实现,如 word2vec。尽管 gensim 有自己的 models.wrappers.fasttext实现,但 fasttext 库也可以用来高效学习词语表示。
数据采集
20. Scrapy (提交:6625,撰稿人:281)
官网:https://scrapy.org/
Scrapy 是一个用来创建网络爬虫,扫描网页和收集结构化数据的库。此外,Scrapy 可以从 API 中提取数据。由于该库的可扩展性和可移植性,使得它用起来非常方便。
结论
本文上述所列就是我们在 2018 年为数据科学领域中总结的 Python 库集合。一些新的现代库越来越受欢迎,而那些已经成为经典的数据科学任务的库也在不断改进。
当然仍可能还有一些值得关注的其他伟大而有用的库。因此,请在下面的评论部分分享您的最爱,以及有关我们提到的软件包的任何想法。
感谢您的关注!
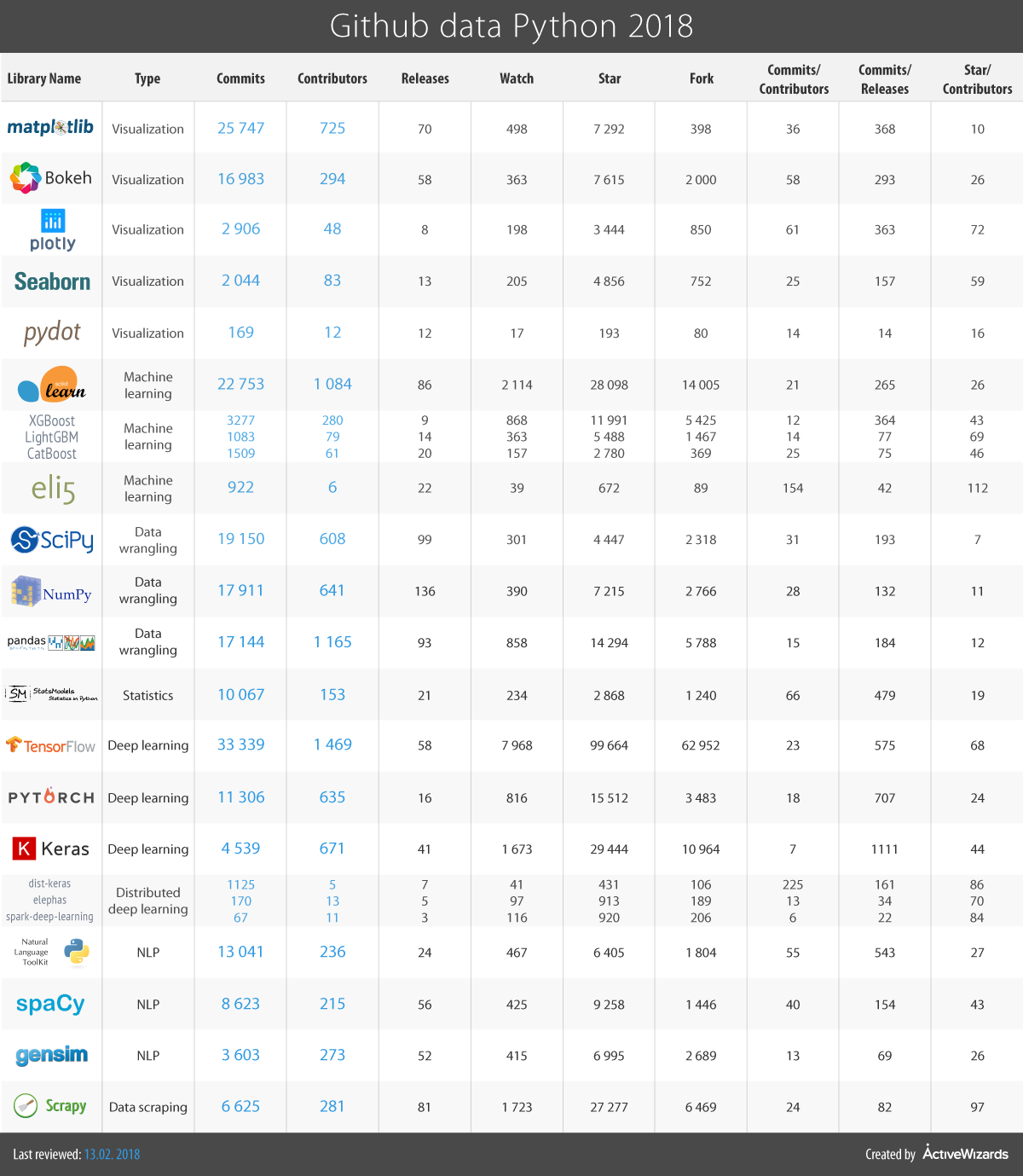
下表显示了github活动的详细统计信息。
原文链接:
https://activewizards.com/blog/top-20-python-libraries-for-data-science-in-2018/
2018年排名前20的数据科学Python库的更多相关文章
- 2017年排名前15的数据科学python库
2017年排名前15的数据科学python库 2017-05-22 Python程序员 Python程序员 Python程序员 微信号 pythonbuluo 功能介绍 最专业的Python社区,有每 ...
- 2016年GitHub排名前20的Python机器学习开源项目(转)
当今时代,开源是创新和技术快速发展的核心.本文来自 KDnuggets 的年度盘点,介绍了 2016 年排名前 20 的 Python 机器学习开源项目,在介绍的同时也会做一些有趣的分析以及谈一谈它们 ...
- 探讨2018年最受欢迎的15顶级Python库!
近日,数据科学网站 KDnuggets 评选出了顶级 Python 库 Top15,领域横跨数据科学.数据可视化.深度学习和机器学习.如果本文有哪些遗漏,你可以在评论区补充. 图 1:根据 GitHu ...
- 数据科学20个最好的Python库
Python 在解决数据科学任务和挑战方面继续处于领先地位.去年,我们曾发表一篇博客文章 Top 15 Python Libraries for Data Science in 2017,概述了当时业 ...
- Python数据科学“冷门”库
Python是一种神奇的语言.事实上,它是近几年世界上发展最快的编程语言之一,它一次又一次证明了它在开发工作和数据科学立场各行业的实用性.整个Python系统和库是对于世界各地的用户(无论是初学者或者 ...
- 20个必不可少的Python库也是基本的第三方库
个属于我常用工具的Python库,我相信你看完之后也会觉得离不开它们.他们是: Requests.Kenneth Reitz写的最富盛名的http库.每个Python程序员都应该有它. Scrapy. ...
- 20个必不可少的Python库
转载:http://www.python123.org/tutorials/58b41f2a28c8f30100bd41dc 读者们好.今天我将介绍20个属于我常用工具的Python库,我相信你看完之 ...
- 9 个鲜为人知的 Python 数据科学库
除了 pandas.scikit-learn 和 matplotlib,还要学习一些用 Python 进行数据科学的新技巧. Python 是一种令人惊叹的语言.事实上,它是世界上增长最快的编程语言之 ...
- 20个最有用的Python数据科学库
核心库与统计 1. NumPy(提交:17911,贡献者:641) 一般我们会将科学领域的库作为清单打头,NumPy 是该领域的主要软件库之一.它旨在处理大型的多维数组和矩阵,并提供了很多高级的数学函 ...
随机推荐
- 【第8篇】:Python之面向对象
python之--------封装 一.封装: 补充封装: 封装: 体现在两点: 1.数据的封装(将数据封装到对象中) obj = Foo('宝宝',22) 2.封装方法和属性,将一类操作封装到一个类 ...
- HDU1465 不容易系列之一&&HDU4535吉哥系列故事——礼尚往来
HDU1465不容易系列之一 Problem Description 大家常常感慨,要做好一件事情真的不容易,确实,失败比成功容易多了!做好“一件”事情尚且不易,若想永远成功而总从不失败,那更是难上加 ...
- 关于 BaseHTTPServer 的介绍
简介: (1) 基础的web服务器是一个模板,其其角色是客户端和服务器端完成必要的HTTP交互,在basehttpserver模块中可以找到一个名字叫HTTPServer 的服务器基本类 (2)处理程 ...
- PAT 1060. Are They Equal
If a machine can save only 3 significant digits, the float numbers 12300 and 12358.9 are considered ...
- [LeetCode] 887. Super Egg Drop 超级鸡蛋掉落
You are given K eggs, and you have access to a building with N floors from 1 to N. Each egg is iden ...
- unigui的菜单树补习【2】treeview
Treeview用于显示按照树形结构进行组织的数据. Treeview控件中一个树形图由节点(TreeNode)和连接线组成.TtreeNode是TTreeview的基本组成单元. ...
- 【codeforces 760D】Travel Card
[题目链接]:http://codeforces.com/contest/760/problem/D [题意] 去旅行,有3种类型的乘车票; 第一种:只能旅行一次20元 第二种:按时间计算,90分钟内 ...
- [HEOI 2016] sort
[HEOI 2016] sort 解题报告 码线段树快调废我了= = 其实这题貌似暴力分很足,直接$STL$的$SORT$就能$80$ 正解: 我们可以二分答案来做这道题 假设我们二分的答案为$a$, ...
- 利用Calendar类测试电脑运行速度
今天学习了很多新知识! 这里使用了Calender类来获取系统时间,并计算循环1w次的时间,判断电脑处理时间. import java.util.Calendar; public class Arra ...
- Ubuntu 17.10安装phpMyAdmin数据库管理工具
和Windows下各种双击安装直接使用的数据库管理工具不同,Linux下的数据库管理工具显得有些稍稍复杂.由于版权和收费限制,很多好用的数据库管理工具例如Data Grip和Navicat不能直接 ...