单个图片获取-爬取网易"数读"信息数据(暴涨的房租,正在摧毁中国年轻人的生活)
参考链接:https://www.makcyun.top/web_scraping_withpython3.html
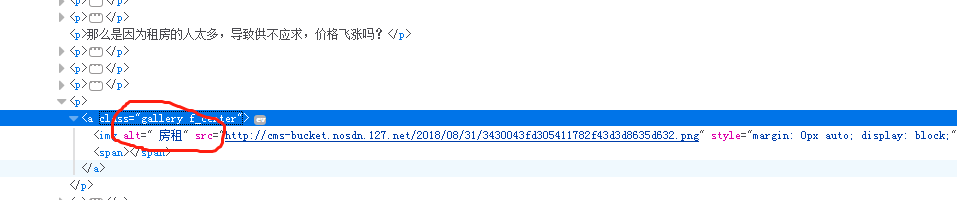
该网页其实有16张图片,但是因为页面数据中某处多个空白,导致参考链接中的方式只有15张图片,并且亲测有些方式能用,有些方式不能用,特此记录一下
正常显示:

不正常显示:
#!/usr/bin/env python
# -*- coding: utf-8 -*- import random
import re import requests
from bs4 import BeautifulSoup
from lxml import etree
from pyquery import PyQuery as pq
from requests import RequestException headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'
} def get_one_page():
url = 'http://data.163.com/18/0901/01/DQJ3D0D9000181IU.html'
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
except RequestException:
print('网页请求失败')
return None ### 如下是解析网页数据的5中方式 # 正则表达式
def parse_one_page1(html):
pattern = re.compile('<img alt=".*?租" src="(.*?)"', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'url': item
} # Xpath语法 # 使用这个('*//p//img[@alt = "房租"]/@src') 则结果只有15条,因为有个alt参数中房租前面有空格
def parse_one_page2(html):
parse = etree.HTML(html)
items = parse.xpath('*//img[@style="margin: 0px auto; display: block;" ]/@src')
for item in items:
yield {
'url': item
} # CSS选择器,结果有8条,还有待研究
def parse_one_page3(html):
soup = BeautifulSoup(html, 'lxml')
items = soup.select('p a img')
# print(items)
for item in items:
yield {
'url': item['src']
} # Beautiful Soup + find_all函数提取 结果有8条,还有待研究
def parse_one_page4(html):
soup = BeautifulSoup(html, 'lxml')
item = soup.find_all(attrs={'width': '100%', 'style': 'margin: 0px auto; display: block;'})
print(item)
for i in range(len(item)):
url = item[i].attrs['src']
yield {
'url': url
} # PyQuery
def parse_one_page5(html):
data = pq(html)
data2 = data('p>a>img')
for item in data2.items():
yield {
'url': item.attr('src')
} def download_thumb(url, name):
print(url, name)
try:
response = requests.get(url)
with open(name + '.jpg', 'wb') as f:
f.write(response.content)
except RequestException as e:
print(e)
pass def main():
html = get_one_page()
items = parse_one_page5(html)
for item in items:
# print(item['url'])
download_thumb(item['url'], str(random.randint(1, 1000))) if __name__ == '__main__':
main()
注:下载保存图片的函数还能再优化一下,不过懒得弄了,直接上随机数,哈哈
单个图片获取-爬取网易"数读"信息数据(暴涨的房租,正在摧毁中国年轻人的生活)的更多相关文章
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- Python scrapy框架爬取瓜子二手车信息数据
项目实施依赖: python,scrapy ,fiddler scrapy安装依赖的包: 可以到https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载 pywi ...
- 使用Jsoup 爬取网易首页所有的图片
package com.enation.newtest; import java.io.File; import java.io.FileNotFoundException; import java. ...
- 爬虫—Selenium爬取JD商品信息
一,抓取分析 本次目标是爬取京东商品信息,包括商品的图片,名称,价格,评价人数,店铺名称.抓取入口就是京东的搜索页面,这个链接可以通过直接构造参数访问https://search.jd.com/Sea ...
- 如何利用python爬取网易新闻
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: LSGOGroup PS:如有需要Python学习资料的小伙伴可以 ...
- 爬虫系列2:Requests+Xpath 爬取租房网站信息
Requests+Xpath 爬取租房网站信息 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参考前文 ...
- python itchat 爬取微信好友信息
原文链接:https://mp.weixin.qq.com/s/4EXgR4GkriTnAzVxluJxmg 「itchat」一个开源的微信个人接口,今天我们就用itchat爬取微信好友信息,无图言虚 ...
- 简单的python爬虫--爬取Taobao淘女郎信息
最近在学Python的爬虫,顺便就练习了一下爬取淘宝上的淘女郎信息:手法简单,由于淘宝网站本上做了很多的防爬措施,应此效果不太好! 爬虫的入口:https://mm.taobao.com/json/r ...
- [Python学习] 简单爬取CSDN下载资源信息
这是一篇Python爬取CSDN下载资源信息的样例,主要是通过urllib2获取CSDN某个人全部资源的资源URL.资源名称.下载次数.分数等信息.写这篇文章的原因是我想获取自己的资源全部的评论信息. ...
随机推荐
- 最全Linux 与 Linux Windows 文件共享
前提说明: windows主机信息:192.168.1.100 帐号:abc password:123 共享目录:share linux主机信息:192.168.1.200 帐号:def passwo ...
- ExtJS学习笔记3:载入、提交和验证表单
载入数据 1.比較好用的设置form数据的方法: formPanel.getForm().setValues([{id: 'FirstName', value: 'Joe'}]); 当中id值为for ...
- unity中 拖拽随意的对象
孙广东 2015.8.16 目的 : 我们能简单的通过 鼠标位置 得到目标对象 假设没有使用刚体组件 Step - 1: 在3D项目中设置场景. 一个空对象命名为: DragAndDrop ...
- CodeForces 754D Fedor and coupons&&CodeForces 822C Hacker, pack your bags!
D. Fedor and coupons time limit per test 4 seconds memory limit per test 256 megabytes input standar ...
- [CTSC 2008] 祭祀
[题目链接] https://www.lydsy.com/JudgeOnline/problem.php?id=1143 [算法] 答案为最小路径可重复点覆盖所包含的路径数,将原图G进行弗洛伊德传递闭 ...
- bzoj4078
二分+2-sat 枚举第一个权值,二分第二个权值,然后2-sat检查,当第一个权值已经不能形成二分图时,再往下没意义,因为没法分成两个点集.(双指针好像跑得慢) #include<bits/st ...
- A. Jeff and Digits(cf)
A. Jeff and Digits time limit per test 1 second memory limit per test 256 megabytes input standard i ...
- IE兼容性測試軟件
对于前端开发工程师来说,确保代码在各种主流浏览器的各个版本中都能正常工作是件很费时的事情,幸运的是,有很多优秀的工具可以帮助测试浏览器的兼容性,让我们一起看看这些很棒的工具. Spoon Browse ...
- 一个对象toString()方法如果没有被重写,那么默认调用它的父类Object的toString()方法,而Object的toString()方法是打印该对象的hashCode,一般hashCode就是此对象的内存地址
昨天因为要从JFrame控件获取密码,注意到一个问题,那就是用toString方法得到的不一定是你想要的,如下: jPasswordField是JFrame中的密码输入框,如果用下面的方法是得不到密码 ...
- BZOJ 2406 二分+有上下界的网络流判定
思路: 求出每行的和 sum_row 每列的和 sum_line 二分最后的答案mid S->i 流量[sum_row[i]-mid,sum_row[i]+mid] i->n+j ...