expectation-maximization algorithm ---- PRML读书笔记
An elegant and powerful method for finding maximum likelihood solutions for models with latent variables is called the expectation-maximization algorithm, or EM algorithm.
If we assume that the data points are drawn independently from the distribution, then the log of the likelihood function is given by
lnp(X|π,μ,Σ)=Σnln{ΣkπkN(xn|μk,Σk)}
EM for Gaussian Mixtures
Given a Gaussian mixture model, the goal is to maximize the likelihood function with respect to the parameters(comprising the means and covariances of the components
and the mixing coefficients).
1.Initialize the means μk, covariances Σk and mixing coefficients πk, and evaluate the initial value of the log likelihood.
2.E step. Evaluate the responsibilities using the current parameter values
3.M step. Re-estimate the parameters using the current responsibilities.
4.Evaluate the log likelihood
lnp(X|π,μ,Σ)=Σnln{ΣkπkN(xn|μk,Σk)}
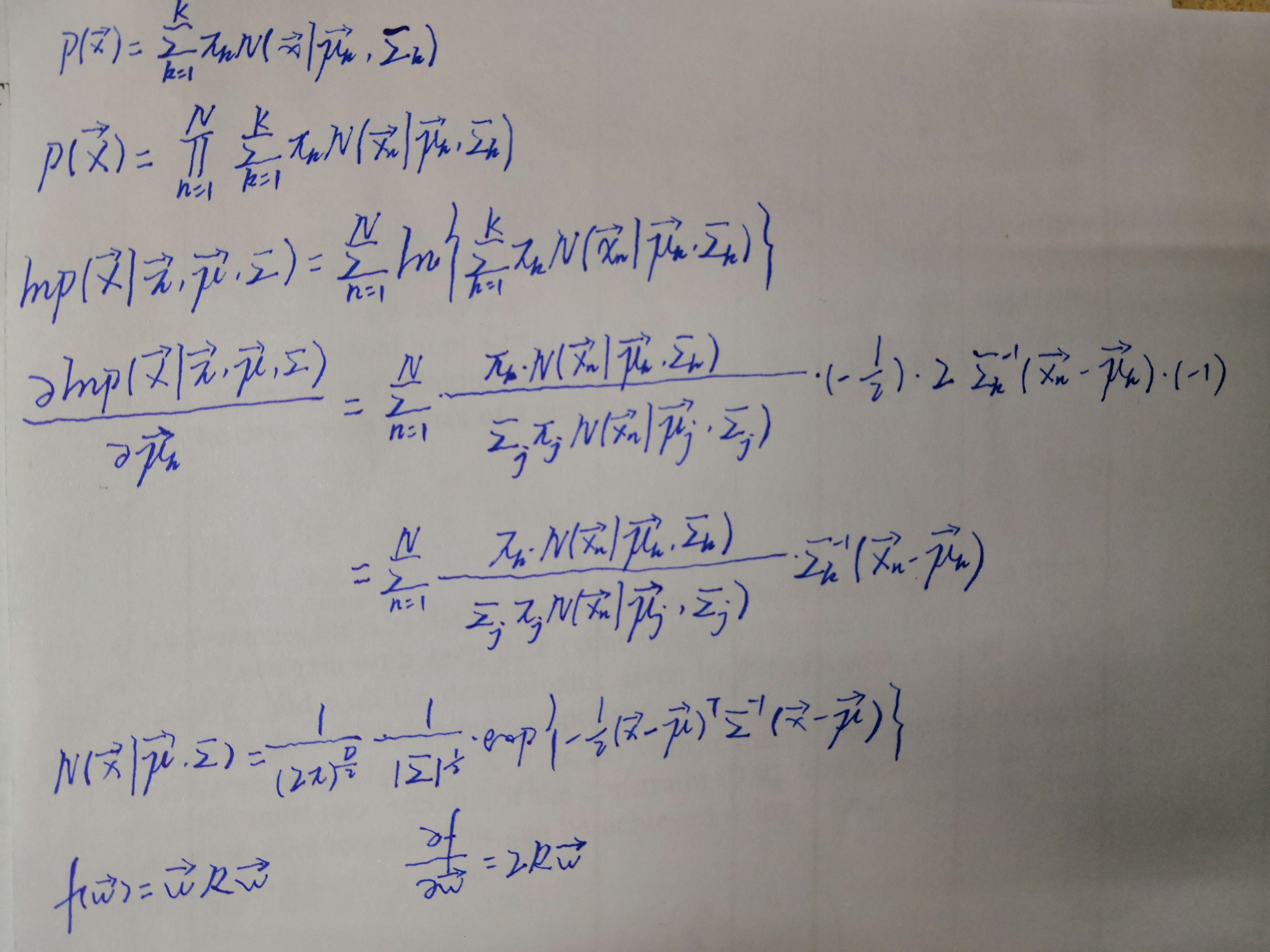
expectation-maximization algorithm ---- PRML读书笔记的更多相关文章
- EM算法(Expectation Maximization Algorithm)
EM算法(Expectation Maximization Algorithm) 1. 前言 这是本人写的第一篇博客(2013年4月5日发在cnblogs上,现在迁移过来),是学习李航老师的< ...
- EM算法(Expectation Maximization Algorithm)初探
1. 通过一个简单的例子直观上理解EM的核心思想 0x1: 问题背景 假设现在有两枚硬币Coin_a和Coin_b,随机抛掷后正面朝上/反面朝上的概率分别是 Coin_a:P1:-P1 Coin_b: ...
- [转]EM算法(Expectation Maximization Algorithm)详解
https://blog.csdn.net/zhihua_oba/article/details/73776553 EM算法(Expectation Maximization Algorithm)详解 ...
- PRML读书笔记——2 Probability Distributions
2.1. Binary Variables 1. Bernoulli distribution, p(x = 1|µ) = µ 2.Binomial distribution + 3.beta dis ...
- PRML读书笔记——3 Linear Models for Regression
Linear Basis Function Models 线性模型的一个关键属性是它是参数的一个线性函数,形式如下: w是参数,x可以是原始的数据,也可以是关于原始数据的一个函数值,这个函数就叫bas ...
- PRML读书笔记——Mathematical notation
x, a vector, and all vectors are assumed to be column vectors. M, denote matrices. xT, a row vcetor, ...
- PRML读书笔记——机器学习导论
什么是模式识别(Pattern Recognition)? 按照Bishop的定义,模式识别就是用机器学习的算法从数据中挖掘出有用的pattern. 人们很早就开始学习如何从大量的数据中发现隐藏在背后 ...
- PRML读书笔记_绪论
一.基本名词 泛化(generalization) 训练集所训练的模型对新数据的适用程度. 监督学习(supervised learning) 训练数据的样本包含输入向量以及对应的目标向量. 分类( ...
- Expectation Maximization Algorithm
期望最大化算法EM. 简介 EM算法即期望最大化算法,由Dempster等人在1976年提出[1].这是一种迭代法,用于求解含有隐变量的最大似然估计.最大后验概率估计问题.至于什么是隐变量,在后面会详 ...
随机推荐
- C#调用Win32 api时的内存操作
一般情况下,C#与Win 32 Api的互操作都表现的很一致:值类型传递结构体,一维.二维指针传递IntPtr.在Win32 分配内存时,可以通过IntPtr以类似移动指针的方式读取内存.通过IntP ...
- inflate(int resource, ViewGroup root, boolean attachToRoot)见解
/** * Inflate a new view hierarchy from the specified xml resource. Throws * {@link InflateException ...
- js获取图片信息(二)-----js获取img的height、width宽高值为0
首先,创建一个图片对象: var oImg= new Image(); oImg.src = "apple.jpg"; 然后我们打印一下图片的信息: console.log(oIm ...
- bat配置JDK环境变量
最近总是部署服务器,总是要安装配置JDK,今天就想写个bat来配置JDK的环境变量,首先介绍点bat的小知识 @符号后面的命令不会显示在terminal上 例如: @echo运行时 隐藏命令(不在te ...
- eclipse常用设置之项目分组查看
1.打开‘NaviNavigator’ 视图,windows-->show views->NaviNavigator; 2.在NaviNavigator视图下选择select workin ...
- 后台取前台input标签值方法
直接在实体类中增加一个get set方法就可以实现取到value值
- Appium 教您完美win10安装Appium1.7.2支持win客户端自动化
参考内容: https://testerhome.com/topics/10193https://testerhome.com/topics/8223https://testerhome.com/to ...
- PHP开发错误锦集(持续更新)
1.trait 命名问题. 问题:trait 里定义的方法找不到 <?php namespace app\controllers; trait Example { public function ...
- LINUX应用开发(面试)
LINUX应用开发工程师职位 本试卷从考试酷examcoo网站导出,文件格式为mht,请用WORD/WPS打开,并另存为doc/docx格式后再使用 说明:应用开发可考察的点非常多,关键的还是C语言和 ...
- selenium等待
简介 在selenium操作浏览器的过程中,每一次请求url,selenium都会等待页面加载完成以后, 才会将操作权限在交给我们的程序. 但是,由于ajax和各种JS代码的异步加载问题,当一个页面被 ...