机器学习框架ML.NET学习笔记【3】文本特征分析
一、要解决的问题
问题:常常一些单位或组织召开会议时需要录入会议记录,我们需要通过机器学习对用户输入的文本内容进行自动评判,合格或不合格。(同样的问题还类似垃圾短信检测、工作日志质量分析等。)
处理思路:我们人工对现有会议记录进行评判,标记合格或不合格,通过对这些记录的学习形成模型,学习算法仍采用二元分类的快速决策树算法,和上一篇文章不同,这次输入的特征值不再是浮点数,而是中文文本。这里就要涉及到文本特征提取。
为什么要进行文本特征提取呢?因为文本是人类的语言,符号文字序列不能直接传递给算法。而计算机程序算法只接受具有固定长度的数字矩阵特征向量(float或float数组),无法理解可变长度的文本文档。
常用的文本特征提取方法有如下几种:

以上只是需要了解大致的含义,我们不需要去实现一个文本特征提取的算法,只需要使用平台自带的方法就可以了。
系统自带的文本特征处理的方法,输入是一个字符串,要求将一个语句中的词语用空格分开,英语的句子中词汇是天生通过空格分割的,但中文句子不是,所以我们需要首先进行分词操作,具体流程如下:
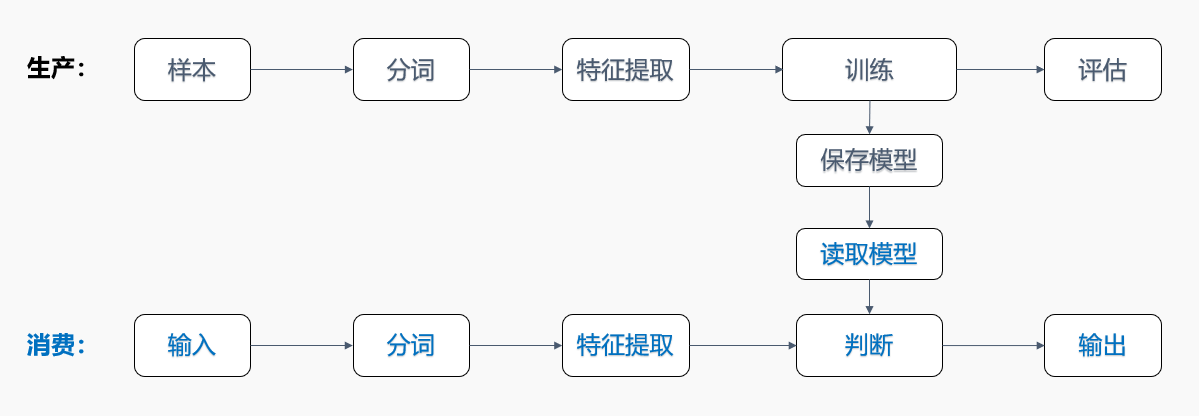
二、代码
代码整体流程和上一篇文章描述的基本一致,为简便起见,我们省略了模型存储和读取的过程。
先看一下数据集:

代码如下:
namespace BinaryClassification_TextFeaturize
{
class Program
{
static readonly string DataPath = Path.Combine(Environment.CurrentDirectory, "Data", "meeting_data_full.csv"); static void Main(string[] args)
{
MLContext mlContext = new MLContext();
var fulldata = mlContext.Data.LoadFromTextFile<MeetingInfo>(DataPath, separatorChar: ',', hasHeader: false);
var trainTestData = mlContext.Data.TrainTestSplit(fulldata, testFraction: 0.15);
var trainData = trainTestData.TrainSet;
var testData = trainTestData.TestSet; var trainingPipeline = mlContext.Transforms.CustomMapping<JiebaLambdaInput, JiebaLambdaOutput>(mapAction: JiebaLambda.MyAction, contractName: "JiebaLambda")
.Append(mlContext.Transforms.Text.FeaturizeText(outputColumnName: "Features", inputColumnName: "JiebaText"))
.Append(mlContext.BinaryClassification.Trainers.FastTree(labelColumnName: "Label", featureColumnName: "Features"));
ITransformer trainedModel = trainingPipeline.Fit(trainData); //评估
var predictions = trainedModel.Transform(testData);
var metrics = mlContext.BinaryClassification.Evaluate(data: predictions, labelColumnName: "Label");
Console.WriteLine($"Evalution Accuracy: {metrics.Accuracy:P2}"); //创建预测引擎
var predEngine = mlContext.Model.CreatePredictionEngine<MeetingInfo, PredictionResult>(trainedModel); //预测1
MeetingInfo sampleStatement1 = new MeetingInfo { Text = "支委会。" };
var predictionresult1 = predEngine.Predict(sampleStatement1);
Console.WriteLine($"{sampleStatement1.Text}:{predictionresult1.PredictedLabel}"); //预测2
MeetingInfo sampleStatement2 = new MeetingInfo { Text = "开展新时代中国特色社会主义思想三十讲党员答题活动。" };
var predictionresult2 = predEngine.Predict(sampleStatement2);
Console.WriteLine($"{sampleStatement2.Text}:{predictionresult2.PredictedLabel}"); Console.WriteLine("Press any to exit!");
Console.ReadKey();
} } public class MeetingInfo
{
[LoadColumn()]
public bool Label { get; set; }
[LoadColumn()]
public string Text { get; set; }
} public class PredictionResult : MeetingInfo
{
public string JiebaText { get; set; }
public float[] Features { get; set; }
public bool PredictedLabel;
public float Score;
public float Probability;
}
}
三、代码分析
和上一篇文章中相似的内容我就不再重复解释了,重点介绍一下学习管道的建立。
var trainingPipeline = mlContext.Transforms.CustomMapping<JiebaLambdaInput, JiebaLambdaOutput>(mapAction: JiebaLambda.MyAction, contractName: "JiebaLambda")
.Append(mlContext.Transforms.Text.FeaturizeText(outputColumnName: "Features", inputColumnName: "JiebaText"))
.Append(mlContext.BinaryClassification.Trainers.FastTree(labelColumnName: "Label", featureColumnName: "Features"));
首先,在进行文本特征转换之前,我们需要对文本进行分词操作,您可以对样本数据进行预处理,形成分词的结果再进行学习,我们没有采用这个方法,而是自定义了一个分词处理的数据处理管道,通过这个管道进行分词,其定义如下:
namespace BinaryClassification_TextFeaturize
{
public class JiebaLambdaInput
{
public string Text { get; set; }
} public class JiebaLambdaOutput
{
public string JiebaText { get; set; }
} public class JiebaLambda
{
public static void MyAction(JiebaLambdaInput input, JiebaLambdaOutput output)
{
JiebaNet.Segmenter.JiebaSegmenter jiebaSegmenter = new JiebaNet.Segmenter.JiebaSegmenter();
output.JiebaText = string.Join(" ", jiebaSegmenter.Cut(input.Text));
}
}
}
最后我们新建了两个对象进行实际预测:
//预测1
MeetingInfo sampleStatement1 = new MeetingInfo { Text = "支委会。" };
var predictionresult1 = predEngine.Predict(sampleStatement1);
Console.WriteLine($"{sampleStatement1.Text}:{predictionresult1.PredictedLabel}"); //预测2
MeetingInfo sampleStatement2 = new MeetingInfo { Text = "开展新时代中国特色社会主义思想三十讲党员答题活动。" };
var predictionresult2 = predEngine.Predict(sampleStatement2);
Console.WriteLine($"{sampleStatement2.Text}:{predictionresult2.PredictedLabel}");
预测结果如下:

四、调试
上一篇文章提到,当我们运行Transform方法时,会对所有记录进行转换,转换后的数据集是什么样子呢,我们可以写一个调试程序看一下。
var predictions = trainedModel.Transform(testData);
DebugData(mlContext, predictions); private static void DebugData(MLContext mlContext, IDataView predictions)
{
var trainDataShow = new List<PredictionResult>(mlContext.Data.CreateEnumerable<PredictionResult>(predictions, false, true)); foreach (var dataline in trainDataShow)
{
dataline.PrintToConsole();
}
} public class PredictionResult
{
public string JiebaText { get; set; }
public float[] Features { get; set; }
public bool PredictedLabel;
public float Score;
public float Probability;
public void PrintToConsole()
{
Console.WriteLine($"JiebaText={JiebaText}");
Console.WriteLine($"PredictedLabel:{PredictedLabel},Score:{Score},Probability:{Probability}");
Console.WriteLine($"TextFeatures Length:{Features.Length}");
if (Features != null)
{
foreach (var f in Features)
{
Console.Write($"{f},");
}
Console.WriteLine();
}
Console.WriteLine();
}
}
通过对调试结果的分析,可以看到整个数据处理管道的工作流程。
五、资源获取
源码下载地址:https://github.com/seabluescn/Study_ML.NET
工程名称:BinaryClassification_TextFeaturize
机器学习框架ML.NET学习笔记【3】文本特征分析的更多相关文章
- 机器学习框架ML.NET学习笔记【4】多元分类之手写数字识别
一.问题与解决方案 通过多元分类算法进行手写数字识别,手写数字的图片分辨率为8*8的灰度图片.已经预先进行过处理,读取了各像素点的灰度值,并进行了标记. 其中第0列是序号(不参与运算).1-64列是像 ...
- 机器学习框架ML.NET学习笔记【1】基本概念与系列文章目录
一.序言 微软的机器学习框架于2018年5月出了0.1版本,2019年5月发布1.0版本.期间各版本之间差异(包括命名空间.方法等)还是比较大的,随着1.0版发布,应该是趋于稳定了.之前在园子里也看到 ...
- 机器学习框架ML.NET学习笔记【2】入门之二元分类
一.准备样本 接上一篇文章提到的问题:根据一个人的身高.体重来判断一个人的身材是否很好.但我手上没有样本数据,只能伪造一批数据了,伪造的数据比较标准,用来学习还是蛮合适的. 下面是我用来伪造数据的代码 ...
- 机器学习框架ML.NET学习笔记【5】多元分类之手写数字识别(续)
一.概述 上一篇文章我们利用ML.NET的多元分类算法实现了一个手写数字识别的例子,这个例子存在一个问题,就是输入的数据是预处理过的,很不直观,这次我们要直接通过图片来进行学习和判断.思路很简单,就是 ...
- 机器学习框架ML.NET学习笔记【6】TensorFlow图片分类
一.概述 通过之前两篇文章的学习,我们应该已经了解了多元分类的工作原理,图片的分类其流程和之前完全一致,其中最核心的问题就是特征的提取,只要完成特征提取,分类算法就很好处理了,具体流程如下: 之前介绍 ...
- 机器学习框架ML.NET学习笔记【7】人物图片颜值判断
一.概述 这次要解决的问题是输入一张照片,输出人物的颜值数据. 学习样本来源于华南理工大学发布的SCUT-FBP5500数据集,数据集包括 5500 人,每人按颜值魅力打分,分值在 1 到 5 分之间 ...
- 机器学习框架ML.NET学习笔记【8】目标检测(采用YOLO2模型)
一.概述 本篇文章介绍通过YOLO模型进行目标识别的应用,原始代码来源于:https://github.com/dotnet/machinelearning-samples 实现的功能是输入一张图片, ...
- 机器学习框架ML.NET学习笔记【9】自动学习
一.概述 本篇我们首先通过回归算法实现一个葡萄酒品质预测的程序,然后通过AutoML的方法再重新实现,通过对比两种实现方式来学习AutoML的应用. 首先数据集来自于竞赛网站kaggle.com的UC ...
- ML.NET学习笔记 ---- 系列文章
机器学习框架ML.NET学习笔记[1]基本概念与系列文章目录 机器学习框架ML.NET学习笔记[2]入门之二元分类 机器学习框架ML.NET学习笔记[3]文本特征分析 机器学习框架ML.NET学习笔记 ...
随机推荐
- HDOJ1025(最长上升子序列)
Constructing Roads In JGShining's Kingdom Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65 ...
- java中的接口和抽象类的区别
1.接口从用户的角度(使用实现的代码)看问题. 2.接口由编译器强制的一个模块间协作的合约. 3.无成员变量. 4.成员函数只能声明不能实现,(jdk1.8中的default 方法可以有方法体). 接 ...
- 问题:request.Headers;结果:HttpWebRequest.Headers 属性
指定构成 HTTP 标头的名称/值对的集合. Headers 集合包含与请求关联的协议标头.下表列出了由系统或由属性或方法设置但未存储在 Headers 中的 HTTP 标头. 标头 设置方 Ac ...
- 服务器修改密码cmd
net user 账号 要修改的密码
- [hdu1176]免费馅饼(数塔dp)
题意:中文题,不解释了 = = 解题关键:逆推,转化为数塔dp就可以了 dp[i][j]表示在i秒j位置的最大值. 转移方程:$dp[i][j] = \max (dp[i + 1][j],dp[i + ...
- sklearn实现聚类
import numpy as np from sklearn import datasets from sklearn.cross_validation import train_test_spli ...
- p4180 次小生成树
传送门 分析: 次小生成树的求法有两种,最大众的一种是通过倍增LCA找环中最大边求解,而这里我介绍一种神奇的O(nlogn) 做法: 我们先建立最小生成树,因为我们用kruskal求解是边的大小已经按 ...
- 6.6 chmod的使用
从公司拷贝了白天整理的笔记,拿回家整理,结果发现有锁,无法对其解压.解决方案如上: ll 命令,查看其权限. sudo chmod 777 Picture.tar-1修改权限. 然后,可以正常打开Pc ...
- HDU 5973 Game of Taking Stones (威佐夫博弈+高精度)
题意:给定两堆石子,每个人可以从任意一堆拿任意个,也可以从两堆中拿相同的数量,问谁赢. 析:直接运用威佐夫博弈,floor(abs(a, b) * (sqrt(5)+1)/2) == min(a, b ...
- 【mysql模糊查询的几种方式】
select * from activyty_code where acname like '%yj%' 1:%:表示任意0个或多个字符.可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分 ...