【Python3 爬虫】16_抓取腾讯视频评论内容
上一节我们已经知道如何使用Fiddler进行抓包分析,那么接下来我们开始完成一个简单的小例子
抓取腾讯视频的评论内容
首先我们打开腾讯视频的官网https://v.qq.com/

我们打开【电视剧】这一栏,找到一部比较精彩的电视剧爬取一下,例如:我们就爬取【下一站,别离】这部吧
我们找到这部电视剧的评论如下图:
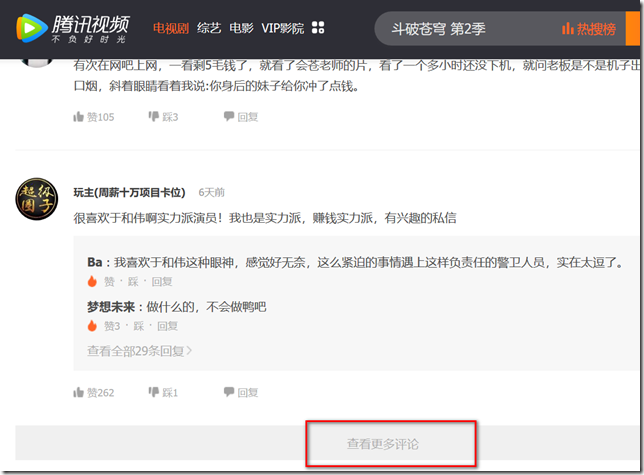
我们看到上图标记部分【查看更多评论】
我们首先在Fiddelr中使用命令clear清除之前浏览的记录
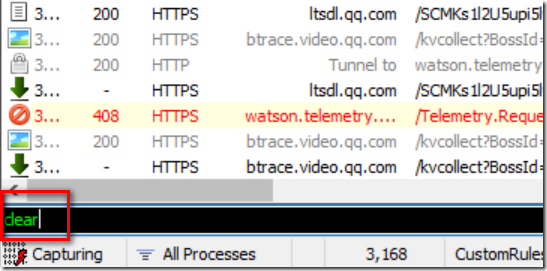
输入命令直接回车即可
接着我们点击【查看更多评论】,此时再次看Fiddler,我们可以看到【JS】这个小图标
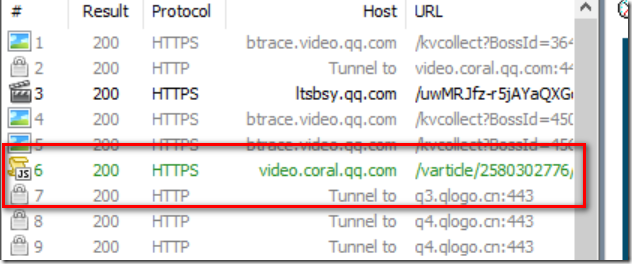
我们右键上图标记部分
第一次点击
接着【Copy】---【Just Url】
地址为:
我们将此地址放到浏览器查看效果如何?

现在我们还没发现什么规律,那我们再点击一次
第二次点击
浏览器显示

我们将上述2个地址放在word进行分析后,分析结果如下:
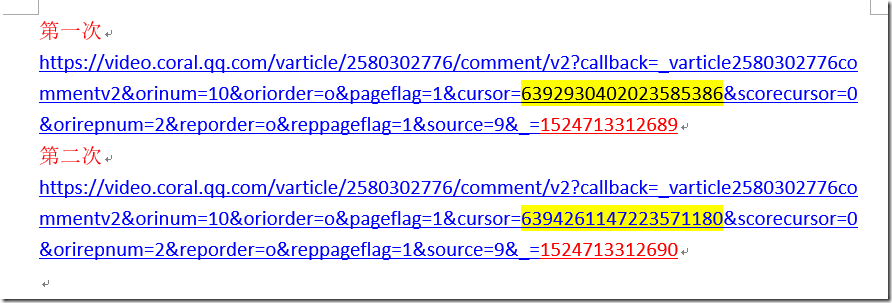
我们可以看到黄色标记部分没什么规律,最后红色标记是按1递增
那么我们验证下黄色标记部分是否是必须的呢?删除黄色部分放在浏览器执行,查看结果,有没有黄色部分结果一致,那么我们接下来开始代码了
import urllib.request
import re
import urllib.error
headers=("User_Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0")
#自定义opener
opener = urllib.request.build_opener()
opener.addheaders = [headers]
urllib.request.install_opener(opener) cursor_id = '6394260346548095809'
v_id =1524402700840
url = "https://video.coral.qq.com/varticle/2580302776/comment/v2?callback=_varticle2580302776commentv2&orinum=10&oriorder=o&pageflag=1&cursor="+cursor_id+"&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=9&_="+str(v_id)
for i in range(0,10):
content = urllib.request.urlopen(url).read().decode("utf-8")
patnext = '"last":"(.*?)"'
nextid = re.compile(patnext).findall(content)[0]
patcomment = '"content":"(.*?)",'
comment_content = re.compile(patcomment).findall(content)
for j in range(1,len(comment_content)):
print("-----第"+str(i)+str(j)+"条评论内容是:")
#print(eval("u"+"\'"+comment_content[j]+"\'"))
try:
t1 = comment_content[j].encode('latin-1').decode('unicode_escape')
print(t1)
except Exception as e:
print("***********该条评论含有有特殊字符************")
url="https://video.coral.qq.com/varticle/2580302776/comment/v2?callback=_varticle2580302776commentv2&orinum=10&oriorder=o&pageflag=1&cursor="+nextid+"&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=9&_="+str(v_id+i)
【Python3 爬虫】16_抓取腾讯视频评论内容的更多相关文章
- Python爬虫实现抓取腾讯视频所有电影【实战必学】
2019-06-27 23:51:51 阅读数 407 收藏 更多 分类专栏: python爬虫 前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问 ...
- 用python实现的抓取腾讯视频所有电影的爬虫
1. [代码]用python实现的抓取腾讯视频所有电影的爬虫 # -*- coding: utf-8 -*-# by awakenjoys. my site: www.dianying.atim ...
- java爬虫抓取腾讯漫画评论
package com.eteclab.wodm.utils; import java.io.BufferedWriter; import java.io.File; import java.io.F ...
- 用python 抓取B站视频评论,制作词云
python 作为爬虫利器,与其有很多强大的第三方库是分不开的,今天说的爬取B站的视频评论,其实重点在分析得到的评论化作嵌套的字典,在其中取出想要的内容.层层嵌套,眼花缭乱,分析时应细致!步骤分为以下 ...
- Python爬虫,抓取淘宝商品评论内容!
作为一个资深吃货,网购各种零食是很频繁的,但是能否在浩瀚的商品库中找到合适的东西,就只能参考评论了!今天给大家分享用python做个抓取淘宝商品评论的小爬虫! 思路 我们就拿"德州扒鸡&qu ...
- python 爬取腾讯视频评论
import urllib.request import re import urllib.error headers=('user-agent','Mozilla/5.0 (Windows NT 1 ...
- Python爬虫实战:爬取腾讯视频的评论
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 易某某 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- python爬虫(3)——用户和IP代理池、抓包分析、异步请求数据、腾讯视频评论爬虫
用户代理池 用户代理池就是将不同的用户代理组建成为一个池子,随后随机调用. 作用:每次访问代表使用的浏览器不一样 import urllib.request import re import rand ...
- python 爬取腾讯视频的全部评论
一.网址分析 查阅了网上的大部分资料,大概都是通过抓包获取.但是抓包有点麻烦,尝试了F12,也可以获取到评论.以电视剧<在一起>为例子.评论最底端有个查看更多评论猜测过去应该是 Ajax ...
随机推荐
- 如果想从jenkins直接生成docker镜像,并推送到harbor中,最简单的脚本如何实现?
如果不考虑意外, 第一版最简单的构思如下: #!/usr/bin/env python # -*- coding: utf-8 -*- import getopt, sys import subpro ...
- docker官方文档中的dns,link,expose,publish
link是过时的了,尽量不要用. dns内部集成,也可以用外部. expose只是用于记录,并不真的. publish是否起作用,也要看情况,是否被占用端口. -------------------- ...
- Bot Framework测试
在开发完成Bot Framework后,在本机的模拟器都是成功的,但未知在发布后会出现什么样的问题,所以需要将本机发布的站点给到Bot 1.在Bot Framework注册一个Bot,打开Bot Fr ...
- [centos6.5] 把xampp的htdocs改为其他目录
vim /opt/lampp/etc/httpd.conf DocumentRoot "/opt/lampp/htdocs" 改为 DocumentRoot "/var/ ...
- 洛谷 P3927 SAC E#1 - 一道中档题 Factorial【数论//】
题目描述 SOL君很喜欢阶乘.而SOL菌很喜欢研究进制. 这一天,SOL君跟SOL菌炫技,随口算出了n的阶乘. SOL菌表示不服,立刻就要算这个数在k进制表示下末尾0的个数. 但是SOL菌太菜了于是请 ...
- pthread条件变量
pthread条件变量等待条件有两种方式:无条件等待pthread_cond_wait()和计时等待pthread_cond_timedwait(),其中计时等待方式如果在给定时刻前条件没有满足,则返 ...
- 35、Django实战第35天:完善点击数/ 收藏数
点击数--课程 当我们进入一个课程的详情页的时候,点击数+1 当我们点击“我要学习”的时候,该课程的学习人数+1 点击数--教师 当我们进入一个讲师的详情页的时候,点击数+1 点击数--机构 当我们进 ...
- Android的日志工具Log
Android中的日志工具类是Log(android.util.Log),这个类提供了以下几个方法来供我们打印日志. ♦ Log.v():这个方法用于打印那些最为琐碎的,意义最小的日志信息.对应级别v ...
- [BZOJ 4720] 换教室
Link: BZOJ 4720 传送门 Solution: 2016年$NOIP$考的一道语文题 题面虽长,但思路并不难想 对于这类期望问题,大多数时候都用期望$dp$来解决 根据询问:在$n$个时间 ...
- POJ 3246 Game(凸包)
[题目链接] http://poj.org/problem?id=3246 [题目大意] 给出一些点,请删去一个点,使得包围这些点用的线长最短 [题解] 去掉的点肯定是凸包上的点,所以枚举凸包上的点去 ...