吴裕雄 python 机器学习——模型选择参数优化随机搜索寻优RandomizedSearchCV模型
import scipy from sklearn.datasets import load_digits
from sklearn.metrics import classification_report
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV,RandomizedSearchCV #模型选择参数优化随机搜索寻优RandomizedSearchCV模型
def test_RandomizedSearchCV():
'''
测试 RandomizedSearchCV 的用法。使用 LogisticRegression 作为分类器,主要优化 C、multi_class 等参数。其中 C 的分布函数为指数分布
'''
### 加载数据
digits = load_digits()
X_train,X_test,y_train,y_test=train_test_split(digits.data, digits.target,test_size=0.25,random_state=0,stratify=digits.target)
#### 参数优化 ######
tuned_parameters ={ 'C': scipy.stats.expon(scale=100), # 指数分布
'multi_class': ['ovr','multinomial']}
clf=RandomizedSearchCV(LogisticRegression(penalty='l2',solver='lbfgs',tol=1e-6),tuned_parameters,cv=10,scoring="accuracy",n_iter=100)
clf.fit(X_train,y_train)
print("Best parameters set found:",clf.best_params_)
print("Randomized Grid scores:")
# for params, mean_score, scores in clf.fit_params,clf.mean_score,clf.score:
# print("\t%0.3f (+/-%0.03f) for %s" % (mean_score, scores() * 2, params))
# print("\t%0.3f (+/-%0.03f) for %s" % (clf.mean_score,clf.score * 2, clf.fit_params))
print(clf) print("Optimized Score:",clf.score(X_test,y_test))
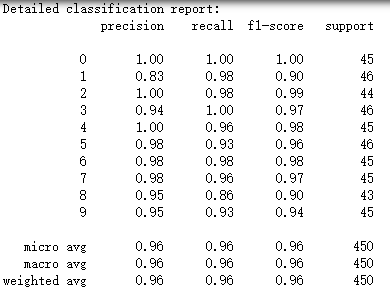
print("Detailed classification report:")
y_true, y_pred = y_test, clf.predict(X_test)
print(classification_report(y_true, y_pred)) #调用RandomizedSearchCV()
test_RandomizedSearchCV()

吴裕雄 python 机器学习——模型选择参数优化随机搜索寻优RandomizedSearchCV模型的更多相关文章
- 吴裕雄 python 机器学习——模型选择参数优化暴力搜索寻优GridSearchCV模型
import scipy from sklearn.datasets import load_digits from sklearn.metrics import classification_rep ...
- 吴裕雄 python 机器学习——模型选择验证曲线validation_curve模型
import numpy as np import matplotlib.pyplot as plt from sklearn.svm import LinearSVC from sklearn.da ...
- 吴裕雄 python 机器学习——模型选择学习曲线learning_curve模型
import numpy as np import matplotlib.pyplot as plt from sklearn.svm import LinearSVC from sklearn.da ...
- 吴裕雄 python 机器学习——模型选择回归问题性能度量
from sklearn.metrics import mean_absolute_error,mean_squared_error #模型选择回归问题性能度量mean_absolute_error模 ...
- 吴裕雄 python 机器学习——模型选择分类问题性能度量
import numpy as np import matplotlib.pyplot as plt from sklearn.svm import SVC from sklearn.datasets ...
- 吴裕雄 python 机器学习——模型选择数据集切分
import numpy as np from sklearn.model_selection import train_test_split,KFold,StratifiedKFold,LeaveO ...
- 吴裕雄 python 机器学习——模型选择损失函数模型
from sklearn.metrics import zero_one_loss,log_loss def test_zero_one_loss(): y_true=[1,1,1,1,1,0,0,0 ...
- 吴裕雄 python 机器学习——分类决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
随机推荐
- Java EE 7 API
学习Java必备资源,下载链接: https://pan.baidu.com/s/1P1xzuoGJCIuZlYBbPSbM_Q 提取码: dtui 复制这段内容后打开百度网盘手机App,操作更方便哦
- 【网站】Kiwi浏览器中文网
2020年1月1日上线 访问地址:http://huangenet.gitee.io/kiwibrowser/
- c#字符串常用方法
一.字符串常用方法 1.IndexOf("") 如果找到字符串出现的位置则为索引位置,否则返回-1,索引从0开始 2.string Substring( int sta ...
- SpringBoot开发快速入门
SpringBoot开发快速入门 目录 一.Spring Boot 入门 1.Spring Boot 简介 2.微服务 3.环境准备 1.maven设置: 2.IDEA设置 4.Spring Boot ...
- python hashlib 详解
1.概述 摘要算法简介 Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等. 什么是摘要算法呢?摘要算法又称哈希算法.散列算法.它通过一个函数,把任意长度的数据转换为一个长度固定 ...
- No serializer found for class org.hibernate.proxy.pojo.bytebuddy.ByteBuddyInterceptor
使用jpa做增删改查的时候出现了这个异常,原因是转化成json的时候,fasterxml.jackson将对象转换为json报错,发现有字段为null 解决方案:实体类上添加 @JsonIgnoreP ...
- 阿里云MySQL安装到centos,并链接。
Last login: Wed Jan 22 11:21:17 on ttys001 wulaguixiaomianyangdeMacBook-Pro:~ xingwen$ ssh root@47.9 ...
- JS高级---函数中的this的指向,函数的不同调用方式
函数中的this的指向 普通函数中的this是谁?-----window 对象.方法中的this是谁?----当前的实例对象 定时器方法中的this是谁?----window 构造函数中的this是谁 ...
- python 操作 word 图片 消失
问题描述修改word中文本,如下代码,保存时会导致word中的部分图片消失 from docx import Document path1 = 'test_in.docx' path2 = 'test ...
- window10配置远程虚拟机window7上的mysql5.7数据源
原文链接:http://www.xitongcheng.com/jiaocheng/win10_article_18644.html windows10系统用户想要在电脑中设置ODBC数据源,于是手动 ...