吴裕雄 python 机器学习——模型选择学习曲线learning_curve模型
import numpy as np
import matplotlib.pyplot as plt from sklearn.svm import LinearSVC
from sklearn.datasets import load_digits
from sklearn.model_selection import learning_curve #模型选择学习曲线learning_curve模型
def test_learning_curve():
### 加载数据
digits = load_digits()
X,y=digits.data,digits.target
#### 获取学习曲线 ######
train_sizes=np.linspace(0.1,1.0,endpoint=True,dtype='float')
abs_trains_sizes,train_scores, test_scores = learning_curve(LinearSVC(),X, y,cv=10, scoring="accuracy",train_sizes=train_sizes)
###### 对每个 C ,获取 10 折交叉上的预测得分上的均值和方差 #####
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
####### 绘图 ######
fig=plt.figure()
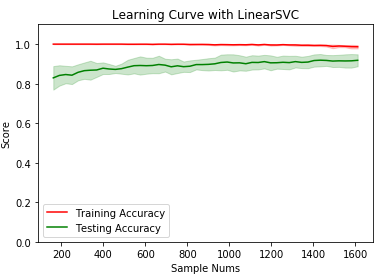
ax=fig.add_subplot(1,1,1) ax.plot(abs_trains_sizes, train_scores_mean, label="Training Accuracy", color="r")
ax.fill_between(abs_trains_sizes, train_scores_mean - train_scores_std,train_scores_mean + train_scores_std, alpha=0.2, color="r")
ax.plot(abs_trains_sizes, test_scores_mean, label="Testing Accuracy", color="g")
ax.fill_between(abs_trains_sizes, test_scores_mean - test_scores_std,test_scores_mean + test_scores_std, alpha=0.2, color="g") ax.set_title("Learning Curve with LinearSVC")
ax.set_xlabel("Sample Nums")
ax.set_ylabel("Score")
ax.set_ylim(0,1.1)
ax.legend(loc='best')
plt.show() #调用test_learning_curve()
test_learning_curve()
吴裕雄 python 机器学习——模型选择学习曲线learning_curve模型的更多相关文章
- 吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——混合高斯聚类GMM模型
import numpy as np import matplotlib.pyplot as plt from sklearn import mixture from sklearn.metrics ...
- 吴裕雄 python 机器学习——超大规模数据集降维IncrementalPCA模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——数据预处理正则化Normalizer模型
from sklearn.preprocessing import Normalizer #数据预处理正则化Normalizer模型 def test_Normalizer(): X=[[1,2,3, ...
- 吴裕雄 python 机器学习——数据预处理标准化MaxAbsScaler模型
from sklearn.preprocessing import MaxAbsScaler #数据预处理标准化MaxAbsScaler模型 def test_MaxAbsScaler(): X=[[ ...
- 吴裕雄 python 机器学习——数据预处理标准化StandardScaler模型
from sklearn.preprocessing import StandardScaler #数据预处理标准化StandardScaler模型 def test_StandardScaler() ...
- 吴裕雄 python 机器学习——数据预处理标准化MinMaxScaler模型
from sklearn.preprocessing import MinMaxScaler #数据预处理标准化MinMaxScaler模型 def test_MinMaxScaler(): X=[[ ...
- 吴裕雄 python 机器学习——支持向量机线性分类LinearSVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——数据预处理字典学习模型
from sklearn.decomposition import DictionaryLearning #数据预处理字典学习DictionaryLearning模型 def test_Diction ...
随机推荐
- protel99se无法添加库的解决方法
protel99se是很老也很实用的的一门电类专业需要用到的软件,开发时面向XP,对于win7来说存在一定的不兼容性,导致无法添加新的库,本经验为此介绍解决方法.最全,末尾解决win7 32bit 6 ...
- linux命令 mv
后缀--backup=<备份模式>:若需覆盖文件,则覆盖前先行备份: -b:当文件存在时,覆盖前,为其创建一个备份: -f:若目标文件或目录与现有的文件或目录重复,则直接覆盖现有的文件或目 ...
- java.awt.Font
显示效果 Font mf = new Font(String 字体,int 风格,int 字号);字体:TimesRoman, Courier, Arial等风格:三个常量 lFont.PLAIN, ...
- mysql数据库函数之left()、right()、substring()、substring_index()
在实际的项目开发中有时会有对数据库某字段截取部分的需求,这种场景有时直接通过数据库操作来实现比通过代码实现要更方便快捷些,mysql有很多字符串函数可以用来处理这些需求,如Mysql字符串截取总结:l ...
- eclipse运用经验
1.eclipse粘贴字符串添加转义符 2.eclipse的jdk版本切换 1.Window—Preferences—Java—Compiler—右侧面板设置为1.6 2.Window—Prefere ...
- 变色html css js
<!DOCTYPE html><html> <head> <meta charset="utf-8" /> <title> ...
- input输入框在ios手机上获取焦点后有一个灰色阴影
遇到的场景: 有一个输入框 设置 outline:none 然后我又想给他设置获取焦点的颜色 然后 我给input 设置 border 为 1px t透明的 然后 获取焦点的时候 重新设置border ...
- Uncaught TypeError: Cannot read property 'addEventListener' of null
<script type="text/javascript"> var body1=document.getElementById('#body') </scri ...
- openshift3.10集群部署
简介 openshift是基于k8s的开源容器云. 要求 系统环境:CentOS 7.5 搭建一个master节点,两个node节点 注意: openshift3 依赖docker的版本为1.13.1 ...
- Linux06——安装JDK、Tomcat、Eclipse
一.安装JDK(具体解压命令在Linux02中) ①将JDK解压到opt目录下(opt就是文件夹) ②配置环境变量 vim /etc/profile JAVA_HOME=/opt/jdk1.8.0 ...