吴裕雄 python 机器学习——模型选择参数优化随机搜索寻优RandomizedSearchCV模型
import scipy from sklearn.datasets import load_digits
from sklearn.metrics import classification_report
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV,RandomizedSearchCV #模型选择参数优化随机搜索寻优RandomizedSearchCV模型
def test_RandomizedSearchCV():
'''
测试 RandomizedSearchCV 的用法。使用 LogisticRegression 作为分类器,主要优化 C、multi_class 等参数。其中 C 的分布函数为指数分布
'''
### 加载数据
digits = load_digits()
X_train,X_test,y_train,y_test=train_test_split(digits.data, digits.target,test_size=0.25,random_state=0,stratify=digits.target)
#### 参数优化 ######
tuned_parameters ={ 'C': scipy.stats.expon(scale=100), # 指数分布
'multi_class': ['ovr','multinomial']}
clf=RandomizedSearchCV(LogisticRegression(penalty='l2',solver='lbfgs',tol=1e-6),tuned_parameters,cv=10,scoring="accuracy",n_iter=100)
clf.fit(X_train,y_train)
print("Best parameters set found:",clf.best_params_)
print("Randomized Grid scores:")
# for params, mean_score, scores in clf.fit_params,clf.mean_score,clf.score:
# print("\t%0.3f (+/-%0.03f) for %s" % (mean_score, scores() * 2, params))
# print("\t%0.3f (+/-%0.03f) for %s" % (clf.mean_score,clf.score * 2, clf.fit_params))
print(clf) print("Optimized Score:",clf.score(X_test,y_test))
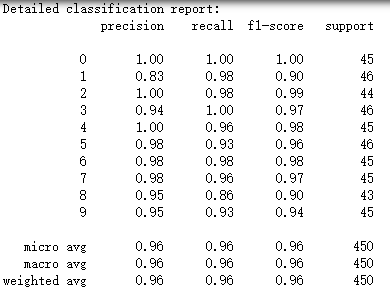
print("Detailed classification report:")
y_true, y_pred = y_test, clf.predict(X_test)
print(classification_report(y_true, y_pred)) #调用RandomizedSearchCV()
test_RandomizedSearchCV()

吴裕雄 python 机器学习——模型选择参数优化随机搜索寻优RandomizedSearchCV模型的更多相关文章
- 吴裕雄 python 机器学习——模型选择参数优化暴力搜索寻优GridSearchCV模型
import scipy from sklearn.datasets import load_digits from sklearn.metrics import classification_rep ...
- 吴裕雄 python 机器学习——模型选择验证曲线validation_curve模型
import numpy as np import matplotlib.pyplot as plt from sklearn.svm import LinearSVC from sklearn.da ...
- 吴裕雄 python 机器学习——模型选择学习曲线learning_curve模型
import numpy as np import matplotlib.pyplot as plt from sklearn.svm import LinearSVC from sklearn.da ...
- 吴裕雄 python 机器学习——模型选择回归问题性能度量
from sklearn.metrics import mean_absolute_error,mean_squared_error #模型选择回归问题性能度量mean_absolute_error模 ...
- 吴裕雄 python 机器学习——模型选择分类问题性能度量
import numpy as np import matplotlib.pyplot as plt from sklearn.svm import SVC from sklearn.datasets ...
- 吴裕雄 python 机器学习——模型选择数据集切分
import numpy as np from sklearn.model_selection import train_test_split,KFold,StratifiedKFold,LeaveO ...
- 吴裕雄 python 机器学习——模型选择损失函数模型
from sklearn.metrics import zero_one_loss,log_loss def test_zero_one_loss(): y_true=[1,1,1,1,1,0,0,0 ...
- 吴裕雄 python 机器学习——分类决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
随机推荐
- 题解【洛谷P1314】[NOIP2011]聪明的质监员
题面 题解 不难发现,\(W\)增大时,\(Y\)值会随之减小. 于是考虑二分\(W\). 如何\(\mathcal{O}(N)check?\) 每一次前缀和记录一下\(1-i\)之间\(w_i \g ...
- 杭电oj————2057(java)
question:A+ B again 思路:额,没啥思路/捂脸,用java的long包里的方法,很简单,只是有几次WA,有几点要注意一下 注意:如果数字有加号要删除掉,这里用到了正则表达式“\\+” ...
- Linux - Shell - diff
概述 linux diff 命令 背景 一个 比较文本差异 的工具 老实说, 之前 git/gitlab 上比较代码差异, 我是有点懵逼的 diff 命令, 可以作为理解这些东西的基础 diff 命令 ...
- 11g RAC添加用户表空间(数据文件)至文件系统(File System)的修正
前提:非TEMP.UNDO和SYSTEM表空间,这仨是大爷,您得搂着点.来自博客园AskScuti .客户是添加临时表空间数据文件时,不小心 ADD 到了文件系统中,然后发现,后悔了,还在OS层面 R ...
- C++-1019-Number Sequence
题意: 求数字112123123412345123456123456712345678123456789123456789101234567891011123456789101112123456789 ...
- 多数据源切换-Druid
版权声明:本文为博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/qq_37279783/article/d ...
- date时间比较
比较前先要对时间判断不能为空 int result = tk.getCloseTime().compareTo(tk.getPlanEndTime()); result = 1: 代表 closeT ...
- 【C语言】定义一个函数,求长方体的体积
#include<stdio.h> int volume(int a, int b,int c)/*定义函数*/ { int p; p = a * b * c; return p; } i ...
- mediasoup-demo安装记录
环境CentOS 7 64位 VMWare12虚拟机(win10主机),安装好NodeJS 10.13(大于8.9就可以) 已按照GitHub说明拉下来代码,配置好Node环境,开始执行npm sta ...
- php商城数据库的设计 之无限分类
商品分类,使用无限分类 即: -------如何创建数据表 pid---父级分类id,如果是顶级分类则为0 path---1,用户分类的排序 . 排序示例: 实现逻辑:获取type表的所有分类,ord ...