【5】KMP学习笔记
前言
WFLS 2023 寒假集训 Day1
KMP好闪,拜谢KMP!
暴力算法
单模字符串匹配算法
设 \(i\) 为主串 \(s\)(文本串)指针,\(j\) 为子串 \(t\)(模式串)指针,最开始 \(i,j\) 都从 \(0\) 开始,如果 \(s[i]==t[j]\) 那么 \(i++\) , \(j++\) 。否则匹配失败(失配),则 \(i=i-j+1\) , \(j=0\) 。
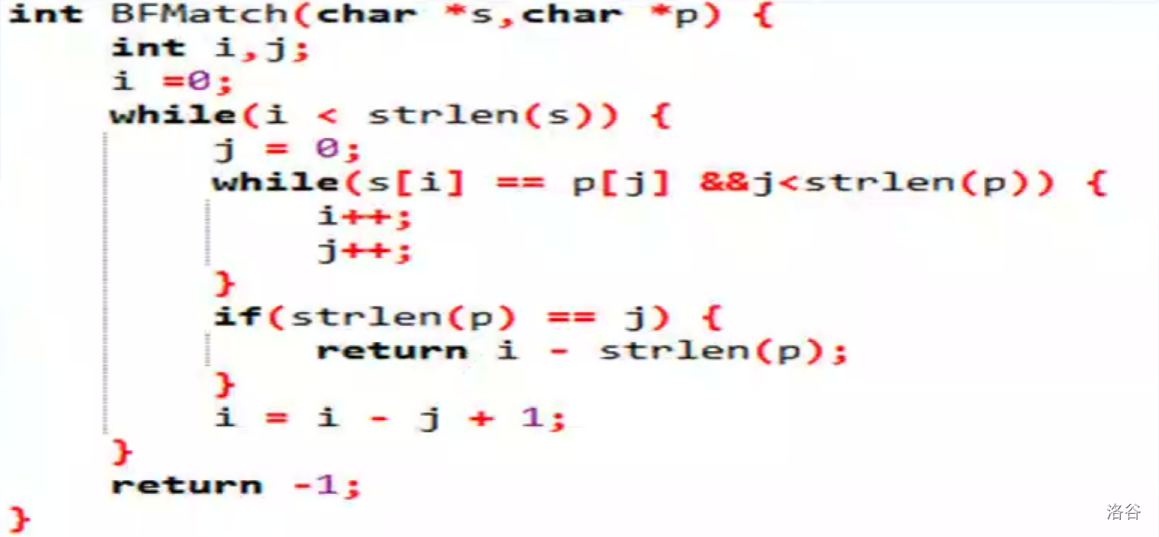
时间复杂度: \(O(mn)\)
KMP
首先我们要思考,暴力算法慢在哪里。
最主要的问题,就是这一句话:
i=i-j+1;
有没有办法可以使主指针 \(i\) 不回溯呢?
next数组
如果匹配到 \(t[j]\) 时失配,那么前 \(j-1\) 项肯定匹配。
这时就要考虑使用模式串自身的性质了。
举个例子:
asbhguwsdwqqddwsdwsdwsr
wsdwsr
^ ^
i j
此时在 \(j\) 处失配了,但是根据观察,我们可以把模式串挪到下面位置,从而减少运算量。
asbhguwsdwqqddwsdwsdwsr
wsdwsr
^
i,j
由于在模式串中的前 \(j-1\) 项已经匹配了,所以我们可以在前 \(j-1\) 项中找到一个前缀,使其与后面第 \(j\) 项之前的某一段相同,然后就可以直接跳到这一段,继续进行匹配。
这是就要引入一个概念了:最大公共前缀
其实就是上面说的 一个前缀 ,在进行KMP算法时,可以把每个 \(j\) 的最大公共前缀存进一个表中,这个表就是next数组。
例如字符串 wsdwsr 的next数组
| w | s | d | w | s | r | |
|---|---|---|---|---|---|---|
| \(next[j]\) | \(-1\) | \(0\) | \(0\) | \(0\) | \(1\) | \(2\) |
求next数组的方法:
设现在算到了第 \(n\) 位
\(1\) :第一位的next值为 \(-1\)
\(2\) :查看第 \(n-1\) 位的next值,记为 \(a\)
\(3\) :判断 \(a\) 是否为 \(-1\) ,如果 \(a\) 为 \(-1\) ,则 \(next[n]=0\)
\(4\) :否则将第 \(n-1\) 个字符与第 \(a\) 个字符进行比较
\(5\) :若相同,则 \(next[n]=a+1\)
\(6\) :若不相同,则令 \(a=next[a]\) ,执行第 \(3\) 步。
计算完毕后,\(next[n]\) 就表示前 \(n-1\) 个字符的最大公共前缀。
模板如下:
int getnext(char t[],int next[])
{
int i=0,j=-1,res=-2;
next[0]=-1;
int l=strlen(t);
while(i<l)
{
if(j==-1||t[i]==t[j])
{
i++;
j++;
next[i]=j;
}
else j=next[j];
}
for(int i=0;i<l;i++)
res=max(res,next[i]);
return res;
}
单模字符串匹配
有了 \(next\) 表,在匹配过程中如果失配,我们可以直接令 \(j=next[j]\) ,查表跳转到最大公共前缀的后一个位置就行了。
模板如下:
int kmp(char s[],char t[],int next[])
{
int i=0,j=0,cnt=0;
int ls=strlen(s),lt=strlen(t);
while(i<ls)
{
if(j==-1||s[i]==t[j])
{
i++;
j++;
}
else j=next[j];
if(j==lt)
{
printf("%d\n",i-lt+1);
j=next[j];
cnt++;
}
}
return cnt;
}
复杂度分析
时间复杂度: \(O(m+n)\) (听说可以被卡回 \(O(mn)\) )
空间复杂度: \(O(m)\)
KMP例题
例题 \(1\) :
KMP板子题,注意匹配成功时的处理,不多赘述。
#include <bits/stdc++.h>
using namespace std;
char s[1000010],t[1000010];
int next1[1000010];
int getnext(char t[],int next[])
{
int i=0,j=-1,res=-2;
next[0]=-1;
int l=strlen(t);
while(i<l)
{
if(j==-1||t[i]==t[j])
{
i++;
j++;
next[i]=j;
}
else j=next[j];
}
for(int i=0;i<l;i++)
res=max(res,next[i]);
return res;
}
int kmp(char s[],char t[],int next[])
{
int i=0,j=0,cnt=0;
int ls=strlen(s),lt=strlen(t);
while(i<ls)
{
if(j==-1||s[i]==t[j])
{
i++;
j++;
}
else j=next[j];
if(j==lt)
{
printf("%d\n",i-lt+1);
j=next[j];
cnt++;
}
}
return cnt;
}
int main()
{
scanf("%s",s);
scanf("%s",t);
int ans=getnext(t,next1);
int cnt=kmp(s,t,next1);
int l=strlen(t);
for(int i=1;i<=l;i++)
printf("%d ",next1[i]);
return 0;
}
例题 \(2\) :
P4391 [BOI2009]Radio Transmission 无线传输
此题最大的难点在于如何求出一个周期。
我们可以求出整个字串的最大公共前缀,然后开始分类讨论:
\(1\) :周期是完整的
最大公共前缀大致是这样:
周期 周期 ... 周期 周期
—————————————————— (前缀)
——————————————————— (与前缀相同的部分)
此时,用字符串总长度减去最大公共前缀的长度就是答案,也就是 \(n-next[n]\) 。
\(2\) :周期不是完整的
最大公共前缀大致是这样:
半周 周期 ... 周期 半周
—————————————————— (前缀)
——————————————————— (与前缀相同的部分)
把中间的一堆完整周期看作一个周期,因为无论有多少个整周期都没有影响,问题就变成了这样:
半周 周期 半周
———————— (前缀)
———————— (与前缀相同的部分)
由最大公共前缀,得到这两段是完全相同的。所以可以把前面的半周对应到底下的前周,就是这样:
半周 前周 后周 半周
————————————— (前缀)
————————————(与前缀相同的部分)
西周 东周 周天子
所以前面的半周与前周完全相同,就可以把前面的半周都消掉,同理也可以消掉后周,就变成了:
半周 周期 ... 周期 半周
—————————————————— (前缀)
——————————————————— (与前缀相同的部分)
结论还是 \(n-next[n]\) 。
#include <bits/stdc++.h>
using namespace std;
char t[1000010];
int next1[1000010];
int getnext(char t[],int next[])
{
int i=0,j=-1,res=-2;
next[0]=-1;
int l=strlen(t);
while(i<l)
{
if(j==-1||t[i]==t[j])
{
i++;
j++;
next[i]=j;
}
else j=next[j];
}
for(int i=0;i<l;i++)
res=max(res,next[i]);
return res;
}
int main()
{
int ans;
scanf("%d%s",&ans,t);
getnext(t,next1);
printf("%d",ans-next1[ans]);
return 0;
}
例题 \(3\) :
借用 KMP 思想优化的动态规划。
首先,用 \(dp[i]\) 表示把前 \(i\) 位的字符完全匹配需要的最少词缀数(下标均从 \(1\) 开始)。那么,我们可以从点 \(i+1\) 开始,向后逐位与字符串 \(T\) 比较。设此时匹配到了 \(T\) 中的第 \(j\) 位,如果相等,则易得转移方程:
\]
如果不相等或到达了字符串 \(T\) 末尾,则证明在此之后不会更长的有魔法词缀,可以结束这一次匹配,令 \(i=i+1\) 计算下一位即可。
很明显,这个算法的时间复杂度是 \(O(|S||T|)\) 的,当数据范围达到 \(|S|,|T|\le10^6\) 时,算法必然超时。
考虑优化这个算法,我们知道,如果不相等或到达了字符串 \(T\) 末尾,失配后是可以直接跳过一部分不可能产生新的解的数据。这样就自然而然地想到了用这个思想把单模字符串匹配优化到 \(O(|S|+|T|)\) 的 KMP 算法。
借助 KMP 的思想,首先求出字符串 \(T\) 的 \(next\) 数组,然后开始按照 KMP 的方式匹配:(设此时文本串匹配到第 \(i\) 项,模式串匹配到第 \(j\) 项)
设置一个名为 \(now\) 的临时变量,用于存储如果匹配的最少词缀数。
可以直接逐位比较。如果相等,则按照 KMP 思想,将模式串和文本串指针一起后移,令 \(dp[i]=now\) 后比较下一位。
如果不相等,可以令 \(j=next[j]\) 之后重新计算 \(now\) 的值。因为一旦匹配失败,只能再次选择一个词缀。每次 KMP 算法在匹配失败后,会利用最长公共前后缀的性质使得文本串指针 \(i\) 不往前跳。而每次利用最长公共前后缀的性质,会改变模式串匹配的起始位置,所以需要重新计算 \(now\) 的值。可以直接用 \(dp[i-j]\) 计算出模式串匹配的起始位置的前一个位置,把 \(now\) 的值更新为 \(dp[i-j]+1\) 以保证正确性。模式串匹配到末尾也是同理。
DP 边界:\(dp[0]=1\)。
DP 目标:\(dp[|S|]\)。
时间复杂度:\(O(|S|+|T|)\)。
注意,由于有无解的情况,所以当 \(next\) 数组跳到 \(-1\) 时,应该直接判定无解并输出 Fake。因为如果 \(next\) 数组跳到 \(-1\) 证明匹配第一个字符就失配了,此时后面没有办法再进行匹配,无解。
完整代码:(由于代码中的字符串下标是从 \(0\) 开始的,所以可能会和上文的讲解有些出入)
#include <bits/stdc++.h>
using namespace std;
int lt,ls,next1[10000010],f[10000010];
char t[10000010],s[10000010];
void get_next(char t[],int next[])
{
int i=0,j=-1;
next[0]=-1;
while(i<lt)
{
if(j==-1||t[i]==t[j])i++,j++,next[i]=j;
else j=next[j];
}
}
bool kmp(char s[],char t[],int next[])
{
int i=0,j=0,now=1;
f[0]=1;
while(i<ls)
{
if(j==-1)return 0;
if(s[i]==t[j])i++,j++,f[i]=now;
else j=next[j],now=f[i-j]+1;
if(j==lt)now=f[i-j]+1,j=next[j];
}
return 1;
}
int main()
{
scanf("%d%d%s%s",<,&ls,t,s);
get_next(t,next1);
if(!kmp(s,t,next1))printf("Fake");
else printf("%d",f[ls]);
return 0;
}
后记
为什么只有两道例题?因为别的我不会
UPD on 2024/6/23 现在有三道例题了。
集训真的好累好累啊,眼睛受不了的!
不过能提升我的OI水平,想想也没什么的。
【5】KMP学习笔记的更多相关文章
- KMP学习笔记
功能 字符串T,长度为n. 模板串P,长度为m.在字符串T中找到匹配点i,使得从i开始T[i]=P[0], T[i+1]=P[1], . . . , T[i+m-1]=P[m-1] KMP算法先用O( ...
- 扩展kmp学习笔记
kmp没写过,扩展kmp没学过可还行. 两个愿望,一次满足 (该博客仅用于防止自己忘记,不保证初学者能看懂我在瞎bb什么qwq) 用途 对于串\(s1,s2\),可以求出\(s2\)与\(s1\)的每 ...
- 扩展kmp 学习笔记
学习了一下这个较为冷门的知识,由于从日报开始看起,还是比较绕的-- 首先定义 \(Z\) 函数表示后缀 \(i\) 与整个串的 \(lcp\) 长度 一个比较好的理解于实现方式是类似于 \(manac ...
- 串的应用与kmp算法讲解--学习笔记
串的应用与kmp算法讲解 1. 写作目的 平时学习总结的学习笔记,方便自己理解加深印象.同时希望可以帮到正在学习这方面知识的同学,可以相互学习.新手上路请多关照,如果问题还请不吝赐教. 2. 串的逻辑 ...
- 「学习笔记」字符串基础:Hash,KMP与Trie
「学习笔记」字符串基础:Hash,KMP与Trie 点击查看目录 目录 「学习笔记」字符串基础:Hash,KMP与Trie Hash 算法 代码 KMP 算法 前置知识:\(\text{Border} ...
- 牛客网《BAT面试算法精品课》学习笔记
目录 牛客网<BAT面试算法精品课>学习笔记 牛客网<BAT面试算法精品课>笔记一:排序 牛客网<BAT面试算法精品课>笔记二:字符串 牛客网<BAT面试算法 ...
- AC自动机板子题/AC自动机学习笔记!
想知道484每个萌新oier在最初知道AC自动机的时候都会理解为自动AC稽什么的,,,反正我记得我当初刚知道这个东西的时候,我以为是什么神仙东西,,,(好趴虽然确实是个对菜菜灵巧比较难理解的神仙知识点 ...
- OI知识点|NOIP考点|省选考点|教程与学习笔记合集
点亮技能树行动-- 本篇blog按照分类将网上写的OI知识点归纳了一下,然后会附上蒟蒻我的学习笔记或者是我认为写的不错的专题博客qwqwqwq(好吧,其实已经咕咕咕了...) 基础算法 贪心 枚举 分 ...
- Hash学习笔记
啊啊啊啊,这篇博客估计是我最早的边写边学的博客了,先忌一忌. 本文章借鉴与一本通提高篇,但因为是个人的学习笔记,因此写上原创. 目录 谁TM边写边学还写这玩意? 后面又加了 Hash Hash表 更多 ...
- 【学习笔记】字符串—马拉车(Manacher)
[学习笔记]字符串-马拉车(Manacher) 一:[前言] 马拉车用于求解连续回文子串问题,效率极高. 其核心思想与 \(kmp\) 类似:继承. --引自 \(yyx\) 学姐 二:[算法原理] ...
随机推荐
- 探秘Transformer系列之(31)--- Medusa
探秘Transformer系列之(31)--- Medusa 目录 探秘Transformer系列之(31)--- Medusa 0x00 概述 0x01 原理 1.1 动机 1.2 借鉴 1.3 思 ...
- c++并发编程实战-第1章 c++并发世界
前言 c++11开始支持多线程,使得编写c++多线程程序无需依赖特定的平台,使开发者能够编写可移植的.行为确定的多线程程序代码. 什么是并发 所谓并发,是两个或多个同时独立进行的活动.而计算机中的并发 ...
- VS2019 配置libzmq-4.3.1
1.下载libzmq-4.3.1 https://github.com/zeromq/libzmq/tags 2.解压并查看 3.编译 使用vs2019对其进行编译,点击libzmq.sln进入工程环 ...
- 鸿蒙仓颉开发语言实战教程:自定义tabbar
大家周末好呀,今天继续分享仓颉语言开发商城应用的实战教程,今天要做的是tabbar. 大家都知道ArkTs有Tabs和TabContent容器,能够实现上图的样式,满足基本的使用需求.而仓颉就不同了, ...
- odoo14的qweb打印单样式丢失问题
问题:在开发odoo14的打印单过程中:Wkhtmltopdf打印插件已安装的情况下,发现样式丢失了,如下图 问题的原因: 1.可能是外网与内网服务转换时候造成的样式丢失,有时候是端口不一致导致的某些 ...
- 做自己的第一个网站(Bootscrapt、odoo14作、JQuery)
今天发布自己的第一个网站,网站内容是关于自己家乡的美景,效果图如下:网站地址是:http://hxmelon.com/ 二.技术篇 1.在这里网站用的是Bootscrapt框架作为网站开发模板.前端语 ...
- MQ面试题|Kafka如何实现每秒上百万的高并发写入【转】
首先,恭喜晚舟归航! 开篇 使用MQ(消息队列)来设计系统带来的好处:业务解耦.流量削峰.灵活扩展.Kafka是高吞吐低延迟的高并发.高性能的消息中间件,在大数据领域有极为广泛的运用.配置良好 ...
- 远程登录Mysql,命令行登录Mysql的方法
1.本地登录MySQL命令:mysql -u root -p //root是用户名,输入这条命令按回车键后系统会提示你输入密码2.指定端口号登录MySQL数据库将以上命令:mysql -u roo ...
- 红色教育软件需求分析 NABCD
N(need) 红色教育指在以红色作为时代精神内涵的象征.务实的落点在于教育.要呼唤有志青年忧国忧民.挑战自我.超越自我.挑战极限.奉献社会的崇高精神.而我们大学生作为实现中华民族伟大复兴的有生力量, ...
- 【译】Cloud Academy(云学院):解锁您的 Azure 技能,加速职业发展
当我们在2025年3月为 Visual Studio 专业版和企业版用户推出云学院福利时,我们的目标很简单:为您提供所需的实践操作学习体验,让您能够自信地掌握 Azure 和云技术,且除了订阅费用外无 ...