Python网络爬虫——京东商城商品列表
Python_网络爬虫——京东商城商品列表
最近在拓展自己知识面,想学习一下其他的编程语言,处于多方的考虑最终选择了
Python,Python从发布之初就以庞大的用户集群占据了编程的一席之地,python用最少的语言完成最多的工作量,丰富的代码库供学习使用。现行的python涉及了:大数据、机器学习、web开发、人工智能等众多方面
什么是网络爬虫
网络爬虫是一个从web资源获取所需要数据的过程,即直接从web资源获取所需的信息,而不是使用网站提供的线程的API访问接口。
网络爬虫也称为网页数据资源获取,是一种数据获取技术,通过该技术我们可以直接从网站的HTML获取所需的数据其中包含与web资源进行通讯、剖解文件获取所需数据整理成信息,及转换成所需的数据格式。
简单一点:就是通过网站的web界面获取我们想要的数据,并以一定的格式存储。每一次获取就是请求一次网页资源的过程,根据返回网页的信息,通过解析工具找到我们想要的数据信息,并加以保存便于后续使用。
网络爬虫一般分为下面几步:
- 确定访问站点地址
- 分析HTML找到目标标签
- 发送请求获取资源
- 使用工具剖析HTML页面
- 获取所需资源
- 保存获取资源
网络爬虫可以用来做什么
网络爬虫用的方面很多,比如做大数据分析网络数据源的获取,收集一些文章,为了满足内心猎奇现在一些美女写真等。
网络爬虫有一定的版权纠纷问题,所以开发者要有一定的判断意识把握住心中的底线,如果出现越界行为只有法律来规定你的底线了。
网络爬虫实战案例——获取京东商城列表
- 确定请求网址
本次实战案例为京东商城查询列表
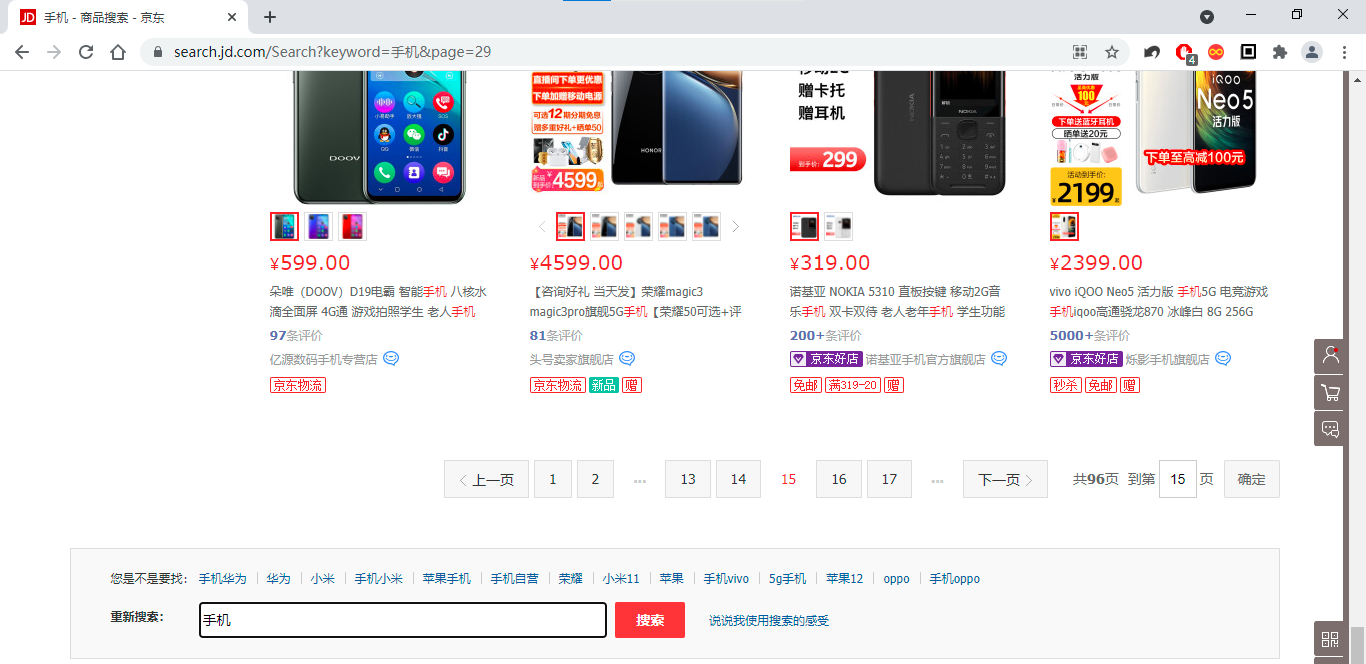
分析网站地址 url:https://search.jd.com/Search?keyword=手机&page=1
可以从网站地址中分析要传入的参数:
keyword:搜索关键字
page:页码
每页的产品数:30
这里在京东商城页码上有一个迷惑行为:在浏览器上切换页码是page的数为page*2-1的数字,实则每页显示用户浏览到底部时又加载了一页,故在浏览器上网页资源上显得有 60 条商品,每页的实际大小为30
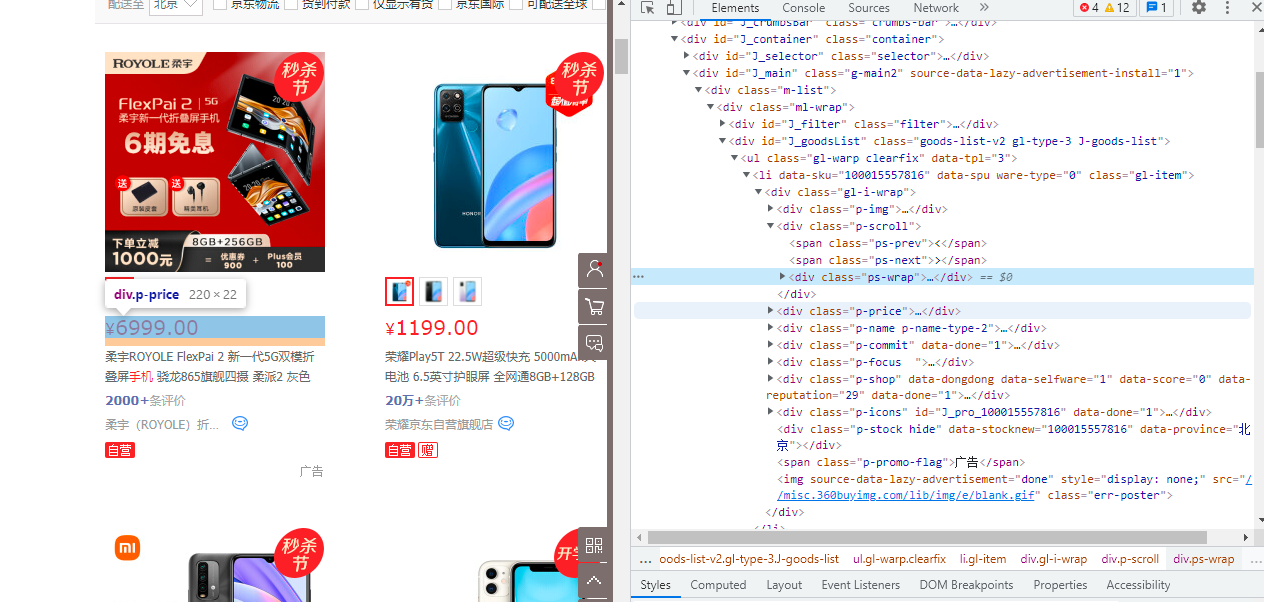
- 分析网站HTML找到目标标签
利用谷歌浏览器的F12或鼠标右键检查标签,找到之际想要的标签
程序需要引入的包
import requests as rq
from bs4 import BeautifulSoup as bfs
import json
import time
- 发送请求获取资源
根据参数编写生成产品列表方法
def get_urls(num):
URL = "https://search.jd.com/Search"
Param="?keyword=手机&page={}"
return [URL+Param.format(index) for index in range(1,num+1)]
发送请求,为请求方法添加请求头
#访问网址
def get_requests(url):
header={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"
}
return rq.get(url,headers=header)
- 使用工具剖析HTML页面
将请求信息转义需要格式
def get_soup(r):
if r.status_code ==rq.codes.ok:
soup=bfs(r.text,"lxml")
else:
print("网络请求失败...")
soup=None
return soup
- 获取所需资源
该页面中查找需要信息,商品列表中的名称、价格、店铺名称、店铺链接、评论数
#获取商品信息
def get_goods(soup):
goods=[]
if soup !=None:
tab_div=soup.find('div',id="J_goodsList")
tab_goods=tab_div.find_all('div',class_="gl-i-wrap")
for good in tab_goods:
name=good.find('div',class_="p-name").text
price=good.find('div',class_="p-price").text
comment=good.find('div',class_="p-commit").find('strong').select_one("a").text
shop=good.find('div',class_="p-shop").find('span').find('a').text
shop_url=good.find('div',class_="p-shop").find('span').find('a')['href']
goods.append({"name":name,"price":price,"comment":comment,"shop":shop,"shop_url":shop_url})
return goods
- 保存获取资源
保存文件格式为json格式,这里可以替换成保存其他格式,或保存到业务库中
def save_to_json(goods,file):
with open(file,"w",encoding="utf-8") as fp:
json.dump(goods,fp,indent=2,sort_keys=True,ensure_ascii=False)
程序主方法,将上面各功能组合在一起。实现解析全站
if __name__=="__main__":
goods=[]
a=0
for url in get_urls(30):
a+=1
print("当前访问页码{},网址为:{}".format(a,url))
response=get_requests(url)
soup=get_soup(response)
page_goods= get_goods(soup)
goods+=page_goods
print("等待10秒进入下一页...")
time.sleep(10)
for good in goods:
print(good)
save_to_json(goods,"jd_phone2.json")
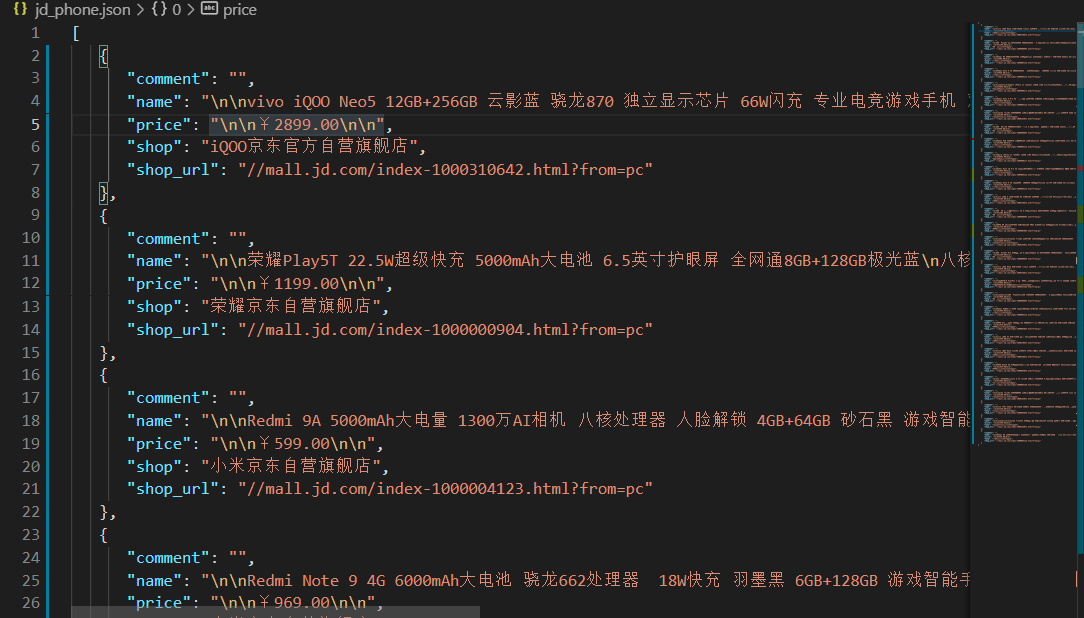
运行程序,查看保存文件是否符合格式
Python网络爬虫——京东商城商品列表的更多相关文章
- Python网络爬虫笔记(五):下载、分析京东P20销售数据
(一) 分析网页 下载下面这个链接的销售数据 https://item.jd.com/6733026.html#comment 1. 翻页的时候,谷歌F12的Network页签可以看到下面 ...
- Python之爬虫-京东商品
Python之爬虫-京东商品 #!/usr/bin/env python # coding: utf-8 from selenium import webdriver from selenium.we ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- 《精通python网络爬虫》笔记
<精通python网络爬虫>韦玮 著 目录结构 第一章 什么是网络爬虫 第二章 爬虫技能概览 第三章 爬虫实现原理与实现技术 第四章 Urllib库与URLError异常处理 第五章 正则 ...
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- 第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 4.提供图片或网站显示的学习进 ...
- 假期学习【六】Python网络爬虫2020.2.4
今天通过Python网络爬虫视频复习了一下以前初学的网络爬虫,了解了网络爬虫的相关规范. 案例:京东的Robots协议 https://www.jd.com/robots.txt 说明可以爬虫的范围 ...
- 从零开始学Python网络爬虫PDF高清完整版免费下载|百度网盘
百度网盘:从零开始学Python网络爬虫PDF高清完整版免费下载 提取码:wy36 目录 前言第1章 Python零基础语法入门 11.1 Python与PyCharm安装 11.1.1 Python ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
随机推荐
- 关于clear:both;后有固定高度的原因及解决方法
不知道从什么时候开始,拥有clear:both;元素的父元素偶尔会出现固定的高度,之前给父元素加diaolay:hidden;临时处理,一直没搞清楚原因,今天又出现该问题,花费半天时间找出了原因记录一 ...
- Hadoop 3.1.1 - Yarn - 使用 FPGA
在 Yarn 上使用 FPGA 前提 YARN 目前只支持通过 IntelFpgaOpenclPlugin 发布的 FPGA 资源 YARN NodeManager 所在的机器上必须预先安装供应商的驱 ...
- QML用同一模版多开主窗口
如何动态地创建多个长的一样的主窗口哪(数据当然不一样), 用QML也是可以实现的. 简单的地说, 就是调用多次load即可. QCoreApplication::setAttribute(Qt::AA ...
- 手写Pascal解释器(二)
目录 一.part4 补充理论知识 二.part5 设计生成式 三.part6 一.part4 承接上次的内容,我们继续编写part4,这个部分我们的任务是完成输入一个仅带乘除运算符的表达式,然后返回 ...
- 剑指 Offer 40. 最小的k个数
剑指 Offer 40. 最小的k个数 输入整数数组 arr ,找出其中最小的 k 个数.例如,输入4.5.1.6.2.7.3.8这8个数字,则最小的4个数字是1.2.3.4. 示例 1: 输入:ar ...
- azure获取vm运行状态
az vm list -d -o json --query "[?name=='vm-name']" | jq '.[0].powerState' 输出vm信息 az vm lis ...
- Vulhub-Mysql 身份认证绕过漏洞(CVE-2012-2122)
前言 当连接MariaDB/MySQL时,输入的密码会与期望的正确密码比较,由于不正确的处理,会导致即便是memcmp()返回一个非零值,也会使MySQL认为两个密码是相同的.也就是说只要知道用户名, ...
- Bugku-web-字符?正则?
题目意思很明显,根据给出的规则构造出合理的正则表达式然后通过get方式提交弹出Flag. i:字体大小 /..../表示开始和结束. .号表示匹配0-9任一数字 *号表示重复前一个字符多次 {4,7} ...
- 1549页Android最新面试题含答案
在今年年初的疫情中,成了失业人员之一,于是各种准备面试,发现面试题网上很多,但是都是很凌乱的,而且一个地方一点,没有一个系统的面试题库,有题库有的没有答案或者是答案很简洁,没有达到面试的要求.所以一直 ...
- Cookie和Session得使用理解
Cookie 饼干 什么是Cokkie? 1.Cookie 翻译过来是饼干的意思. 2.Cookie 是服务器通知客户端保存键值对的一种技术. 3.客户端有了 Cookie 后,每次请求都发送给服务器 ...