ML(5)——神经网络3(随机初始化与梯度检验)
随机初始化
在线性回归和逻辑回归中,使用梯度下降法之前,将θ设置为0向量,有时会习惯性的将神经网络中的权重全部初始化为0,然而这在神经网络中并不适用。
以简单的三层神经网络为例,将全部权重都设置为0,如下图所示:
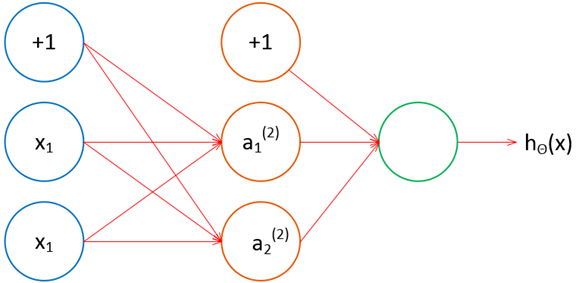
假设仅有一个训练数据,使用梯度下降,在第一次迭代时:
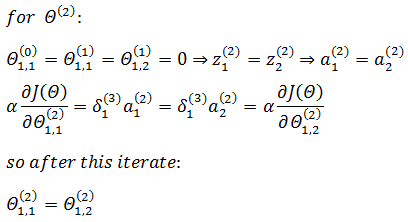

可以看到,第一次迭代的结果是:隐藏层的权重和激活值全部相等,输入层的权重相当于所有输入项放缩了相同的倍数。
在第二次迭代时:
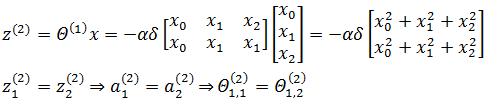
此时,隐藏层的激活值又一次全部相等。继续迭代也会得到相同的结果,即a(2)的所有激活值和权重都一样,这显然不是我们期待的结果。
为了应对上述问题,我们使用一种被称为“随机初始化”的方法去初始化神经网络的权值,具体来说,就是将所有权值在一个范围内赋予随机值,通常这个范围取[-1, 1]。下面是代码示例:
Octave:
init_epsilon = 1;
Theta1 = rand(10, 15) * (init_epsilon * 2) - init_epsilon;
Theta2 = rand(1, 10) * (init_epsilon * 2) - init_epsilon;
Python:
import numpy as np init_epsilon = 1
theta1 = np.random.random((15,10)) * (init_epsilon * 2) - init_epsilon
theta2 = np.random.random((10,1)) * (init_epsilon * 2) - init_epsilon
梯度检验
反向传播算法很高效,但对梯度的求解异常繁琐,实际上,即使某处代码计算出错误的梯度,仍然会得到一个模型,尽管这个模型的J(Θ)很小,但对新数据的拟合非常差,此时不得不重新审视所有代码。
是否可以从一开始就知道梯度是否正确呢?答案是肯定的,这就是梯度检验法。
梯度检验法是通过一种简单的方法取得近似的梯度,将这个近似的梯度与真正的梯度对比,如果很接近,则认为梯度正确,否则认为梯度有误。
将J(θ)和θ放入直角坐标系,下图所示是θ取定值时J(θ)的导数:
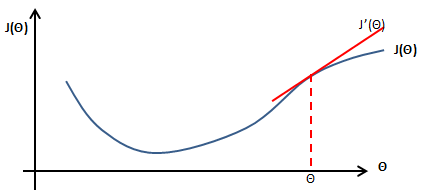
ε 是一个很小的值:

如上图所示:
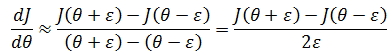
当ε→0时,这趋近于导数的定义:
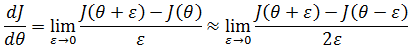
我们也不希望ε太小,通常取ε = 10-4较为合适。
假设J(θ) = θ3,θ = 1,ε = 0.01,则:

如果J(θ) = J(θ1, θ2, …, θn),则θj 的偏导:
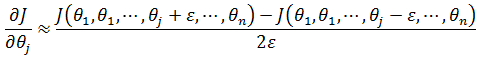
需要注意的是,梯度检验是数值计算,其代价远远高出能够使用向量矩阵计算的反向传播,所以一旦确认算法无误,就应当关闭梯度检验。
数据拟合
隐藏层节点越多,层数越多,神经网络的规模越大。在数据拟合上,神经网络的规模越大,拟合效果越好。

上图的三个神经网络解决的是同样的二分类问题,后两个的规模要大于第一个。需要注意的是,随着神经网络规模的增大,计算量也大大提高,同时更容易出现过拟合。在出现过拟合问题时,可以尝试调整正则化系数。关于正则化,可参考《ML(附录3)——过拟合与欠拟合》
作者:我是8位的
出处:http://www.cnblogs.com/bigmonkey
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注公众号“我是8位的”

ML(5)——神经网络3(随机初始化与梯度检验)的更多相关文章
- ubuntu之路——day7.4 梯度爆炸和梯度消失、初始化权重、梯度的数值逼近和梯度检验
梯度爆炸和梯度消失: W[i] > 1:梯度爆炸(呈指数级增长) W[i] < 1:梯度消失(呈指数级衰减) *.注意此时的1指单位矩阵,W也是系数矩阵 初始化权重: np.random. ...
- 机器学习算法的调试---梯度检验(Gradient Checking)
梯度检验是一种对求导结果进行数值检验的方法,该方法可以验证求导代码是否正确. 1. 数学原理 考虑我们想要最小化以 θ 为自变量的目标函数 J(θ)(θ 可以为标量和可以为矢量,在 Numpy 的 ...
- 贝叶斯分类器,随机森林,梯度下载森林,神经网络相关参数的意义和data leakage
构建的每一颗树的数据都是有放回的随机抽取的(也叫bootstrap),n_estimators参数是你想设置多少颗树,还有就是在进行树的结点分裂的时候,是随机选取一个特征子集,然后找到最佳的分裂标准.
- [AI]神经网络章2 神经网络中反向传播与梯度下降的基本概念
反向传播和梯度下降这两个词,第一眼看上去似懂非懂,不明觉厉.这两个概念是整个神经网络中的重要组成部分,是和误差函数/损失函数的概念分不开的. 神经网络训练的最基本的思想就是:先“蒙”一个结果,我们叫预 ...
- 改善深层神经网络_优化算法_mini-batch梯度下降、指数加权平均、动量梯度下降、RMSprop、Adam优化、学习率衰减
1.mini-batch梯度下降 在前面学习向量化时,知道了可以将训练样本横向堆叠,形成一个输入矩阵和对应的输出矩阵: 当数据量不是太大时,这样做当然会充分利用向量化的优点,一次训练中就可以将所有训练 ...
- 神经网络权值初始化方法-Xavier
https://blog.csdn.net/u011534057/article/details/51673458 https://blog.csdn.net/qq_34784753/article/ ...
- Coursera ML笔记 - 神经网络(Representation)
前言 机器学习栏目记录我在学习Machine Learning过程的一些心得笔记,涵盖线性回归.逻辑回归.Softmax回归.神经网络和SVM等等,主要学习资料来自Standford Andrew N ...
- TensorFlow中权重的随机初始化
一开始没看懂stddev是什么参数,找了一下,在tensorflow/python/ops里有random_ops,其中是这么写的: def random_normal(shape, mean=0.0 ...
- OpenCV 2.x/3.x 随机初始化矩阵
简介 在测试算法的时候,或者某些算法需要使用随机数,本文介绍如何使用OpenCV的随机数相关功能. 主要内容: 1. cv::RNG类 -- random number generator 2. cv ...
随机推荐
- UNITY3d在移动设备上的一些优化实战
项目进入了中期之后,就需要对程序在移动设备上的表现做分析评估和针对性的优化了,首先前期做优化,很多瓶颈没表现出来,能做的东西不多,而且很多指标会凭预想,如果太后期做优化又会太晚,到时发现一些问题改起来 ...
- C#中三层架构UI、BLL、DAL、Model实际操作
三层架构分为:表现层(UI).业务逻辑层(BLL).数据访问层(DAL)再加上实体类库(Model) 转载请注明出自朱朱家园https://blog.csdn.net/zhgl7688 1.实体类库( ...
- golang切片类型
切片slice 其本身并不是数组,它指向底层的数组 作为变长数组的替代方案,可以关联底层数组的局部或全部 为引用类型 可以直接创建或从底层数组获取生成 使用len()获取元素个数,cap()获取容量 ...
- kbmMW 5.08.10试用报告
1.不兼容Android 基于5.07的项目,升级到5.08,不能编译android app.已经反应给作者.作者回复将近快发布fixed,修正这个问题及其他发现的问题. 5.08.01解决了andr ...
- Day12作业及默写
1.整理今天的博客,写课上代码,整理流程图. 2.用列表推导式做下列小题 li=['alex','wusir','abds','meet','ab'] a. 过滤掉长度小于3的字符串列表,并将剩下的转 ...
- 2019-03-11-day009-函数定义
什么是函数 函数就是将许多冗余的代码进行整合统一调用的内存地址 函数怎么定义 def make(): print('掏出手机') print('打开微信') print('摇一摇') print('聊 ...
- Java学习笔记29(IO字符流,转换流)
字符流:只能操作文本文件,与字节流的区别是,字节流是按照字节来读取文件,而字符流是按照字符来读取,因此字符流的局限性为文本文件 字符输出流:Write类,使用时通过子类 每一次写入都要刷新 pac ...
- HDU 6049 17多校2 Sdjpx Is Happy(思维题difficult)
Problem Description Sdjpx is a powful man,he controls a big country.There are n soldiers numbered 1~ ...
- 【Python】数据库练习-2
1. 数据库一般作为存储作用,一般不用函数操作 2. 一次插入多条数据
- 第七十五课 图的遍历(DFS)
添加DFS函数: #ifndef GRAPH_H #define GRAPH_H #include "Object.h" #include "SharedPointer. ...