Spark 核心概念RDD
文章正文
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持丰富的转换操作(如map, join, filter, groupBy等),通过这种转换操作,新的RDD则包含了如何从其他RDDs衍生所必需的信息,所以说RDDs之间是有依赖关系的。基于RDDs之间的依赖,RDDs会形成一个有向无环图DAG,该DAG描述了整个流式计算的流程,实际执行的时候,RDD是通过血缘关系(Lineage)一气呵成的,即使出现数据分区丢失,也可以通过血缘关系重建分区,总结起来,基于RDD的流式计算任务可描述为:从稳定的物理存储(如分布式文件系统)中加载记录,记录被传入由一组确定性操作构成的DAG,然后写回稳定存储。另外RDD还可以将数据集缓存到内存中,使得在多个操作之间可以重用数据集,基于这个特点可以很方便地构建迭代型应用(图计算、机器学习等)或者交互式数据分析应用。可以说Spark最初也就是实现RDD的一个分布式系统,后面通过不断发展壮大成为现在较为完善的大数据生态系统,简单来讲,Spark-RDD的关系类似于Hadoop-MapReduce关系。
1、RDD特点
RDD表示只读的分区的数据集,对RDD进行改动,只能通过RDD的转换操作,由一个RDD得到一个新的RDD,新的RDD包含了从其他RDD衍生所必需的信息。RDDs之间存在依赖,RDD的执行是按照血缘关系延时计算的。如果血缘关系较长,可以通过持久化RDD来切断血缘关系。
1.1 分区
如下图所示,RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个compute函数得到每个分区的数据。如果RDD是通过已有的文件系统构建,则compute函数是读取指定文件系统中的数据,如果RDD是通过其他RDD转换而来,则compute函数是执行转换逻辑将其他RDD的数据进行转换。
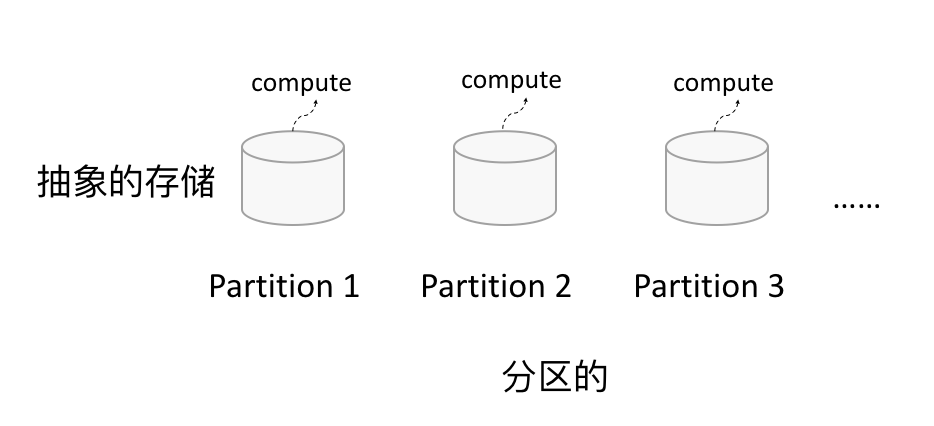 1.2 只读
1.2 只读
如下图所示,RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。
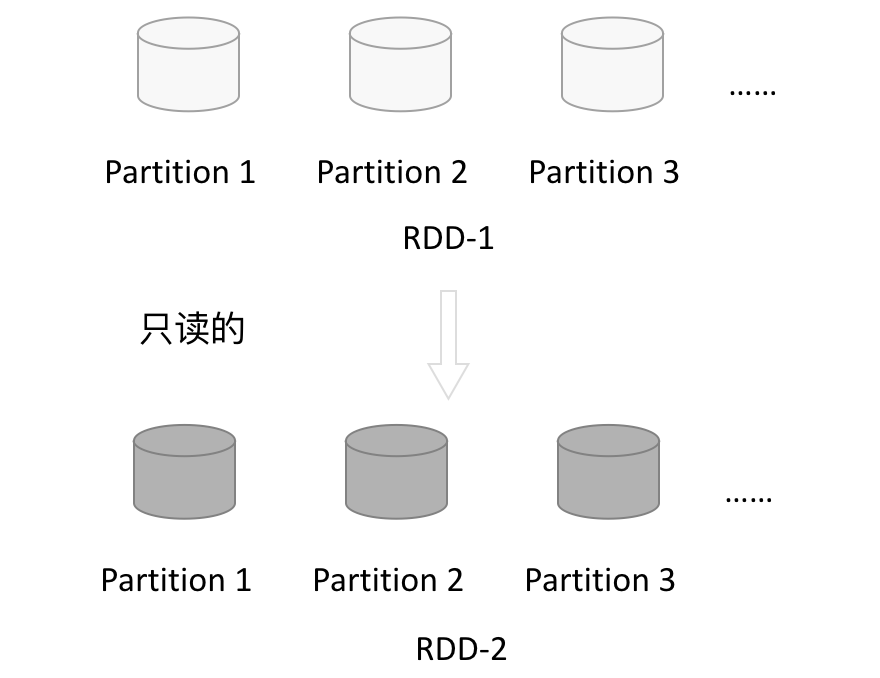
由一个RDD转换到另一个RDD,可以通过丰富的操作算子实现,不再像MapReduce那样只能写map和reduce了,如下图所示。
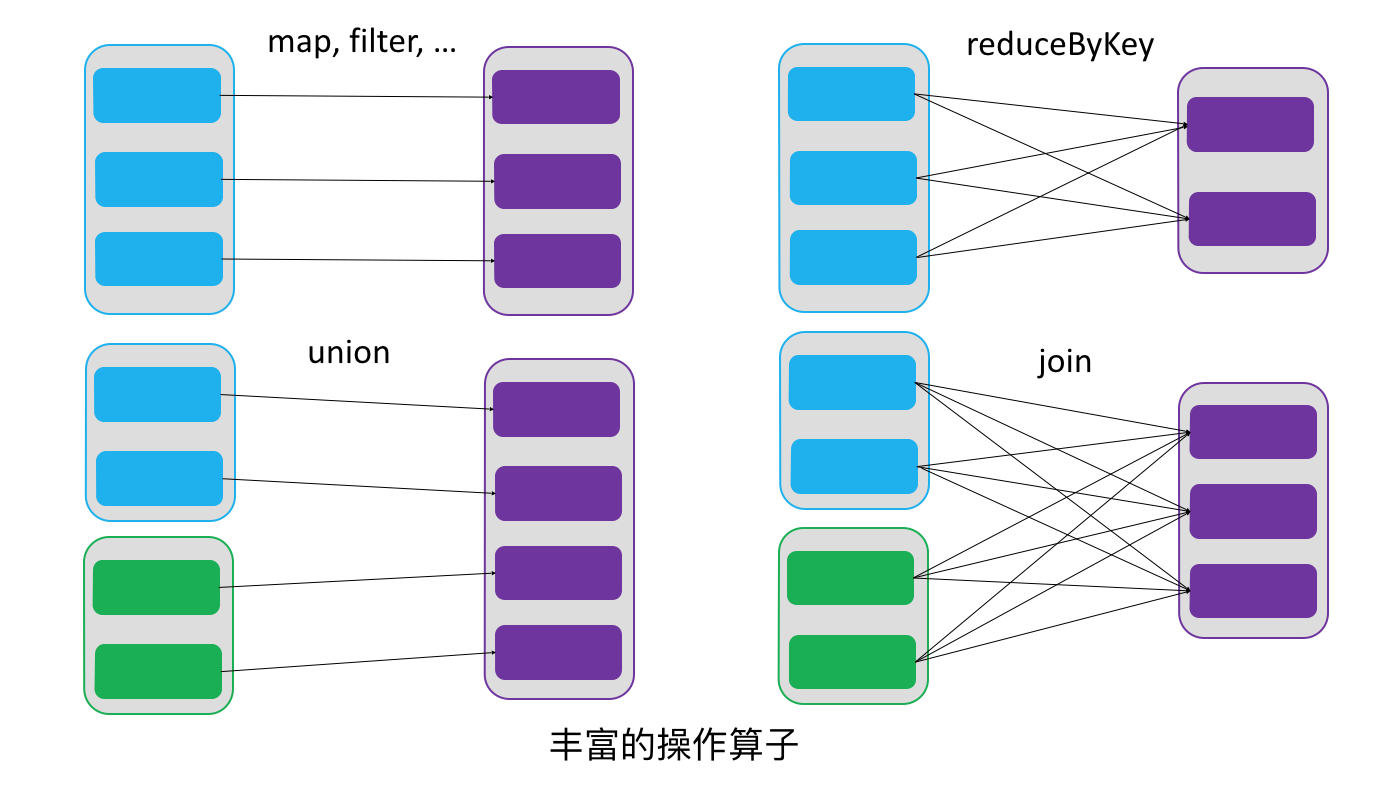
RDD的操作算子包括两类,一类叫做transformations,它是用来将RDD进行转化,构建RDD的血缘关系;另一类叫做actions,它是用来触发RDD的计算,得到RDD的相关计算结果或者将RDD保存的文件系统中。下图是RDD所支持的操作算子列表。
 1.3 依赖
1.3 依赖
RDDs通过操作算子进行转换,转换得到的新RDD包含了从其他RDDs衍生所必需的信息,RDDs之间维护着这种血缘关系,也称之为依赖。如下图所示,依赖包括两种,一种是窄依赖,RDDs之间分区是一一对应的,另一种是宽依赖,下游RDD的每个分区与上游RDD(也称之为父RDD)的每个分区都有关,是多对多的关系。
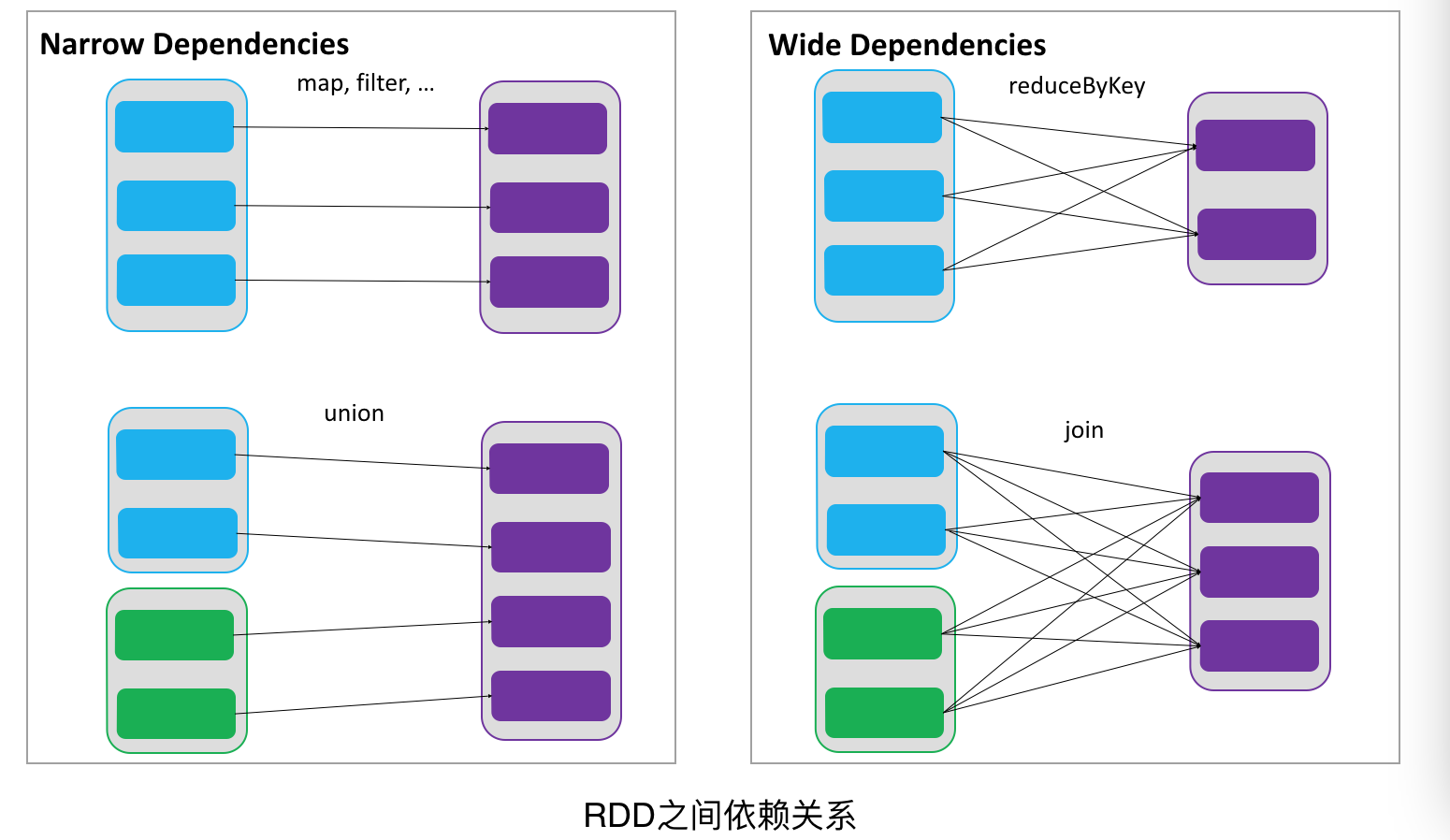
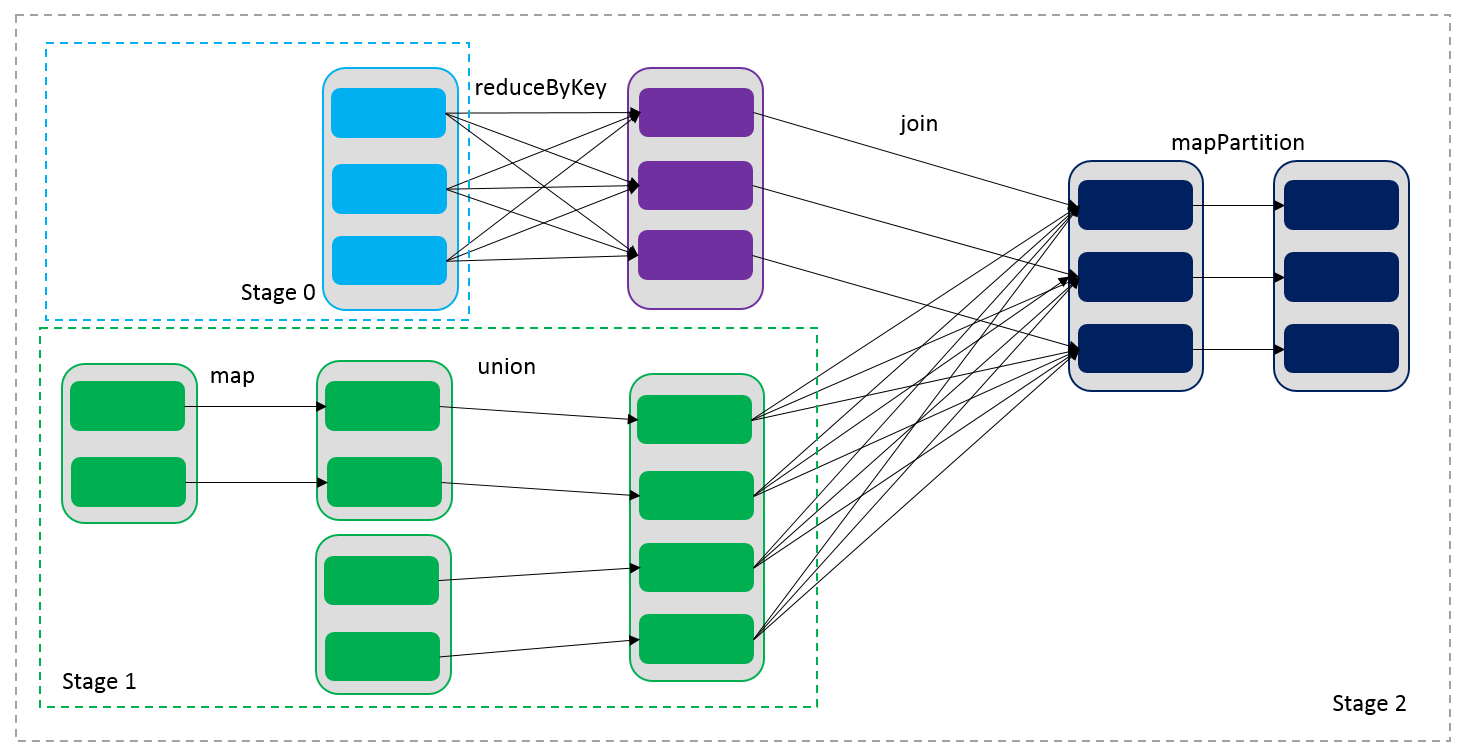
通过RDDs之间的这种依赖关系,一个任务流可以描述为DAG(有向无环图),如下图所示,在实际执行过程中宽依赖对应于Shuffle(图中的reduceByKey和join),窄依赖中的所有转换操作可以通过类似于管道的方式一气呵成执行(图中map和union可以一起执行)。
1.4 缓存
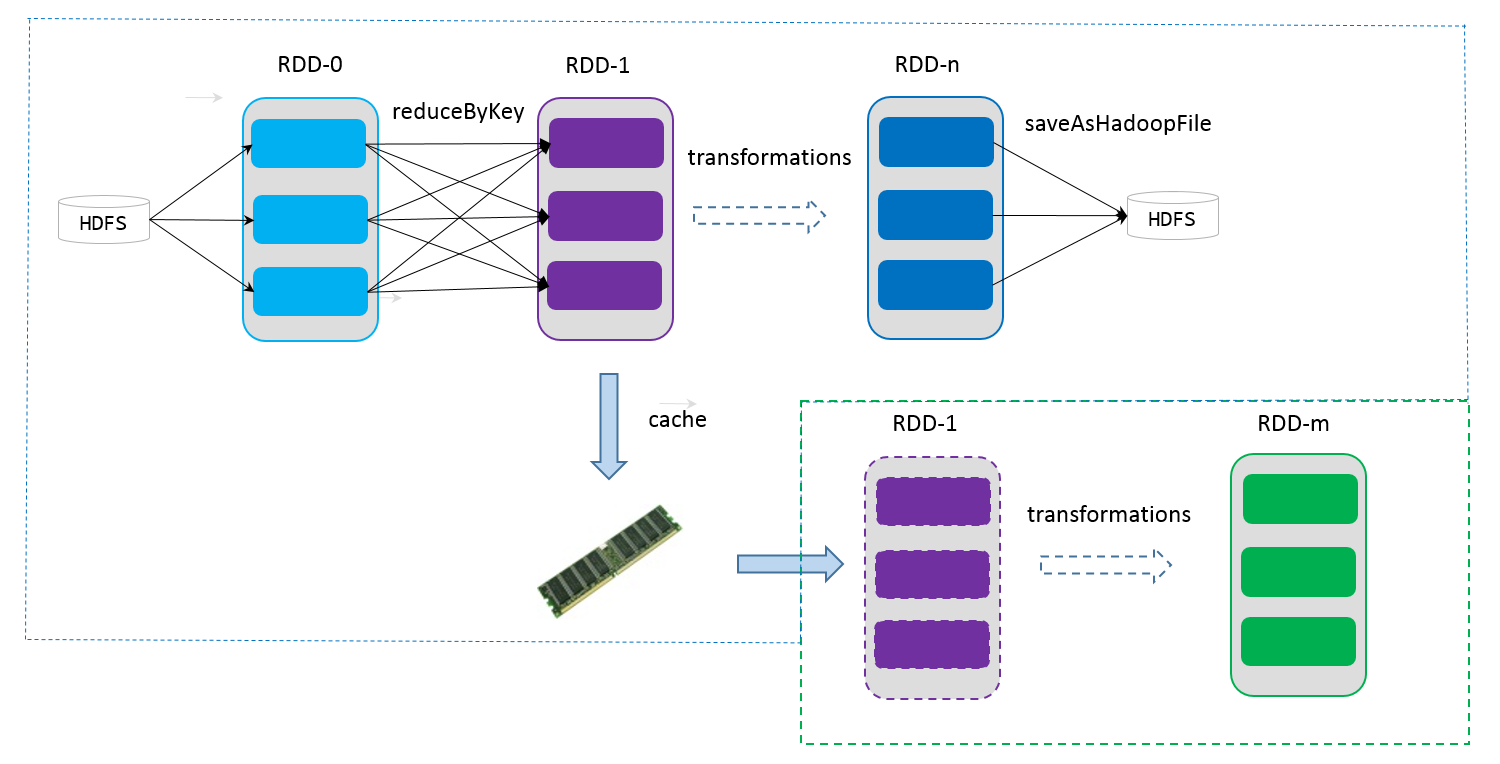
如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该RDD的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。如下图所示,RDD-1经过一系列的转换后得到RDD-n并保存到hdfs,RDD-1在这一过程中会有个中间结果,如果将其缓存到内存,那么在随后的RDD-1转换到RDD-m这一过程中,就不会计算其之前的RDD-0了。
1.5 checkpoint
虽然RDD的血缘关系天然地可以实现容错,当RDD的某个分区数据失败或丢失,可以通过血缘关系重建。但是对于长时间迭代型应用来说,随着迭代的进行,RDDs之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。为此,RDD支持checkpoint将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint后的RDD不需要知道它的父RDDs了,它可以从checkpoint处拿到数据。
1.6 小结
总结起来,给定一个RDD我们至少可以知道如下几点信息:
- 分区数以及分区方式;
- 由父RDDs衍生而来的相关依赖信息;
- 计算每个分区的数据,计算步骤为:
- 如果被缓存,则从缓存中取的分区的数据;
- 如果被checkpoint,则从checkpoint处恢复数据;
- 根据血缘关系计算分区的数据。
2、编程模型
在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换。经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,action可以是向应用程序返回结果(count, collect等),或者是向存储系统保存数据(saveAsTextFile等)。在Spark中,只有遇到action,才会执行RDD的计算(即延迟计算),这样在运行时可以通过管道的方式传输多个转换。
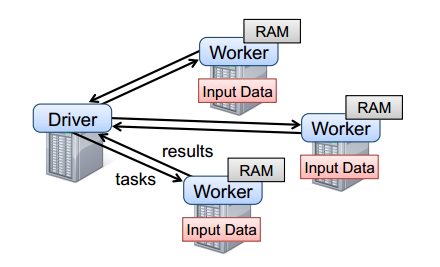
要使用Spark,开发者需要编写一个Driver程序,它被提交到集群以调度运行Worker,如下图所示。Driver中定义了一个或多个RDD,并调用RDD上的action,Worker则执行RDD分区计算任务。
3、应用举例
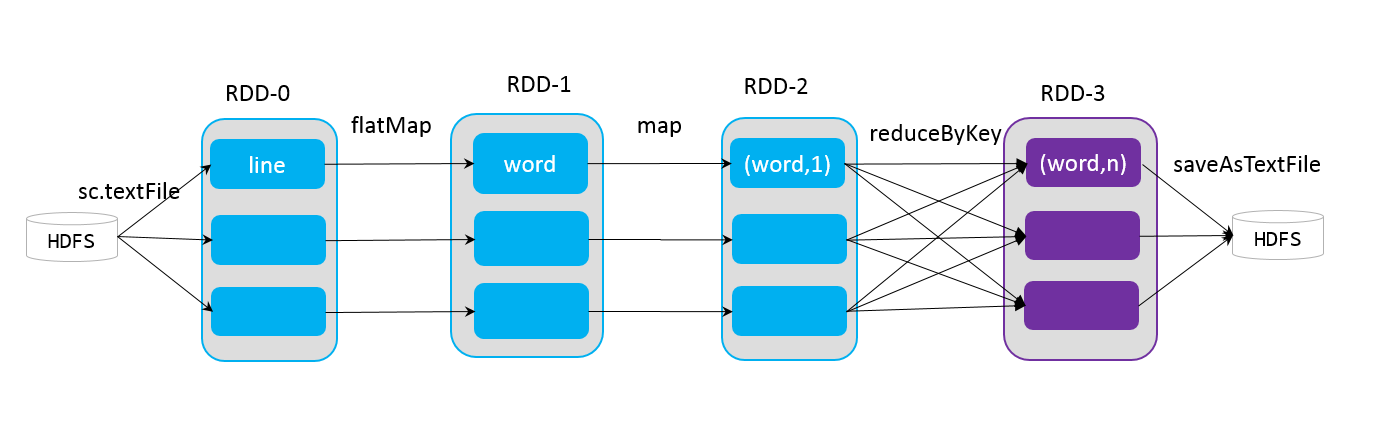
下面介绍一个简单的spark应用程序实例WordCount,统计一个数据集中每个单词出现的次数,首先将从hdfs中加载数据得到原始RDD-0,其中每条记录为数据中的一行句子,经过一个flatMap操作,将一行句子切分为多个独立的词,得到RDD-1,再通过map操作将每个词映射为key-value形式,其中key为词本身,value为初始计数值1,得到RDD-2,将RDD-2中的所有记录归并,统计每个词的计数,得到RDD-3,最后将其保存到hdfs。
import org.apache.spark._
import SparkContext._ object WordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: WordCount <inputfile> <outputfile>");
System.exit(1);
}
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
val result = sc.textFile(args(0))
.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
result.saveAsTextFile(args(1))
}
}
4、小结
基于RDD实现的Spark相比于传统的Hadoop MapReduce有什么优势呢?总结起来应该至少有三点:
- RDD提供了丰富的操作算子,不再是只有map和reduce两个操作了,对于描述应用程序来说更加方便;
- 通过RDDs之间的转换构建DAG,中间结果不用落地;
- RDD支持缓存,可以在内存中快速完成计算。
文章来源
http://sharkdtu.com/posts/spark-rdd.html
Spark 核心概念RDD的更多相关文章
- Spark 核心概念 RDD 详解
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
- 深入理解Spark(一):Spark核心概念RDD
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
- Spark核心概念之RDD
RDD: Resilient Distributed Dataset RDD的特点: 1.A list of partitions 一系列的分片:比如说64M一片:类似于Hadoop中的s ...
- Spark核心概念理解
本文主要内容来自于<Hadoop权威指南>英文版中的Spark章节,能够说是个人的翻译版本号,涵盖了基本的Spark概念.假设想获得更好地阅读体验,能够訪问这里. 安装Spark 首先从s ...
- 七、spark核心数据集RDD
简介 spark RDD操作具体参考官网:http://spark.apache.org/docs/latest/rdd-programming-guide.html#overview RDD全称叫做 ...
- Spark核心概念
1.Application 基于spark的用户程序,包含了一个Driver Program以及集群上中多个executor: spark中只要有一个sparkcontext就是一个a ...
- 大话Spark(1)-Spark概述与核心概念
说到Spark就不得不提MapReduce/Hadoop, 当前越来越多的公司已经把大数据计算引擎从MapReduce升级到了Spark. 至于原因当然是MapReduce的一些局限性了, 我们一起先 ...
- Spark系列-核心概念
Spark系列-初体验(数据准备篇) Spark系列-核心概念 一. Spark核心概念 Master,也就是架构图中的Cluster Manager.Spark的Master和Workder节点分别 ...
- 【Spark深入学习-11】Spark基本概念和运行模式
----本节内容------- 1.大数据基础 1.1大数据平台基本框架 1.2学习大数据的基础 1.3学习Spark的Hadoop基础 2.Hadoop生态基本介绍 2.1Hadoop生态组件介绍 ...
随机推荐
- BZOJ1059 [ZJOI2007]矩阵游戏 二分图匹配 匈牙利算法
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - BZOJ1059 题意概括 有一个n*n(n<=200)的01矩阵,问你是否可以通过交换整行和整列使得左 ...
- 6-7 树的层次遍历 uva122
非常不熟练 照着书大的 晚上尝试一下自己打 了解二叉树 用数组打 第一次: #include<bits/stdc++.h> using namespace std; bool fai ...
- 'utf-8' codec can't decode byte 0xc8 in position 0
今天学习python中使用jieba库,遇到了错误:“UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc8 in position 0: i ...
- ModuleNotFoundError: No module named 'win32api'
原因:缺少了win32解决: pip install pypiwin32
- [OpenCV-Python] OpenCV 中的图像处理 部分 IV (三)
部分 IVOpenCV 中的图像处理 OpenCV-Python 中文教程(搬运)目录 19 Canny 边缘检测 目标 • 了解 Canny 边缘检测的概念 • 学习函数 cv2.Canny() 1 ...
- 兼容ie10以下版本的placeholder属性
<script src="${ctx }/js/jquery.placeholder.js" type="text/javascript">< ...
- codeforces-1102e
https://www.cnblogs.com/31415926535x/p/10439313.html 这道题很锻炼思维,,是到好题,,就是我不在状态,,没看出来线段间的关系,,学会了求一个区间里相 ...
- 【Ray Tracing The Next Week 超详解】 光线追踪2-7 任意长方体 && 场景案例
上一篇比较简单,很久才发是因为做了一些好玩的场景,后来发现这一章是专门写场景例子的,所以就安排到了这一篇 Preface 这一篇要介绍的内容有: 1. 自己做的光照例子 2. Cornell box画 ...
- Javascript日常编码中的一些常见问题
一.尽量少用全局变量 这是一个疑问最少,同时流传最 广的一条.Javascript使用函数管理作用域,全局变量最大的问题在于同名变量冲突.这种隐患产生比较直接的两个原因就是Javascript语言 ...
- 安卓工作室 android studio 汉化后,报错。 设置界面打不开。Can't find resource for bundle java.util.PropertyResourceBundle, key emmet.bem.class.name.element.separator.label
安卓工作室 android studio 汉化后,报错. 设置界面打不开. Android studio has been sinified and reported wrong.The setup ...