爬虫之beautifulsoup篇之一
一个网页的节点太多,一个个的用正则表达式去查找不方便且不灵活。BeautifulSoup将html文档转换成一个属性结构,每个节点都是python对象。这样我们就能针对每个结点进行操作。参考如下代码:
from urllib.request import urlopen
from urllib import error
from bs4 import BeautifulSoup try:
html = urlopen("http://www.pythonscraping.com/pages/page1.html")
bsObj = BeautifulSoup(html.read())
except error.HTTPError as e:
print("HTTPError:.....")
except error.URLError as e:
print("URLError....") else:
print(bsObj.h1)
BeautifulSoup中传入的就是urlopen中反馈的html网页。
运行结果报错:

解决方法:
这个提示的意思是没有给BeautifulSoup中传递一个解析网页的方式。有2中方式可以使用:html.parser以及lxml。这里我们先用html.parser,lxml。
看源码:
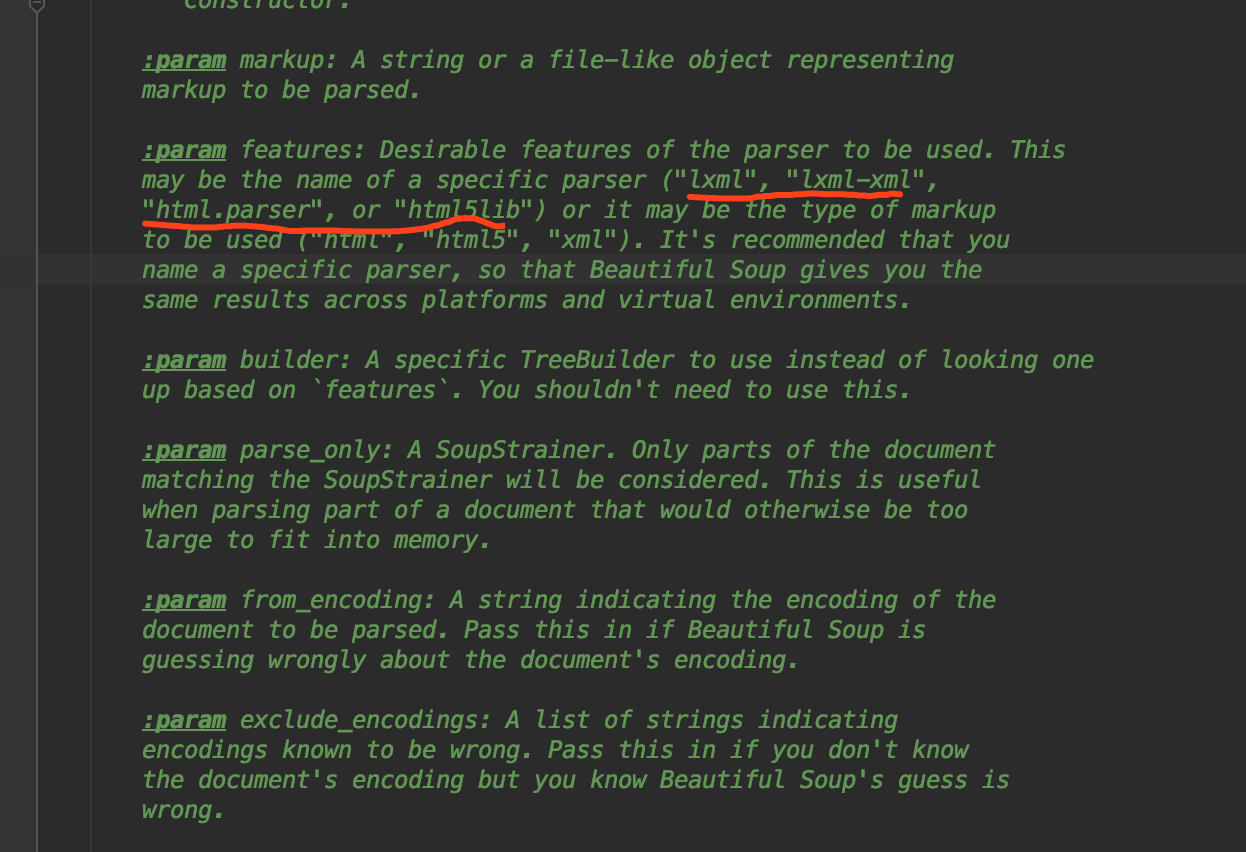
需要传入这四种解析方式。
爬虫之beautifulsoup篇之一的更多相关文章
- 爬虫模块BeautifulSoup
中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html# 1.1 安装BeautifulSoup模块 ...
- 使用Python爬虫库BeautifulSoup遍历文档树并对标签进行操作详解(新手必学)
为大家介绍下Python爬虫库BeautifulSoup遍历文档树并对标签进行操作的详细方法与函数下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最 ...
- Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据
目标:爬取安居客网站上前10页北京二手房的数据,包括二手房源的名称.价格.几室几厅.大小.建造年份.联系人.地址.标签等. 网址为:https://beijing.anjuke.com/sale/ B ...
- Python开发爬虫之理论篇
爬虫简介 爬虫:一段自动抓取互联网信息的程序. 什么意思呢? 互联网是由各种各样的网页组成.每一个网页对应一个URL,而URL的页面上又有很多指向其他页面的URL.这种URL之间相互的指向关系就形成了 ...
- Python 爬虫—— requests BeautifulSoup
本文记录下用来爬虫主要使用的两个库.第一个是requests,用这个库能很方便的下载网页,不用标准库里面各种urllib:第二个BeautifulSoup用来解析网页,不然自己用正则的话很烦. req ...
- python爬虫之BeautifulSoup
爬虫有时候写正则表达式会有假死现象 就是正则表达式一直在进行死循环查找 例如:https://social.msdn.microsoft.com/forums/azure/en-us/3f4390ac ...
- Python爬虫番外篇之Cookie和Session
关于cookie和session估计很多程序员面试的时候都会被问到,这两个概念在写web以及爬虫中都会涉及,并且两者可能很多人直接回答也不好说的特别清楚,所以整理这样一篇文章,也帮助自己加深理解 什么 ...
- Python爬虫番外篇之关于登录
常见的登录方式有以下两种: 查看登录页面,csrf,cookie;授权:cookie 直接发送post请求,获取cookie 上面只是简单的描述,下面是详细的针对两种登录方式的时候爬虫的处理方法 第一 ...
- (python3爬虫实战-第一篇)利用requests+正则抓取猫眼电影热映口碑榜
今天是个值得纪念了日子,我终于在博客园上发表自己的第一篇博文了.作为一名刚刚开始学习python网络爬虫的爱好者,后期本人会定期发布自己学习过程中的经验与心得,希望各位技术大佬批评指正.以下是我自己做 ...
随机推荐
- 【LeetCode】78-子集
题目描述 给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集). 说明:解集不能包含重复的子集. 示例: 输入: nums = [1,2,3] 输出: [ [3], [1], [ ...
- linux下使用yum安装新版php7.0
这两天又装了一下虚拟机,又要编译lnmp,还要弄各种拓展,很麻烦,能不能直接yum安装呢?答案是可以的! 1.首先要更新yum源,不然是默认的老版本,一般都在5.6及以下,但是php7都出来好久了,性 ...
- 搭建Nuget服务器(Nuget私服)
一.前言 对公司或者对个人来说,经过一段时间的沉淀之后,都会有一些框架或者模块,为了对这些框架或者模块进行更好的管理和维护,也为了方便后面的开发或者其他同事,我们可以在我们本地或者内网搭建一个Nuge ...
- 完整剖析SpringAOP的自调用
摘要 spring全家桶帮助java web开发者节省了很多开发量,提升了效率.但是因为屏蔽了很多细节,导致很多开发者只知其然,不知其所以然,本文就是分析下使用spring的一些注解,不能够自调用的问 ...
- Java连载31-递归方法练习、面向对象
一.实现阶乘(一种用递归,一种普通方法) public static void main(String[] args) { System.out.println(factorial(5)); Syst ...
- Python中使用moviepy进行视频分割
场景 moviepy官网: https://pypi.org/project/moviepy/ 是一个用于视频编辑的Python库:切割.连接.标题插入.视频合成.非线性编辑,视频处理和定制效果的创建 ...
- Ganglia环境搭建并监控Hadoop分布式集群
简介 Ganglia可以监控分布式集群中硬件资源的使用情况,例如CPU,内存,网络等资源.通过Ganglia可以监控Hadoop集群在运行过程中对集群资源的调度,作为简单地运维参考. 环境搭建流程 1 ...
- springboot logback日志的使用
以下有两个使用,一个是简单使用,另一个是需要进行详细的配置再使用.首先给出源代码.可以直接使用 import org.slf4j.Logger;import org.slf4j.LoggerFacto ...
- ZK Watcher 的原理和实现
什么是 ZK Watcher 基于 ZK 的应用程序的一个常见需求是需要知道 ZK 集合的状态.为了达到这个目的,一种方法是 ZK 客户端定时轮询 ZK 集合,检查系统状态是否发生了变化.然而,轮询并 ...
- selenium WebDriver 截取网站的验证码
在做爬虫项目的时候,有时候会遇到验证码的问题,由于某些网站的验证码是动态生成的,即使是同一个链接,在不同的时间访问可能产生不同的验证码, 一 刚开始的思路就是打开这个验证码的链接,然后通过java代码 ...