CMU Database Systems - Query Processing
Query Model
Query处理有三种方式,

首先是Iterator model,这是最基本的model,又称为volcano,pipeline模式
他是top-down的模式,通过next函数去逐层获取tuple
好处是比较简单,并且很容易做limit


iterator的例子,
输出一个数据,从top开始调用next,这里第二步需要join,建hashtable,需要把3的数据全部读取上来

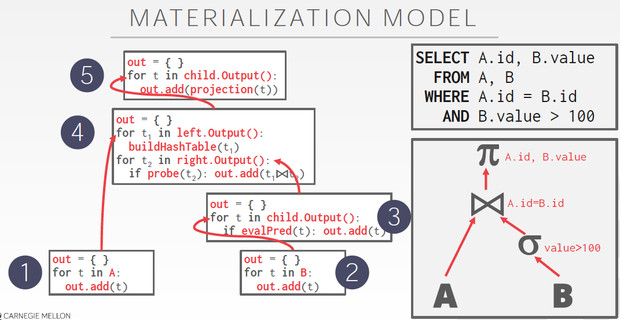
第二种方式,materialization model
反其道,这是一种bottom-up的方式,每个把数据都准备好后,往上传递
这种方式,明显适合TP,对于AP会产生大量的中间结果,
而且不好控制limit,limit1,底下节点可能也要把所有的数据都读出来


Materailization Model的例子,
多了个out,来记录返回的全量结果
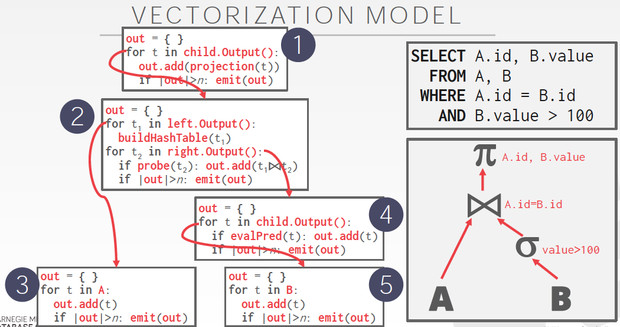
Vectorization Model
向量化模型,iterator的时候每次取一个batch,而不是一个tuple
这样大大降低next的调用频率,而且可以更好的利用SIMD进行并行处理


Vectorization Model的例子,
加上对out大小的判断以形成batch
3种模型的区别如下,

Access Methods
刚刚的查询计划里面,只是说读取数据,但是没有怎么说如何读取数据
Access Methods就是说明如何从数据库中读取数据的
Access Methods也有三种,
Sequentail Scan,Index Scan, Multi-Index/'Bitmap' Scan
Sequential Scan
顺序读,就是一个个page这么读过去,然后用一个内部的cursor去记录读到哪儿了

顺序读会比较慢,但有时是无法避免的
优化的方法如下,
预取,并行化,bypass bufferPool,都是前面说过的优化

Zone Maps
在每个page上加上一些统计信息,又称为pre-computed aggregates
这样我就可以根据这个信息来判断是否需要读这个page

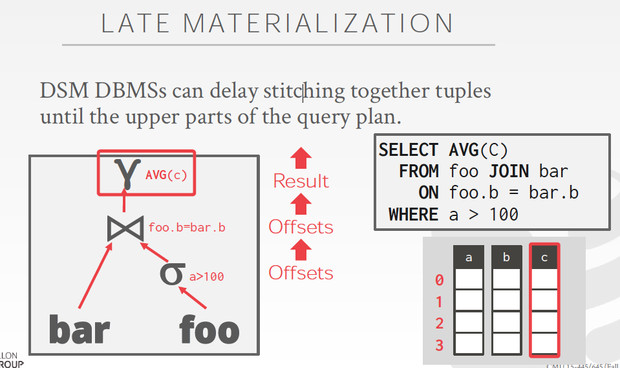
Late Materialization
这个只能用于列存,因为列存才能一次读一列,
所以在前两个过滤条件上,我们只需要把offset传上来,不需要原始数据
到最后一步,才需要把C这一列真正的materialization出来
Heap Clustering
Tuples在pages中是按照clustering index排序的,所以根据clustering index进行query是非常高效的

但是如果要按非clustered index的字段进行排序,就是比较低效的
因为tuples会分布在不同的pages中,你需要混着读
一个优化是,把所有要读的tuples按page id进行排序,然后一个个page顺序读过来会比较高效

Index Scan
关键就是如何pick合适的index来进行查询,这个比较复杂,在后面会详细描述

Multi-index Scan
同时用多个index进行索引,
然后对多个索引的结果集,进行union和intersect,最终得到结果


intersection往往通过bitmaps,hash tables,bloom filters来实现,所以有时也称为Bitmap Scan

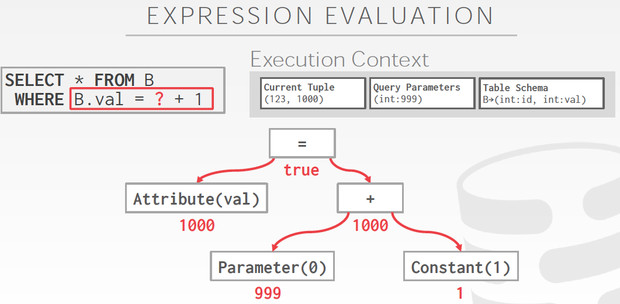
Expression Evaluation
SQL中的表达式,可以通过expression tree来表示,这种方式很灵活,但是性能比较差,所以比较高效的方式是直接codegen

CMU Database Systems - Query Processing的更多相关文章
- CMU Database Systems - Query Optimization
查询优化应该是数据库领域最难的topic 当前查询优化,主要有两种思路, Rules-based,基于先验知识,用if-else把优化逻辑写死 Cost-based,试图去评估各个查询计划的cost, ...
- CMU Database Systems - Database Recovery
数据库数据丢失的典型场景如下, 数据commit后,还没有来得及flush到disk,这时候crash就会丢失数据 当然这只是fail的一种情况,DataBase Recovery要讨论的是,在各种f ...
- CMU Database Systems - Storage and BufferPool
Database Storage 存储分为volatile和non-volatile,越快的越贵越小 那么所以要解决的第一个问题就是,如果尽量在有限的成本下,让读写更快些 意思就是,尽量读写volat ...
- CMU Database Systems - Timestamp Ordering Concurrency Control
2PL是悲观锁,Pessimistic,这章讲乐观锁,Optimistic,单机的,非分布式的 Timestamp Ordering,以时间为序,这个是非常自然的想法,按每个transaction的时 ...
- CMU Database Systems - Concurrency Control Theory
并发控制是数据库理论里面最难的课题之一 并发控制首先了解一下事务,transaction 定义如下, 其实transaction关键是,要满足ACID属性, 左边的正式的定义,由于的intuitive ...
- CMU Database Systems - Parallel Execution
并发执行,主要为了增大吞吐,降低延迟,提高数据库的可用性 先区分一组概念,parallel和distributed的区别 总的来说,parallel是指在物理上很近的节点,比如本机的多个线程或进程,不 ...
- CMU Database Systems - Two-phase Locking
首先锁是用来做互斥的,解决并发执行时的数据不一致问题 如图会导致,不可重复读 如果这里用lock就可以解决,数据库里面有个LockManager来作为master,负责锁的记录和授权 数据库里面的基本 ...
- CMU Database Systems - Distributed OLTP & OLAP
OLTP scale-up和scale-out scale-up会有上限,无法不断up,而且相对而言,up升级会比较麻烦,所以大数据,云计算需要scale-out scale-out,就是分布式数据库 ...
- CMU Database Systems - MVCC
MVCC是一种用空间来换取更高的并发度的技术 对同一个对象不去update,而且记录下每一次的不同版本的值 存在不会消失,新值并不能抹杀原先的存在 所以update操作并不是对世界的真实反映,这是一种 ...
随机推荐
- SpringBoot使用MockMVC单元测试Controller
对模块进行集成测试时,希望能够通过输入URL对Controller进行测试,如果通过启动服务器,建立http client进行测试,这样会使得测试变得很麻烦,比如,启动速度慢,测试验证不方便,依赖网络 ...
- PyQt5入门
PyQt5 是用来创建Python GUI应用程序的工具包.作为一个跨平台的工具包,PyQt可以在所有主流操作系统上运行(Unix,Windows,Mac). 本文描述Windows系统下如何安装Py ...
- Null ModelAndView returned to DispatcherServlet with name 'dispatcherServlet': assuming HandlerAdapter completed request handling
Null ModelAndView returned to DispatcherServlet with name 'dispatcherServlet': assuming HandlerAdapt ...
- java的一些代码阅读笔记
读了一点源码,很浅的那种,有些东西觉得很有趣,记录一下. ArrayList的本质是Object[] public ArrayList(int initialCapacity) { if (initi ...
- 行为型模式(一) 模板方法模式(Template Method)
一.动机(Motivate) "模板方法",就是有一个方法包含了一个模板,这个模板是一个算法.在我们的现实生活中有很多例子可以拿来说明这个模式,就拿吃饺子这个事情来说,要想吃到饺子 ...
- cookie,session,token介绍
本文目录 发展史 Cookie Session Token 回到目录 发展史 1.很久很久以前,Web 基本上就是文档的浏览而已, 既然是浏览,作为服务器, 不需要记录谁在某一段时间里都浏览了什么文档 ...
- [Kubernetes] Kubectl and Pod
1. Create and run a Pod kubectl run my-nginx --image=nginx:alpine We can run kubectl get all to see ...
- 卡林巴琴谱&简谱
---------------------------------------------------------------------------------------------------- ...
- learning java AWT 绝对定位
import javax.swing.*; import java.awt.*; public class NullLayoutTest { Frame f = new Frame("测试窗 ...
- csp-s模拟测试93T2口胡(蒟蒻的口胡大家显然就不用看了吧
我们先证正确性,再证复杂度 以下记$\left \langle i,j \right \rangle$为考虑$\left [ i,j \right ]$的点时的最优决策 $\left \langle ...