第十六节:Scrapy爬虫框架之项目创建spider文件数据爬取
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取所设计的, 也可以应用在获取API所返回的数据或者通用的网络爬虫。
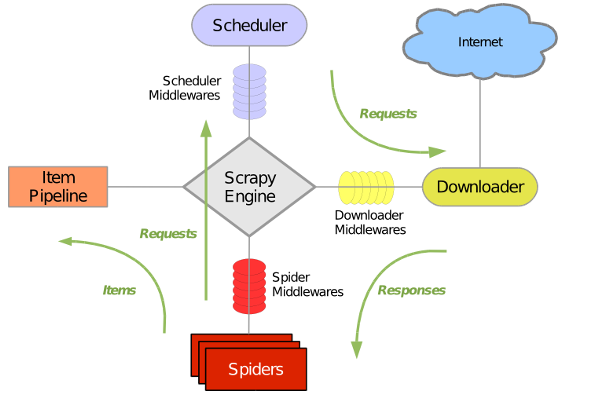
Scrapy原理图如下:
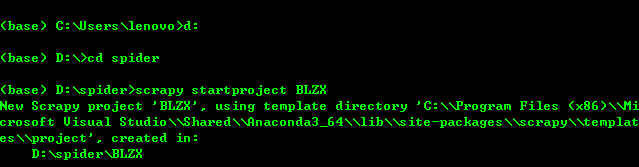
1、创建Scrapy项目:进入你需要创建scrapy项目的文件夹下,输入scrapy startproject BLZX(此处BLZX为爬虫项目名称)
项目创建完成后出现一个scrapy框架自动给你生成的爬虫目录

2、进入创建好的项目当中创建spider爬虫文件blzxSpider:
cd BLZX
scrapy genspider blzxSpider image.so.com (其中image.so.com为爬取数据的链接)
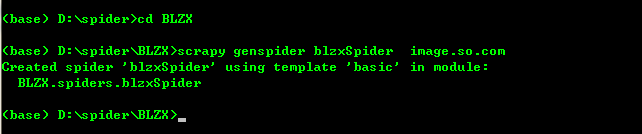
到此我们的scrapy爬虫项目已经创建完成,目录如下:

创建好了blzxSpider爬虫文件后scrapy将会在改文件当中自动生成 如下代码,我们就可以在这个文件当中进行编写代码爬取数据了。
# -*- coding: utf-8 -*-
import scrapy class BlzxspiderSpider(scrapy.Spider):
name = 'blzxSpider'
allowed_domains = ['image.so.com']
start_urls = ['http://image.so.com/'] def parse(self, response):
pass
3、爬取360图片玩转的图片,此时我们需要编写blzxSpiser文件进行爬取360图片
代码如下
import scrapy
import json class BoleSpider(scrapy.Spider):
name = 'boleSpider' def start_requests(self):
url = "https://image.so.com/zj?ch=photography&sn={}&listtype=new&temp=1"
page = self.settings.get("MAX_PAGE")
for i in range(int(page)+1):
yield scrapy.Request(url=url.format(i*30)) def parse(self,response):
photo_list = json.loads(response.text)
for image in photo_list.get("list"):
id = image["id"]
url = image["qhimg_url"]
title = image["group_title"]
thumb = image["qhimg_thumb_url"]
print(id,url,title,thumb)
抓取的结果为
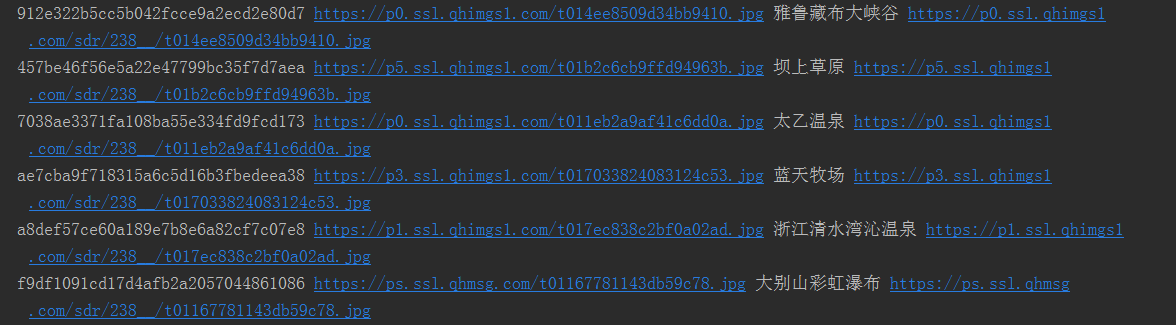
最后,我们已经将360图片的信息已经抓取下来了并打印在的控制台当中。但是我们需要把数据给下载下来,并且进行存储,所以在下一节当中会对item.py文件进行讲解。
第十六节:Scrapy爬虫框架之项目创建spider文件数据爬取的更多相关文章
- 第三百一十六节,Django框架,中间件
第三百一十六节,Django框架,中间件 django 中的中间件(middleware),在django中,中间件其实就是一个类,在请求到来和结束后,django会根据自己的规则在合适的时机执行中间 ...
- scrapy爬虫成长日记之创建工程-抽取数据-保存为json格式的数据
在安装完scrapy以后,相信大家都会跃跃欲试想定制一个自己的爬虫吧?我也不例外,下面详细记录一下定制一个scrapy工程都需要哪些步骤.如果你还没有安装好scrapy,又或者为scrapy的安装感到 ...
- 第二百六十六节,Tornado框架-XSS处理,页码计算,页码显示
Tornado框架-XSS处理,页码计算,页码显示 Tornado框架-XSS攻击过滤 注意:Tornado框架的模板语言,读取数据已经自动处理了XSS攻击,过滤转换了危险字符 如果要使危险字符可以远 ...
- 创建一个scrapy爬虫框架的项目
第一步:打开pycharm,选择"terminal",如图所示: 第二步:在命令中端输入创建scrapy项目的命令:scrapy startproject demo (demo指的 ...
- Scrapy爬虫框架(2)--内置py文件
Scrapy概念图 这里有很多py文件,分别与Scrapy的各个模块对应 superspider是一个爬虫项目 spider1.py则是一个创建好的爬虫文件,爬取资源返回url和数据 items.py ...
- 【php爬虫】百万级别知乎用户数据爬取与分析
代码托管地址:https://github.com/hoohack/zhihuSpider 这次抓取了110万的用户数据,数据分析结果如下: 开发前的准备 安装Linux系统(Ubuntu14.04) ...
- Python爬虫入门教程 3-100 美空网数据爬取
美空网数据----简介 从今天开始,我们尝试用2篇博客的内容量,搞定一个网站叫做"美空网"网址为:http://www.moko.cc/, 这个网站我分析了一下,我们要爬取的图片在 ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
- 第二百五十六节,Web框架
Web框架 Web框架本质 众所周知,对于所有的Web应用,本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端. 举例: #!/usr/bin/env python #c ...
随机推荐
- Keras 文档阅读笔记(不定期更新)
目录 Keras 文档阅读笔记(不定期更新) 模型 Sequential 模型方法 Model 类(函数式 API) 方法 层 关于 Keras 网络层 核心层 卷积层 池化层 循环层 融合层 高级激 ...
- css实现侧边展开收起
前言:因为突然想研究研究侧边栏滑动展开收起怎么做的,就去baidu了一下transition. 详情 内容1 内容1 内容1 内容1 内容1 右侧有实现demo.就是那个绿色的详情 先来看一下我的代码 ...
- Unexpected EOF 远程主机强迫关闭了一个现有的连接 如何处理
由于数据量的增大,调用接口的次数会增加. 当连续向目标网站发送多次request后,目标网站可能会认为是,恶意攻击. 于是会抛出requests异常. 测试代码: for i in range(200 ...
- UART、I2C、SPI三种协议对比
学嵌入式需要打好基础 下面我们来学习下计算机原理里的3种常见总线协议及原理 协议:对等实体之间交换数据或通信所必须遵守规则或标准的集合 1.UART(Universal Asynchronous Re ...
- hdu 5335 Walk Out (搜索)
题目链接: hdu 5335 Walk Out 题目描述: 有一个n*m由0 or 1组成的矩形,探险家要从(1,1)走到(n, m),可以向上下左右四个方向走,但是探险家就是不走寻常路,他想让他所走 ...
- poj 2506 Tiling 递推
题目链接: http://poj.org/problem?id=2506 题目描述: 有2*1和2*2两种瓷片,问铺成2*n的图形有多少种方法? 解题思路: 利用递推思想,2*n可以由2*(n-1)的 ...
- 洛谷 P1600 天天爱跑步
https://www.luogu.org/problemnew/show/P1600 (仅做记录) 自己的假方法: 每一次跑从a到b:设l=lca(a,b)对于以下产生贡献: a到l的链上所有的点( ...
- synchronized(1)用法简介:修饰方法,修饰语句块
注意: 同一个对象或方法在不同线程中才出现同步问题,不同对象在不同线程互相不干扰. synchronized方法有2种用法:修饰方法,修饰语句块 1.synchronized方法 是某个对象实例内,s ...
- 外文翻译 《How we decide》赛场上的四分卫 第四节
这是第一章的最后一节. 书的导言 本章第一节 本章第二节 本章第三节 制作肥皂剧是非常不易的.整个制作组都要很紧张的工作,每天都要拍摄一些新的事件.新的大转折的剧情需要被想象出来,新的剧本需要被编写, ...
- ScrollView嵌套GridView,GridView显示不全
最近开发有个需求是以A-Z的方式区分全国城市(搜索功能),并实现字母索引的功能(有点类似微信,不过比较坑的是用的是GridView, 并且GridView上面还有几个LinearLayout). 详细 ...