kafka 介绍与使用
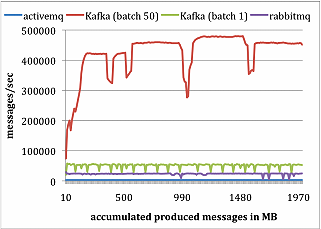
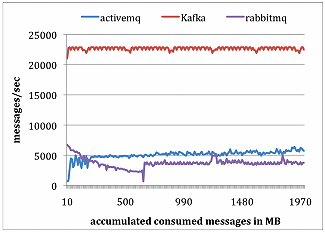
原文:https://blog.csdn.net/SJF0115/article/details/78480433
kafka 介绍与使用的更多相关文章
- Apache Kafka - 介绍
原文地址地址: http://blogxinxiucan.sh1.newtouch.com/2017/07/12/Apache-Kafka-介绍/ Apache Kafka教程 之 Apache Ka ...
- 1、Kafka介绍
1.Kafka介绍 1)在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算. 2)Kafka是一个分布式消息队列. 3)Kafka对消息保存时根据Topic进行归类, ...
- [转]kafka介绍
转自 https://www.cnblogs.com/hei12138/p/7805475.html kafka介绍 1.1. 主要功能 根据官网的介绍,ApacheKafka®是一个分布式流媒体平台 ...
- Kafka介绍及安装部署
本节内容: 消息中间件 消息中间件特点 消息中间件的传递模型 Kafka介绍 安装部署Kafka集群 安装Yahoo kafka manager kafka-manager添加kafka cluste ...
- kafka介绍与搭建(单机版)
一.kafka介绍 1.1 主要功能 根据官网的介绍,ApacheKafka®是一个分布式流媒体平台,它主要有3种功能: 1:It lets you publish and subscribe to ...
- kafka介绍及安装配置(windows)
Kafka介绍 Kafka是分布式的发布—订阅消息系统.它最初由LinkedIn(领英)公司发布,使用Scala和Java语言编写,与2010年12月份开源,成为Apache的顶级项目.Kafka是一 ...
- 一、kafka 介绍 && kafka-client
一.kafka 介绍 1.1.kafka 介绍 Kafka 是一个分布式消息引擎与流处理平台,经常用做企业的消息总线.实时数据管道,有的还把它当做存储系统来使用. 早期 Kafka 的定位是一个高吞吐 ...
- 3 kafka介绍
本博文的主要内容有 .kafka的官网介绍 http://kafka.apache.org/ 来,用官网上的教程,快速入门. http://kafka.apache.org/documentatio ...
- Kafka介绍
本文介绍LinkedIn开源的Kafka,久仰大名了,依照其官方文档做些翻译和二次创作.相应能够查看整份官方文档. 基本术语 topics,维护的消息源种类(更像是业务上的数据种类/分类) produ ...
- 漫游Kafka介绍章节简介
原文地址:http://blog.csdn.net/honglei915/article/details/37564521 介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息 ...
随机推荐
- python可变类型与不可变类型
一.可变类型与不可变类型的特点 1.不可变数据类型 不可变数据类型在第一次声明赋值声明的时候, 会在内存中开辟一块空间, 用来存放这个变量被赋的值, 而这个变量实际上存储的, 并不是被赋予的这个值, ...
- Yii2.0 RESTful API 之速率限制
Yii2.0 RESTFul API 之速率限制 什么是速率限制? 权威指南翻译过来为限流,为防止滥用,你应该考虑对您的 API 限流. 例如,您可以限制每个用户 10 分钟内最多调用 API 100 ...
- SAS学习笔记28 非参数秩和检验
在总体分布已知的前提下对参数进行的检验,即参数检验方法(parametric test). 然而,在实际中有些资料总体分布类型未知,或者不符合参数检验的适用条件,这时可以使用不以特定的总体分布为前提, ...
- 复杂链表的复制——牛客offer
题目描述: 输入一个复杂链表(每个节点中有节点值,以及两个指针,一个指向下一个节点,另一个特殊指针指向任意一个节点),返回结果为复制后复杂链表的head.(注意,输出结果中请不要返回参数中的节点引用, ...
- 加密算法 MD5 和 SHA 的 JAVA 实现
首先先简单的介绍一下MD5 和 SHA 算法 然后看一下在 java.security.MessageDigest (信息摘要包下) 如何分别实现 md5 加密 和 sha 加密 最后在看一下 ...
- mysql8中查询语句表别名不能使用 “of”
今天在迁移一个项目的时候,发现有一个sql报错,但是语句跟迁移之前完全一样,所以想来应该是 mysql 版本差异导致的. 迁移之前版本:5.6.28(腾讯云) 迁移之后版本:8.0.16(阿里云) 新 ...
- maven项目打包和编译跳过单元测试和javadoc
代码中可能由于单元测试.注释(方法中的参数)或者maven javadoc插件的问题导致无法打包,影响工作,为避免这两种情况可以在打包时输入命令: mvn clean install -Dmaven. ...
- React/事件系统
React基于虚拟DOM实现了一个合成事件层,我们所定义的事件处理器会接收到一个合成事件对象的实例事件处理. 并且所有事件都自动绑定在最外层上.如果需要访问原生事件对象,可以使用nativeEvent ...
- js入门之函数
一. 函数 函数可以封装一段特定功能的代码,然后通过函数名可以重复调用 1 .函数的定义 funcation 函数名 (){ 函数体 } 函数名() 调用函数 2. 函数的参数 funcation f ...
- Ubuntu-Python2.7安装 scipy,numpy,matplotlib (转)
sudo apt-get install python-scipy sudo apt-get install python-numpy sudo apt-get install python-matp ...