python网络爬虫笔记(二)
一、函数调用的默认设置
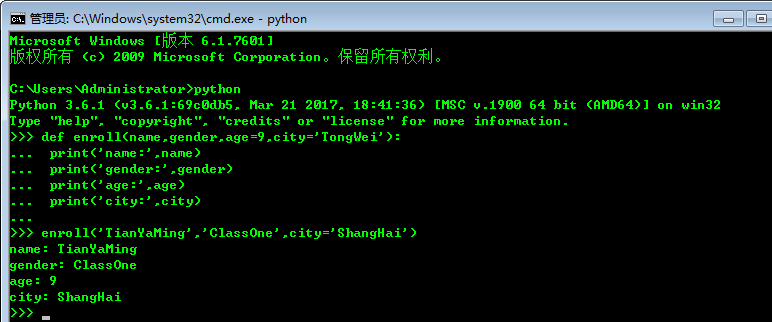
1、def enroll(name,grnder,age=4,city='Shanghai'):
print (''name:',name)
print (''gender', gender)
print('city',city)
print (''age', age)
这样调用参数的时候只需要传入 变化的参数 enroll('TianYaming','classONe'')
默认参数不符合的可以传入不同的参数。 enroll('TianYaming', 'ClassOne' '5) 注意参数的提供是按照 原先的预定的顺序执行

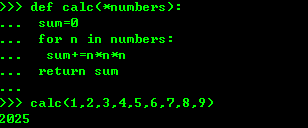
2、关键字参数

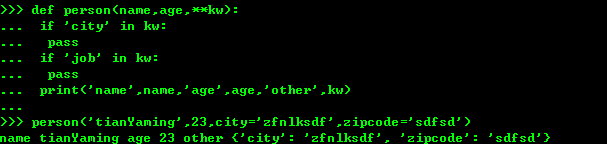
3、命名关键字参数 函数的调用者可以传入不受限制的的关键字参数,至于传入那些参数,就需要函数内部通过kw检查
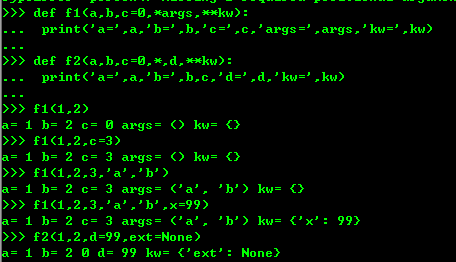
4、和关键字参数**kw不同,命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。

则也就是说,命名关键字参数必须传入参数名,不然报错
5、递归函数的使用
使用递归函数,要注意堆栈的溢出,理论上所有的递归可以写成循环的函数,但是循环的结构不如递归清晰
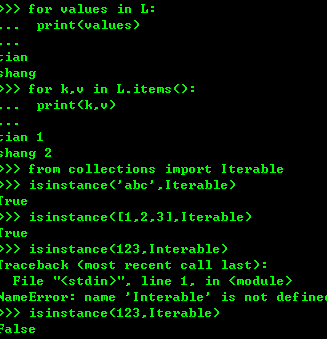
默认情况下,dict迭代的是key。如果要迭代value,可以用for value in d.values(),如果要同时迭代key和value,可以用for k, v in d.items()。
由于字符串也是可迭代对象
判断可以迭代的方法就是 使用collections 模块中的Iterable

python网络爬虫笔记(二)的更多相关文章
- Python网络爬虫笔记(五):下载、分析京东P20销售数据
(一) 分析网页 下载下面这个链接的销售数据 https://item.jd.com/6733026.html#comment 1. 翻页的时候,谷歌F12的Network页签可以看到下面 ...
- python 网络爬虫(二) BFS不断抓URL并放到文件中
上一篇的python 网络爬虫(一) 简单demo 还不能叫爬虫,只能说基础吧,因为它没有自动化抓链接的功能. 本篇追加如下功能: [1]广度优先搜索不断抓URL,直到队列为空 [2]把所有的URL写 ...
- python 网络爬虫(二)
一.编写第一个网络爬虫 为了抓取网站,我们需要下载含有感兴趣的网页,该过程一般被称为爬取(crawling).爬取一个网站有多种方法,而选择哪种方法更加合适,则取决于目标网站的结构. 首先探讨如何安全 ...
- Python网络爬虫笔记(二):链接爬虫和下载限速
(一)代码1(link_crawler()和get_links()实现链接爬虫) import urllib.request as ure import re import urllib.parse ...
- python网络爬虫之二requests模块
requests http请求库 requests是基于python内置的urllib3来编写的,它比urllib更加方便,特别是在添加headers, post请求,以及cookies的设置上,处理 ...
- python网络爬虫笔记(三)
一.切片和迭代 1.列表生成式 2.生成器的generate,但是generate保存的是算法,所以可以迭代计算,没有必要,每次调用generate 二.iteration 循环 1.凡是作用于for ...
- Python网络爬虫笔记(四):使用selenium获取动态加载的内容
(一) 说明 上一篇只能下载一页的数据,第2.3.4....100页的数据没法获取,在上一篇的基础上修改了下,使用selenium去获取所有页的href属性值. 使用selenium去模拟浏览器有点 ...
- Python网络爬虫笔记(一):网页抓取方式和LXML示例
(一) 三种网页抓取方法 1. 正则表达式: 模块使用C语言编写,速度快,但是很脆弱,可能网页更新后就不能用了. 2. Beautiful Soup 模块使用Python编写,速度慢. ...
- [Python]网络爬虫(二):利用urllib2通过指定的URL抓取网页内容
版本号:Python2.7.5,Python3改动较大. 所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地. 类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求的 ...
随机推荐
- C 捕获 lua 异常错误
参考文章https://blog.codingnow.com/2015/05/lua_c_api.html , , )) { printf("file=%s, func=%s, line=% ...
- Django REST framework 第二章 Request and Response
此章节开始真正的撰写REST framework的核心代码,介绍一系列必要的建立设计 Request Objects REST framework介绍了一个Request对象用来扩展常规的HttpRe ...
- var/let/const区别何在??(转载)
原文地址:http://www.cnblogs.com/liuhe688/p/5845561.html let和const有很多相似之处,先说一说let吧. 1. let添加了块级作用域 我们知道,J ...
- python第三天,字符串续
字符串类型 在python中字符串类型可以用 成对单引号,如:'你好,中国.': 也可以用成对双引号,如:"厉害了,我滴国".代码如下: 通过.title(),可以将一段话的首字母 ...
- mac环境下支持PHP调试工具xdebug,phpstorm监听
先让php支持xdebug 方式一: https://xdebug.org/download.php 下载相应的xdebug 可以到http://xdebug.org/wizard.php 把php ...
- Simple scatter method in 2d picture(Qt)
Result: grayMap: MathTools: // // Created by Administrator on 2017/8/17. // #ifndef QTSCATTER_MATHTO ...
- Linux下查询文件的md5,sha1值
验证下载下来的文件包是不是一致 ··· 验证md5值 #md5sum filename 验证shal值 #sha1sum filename ···
- Python运维开发基础07-文件基础【转】
一,文件的基础操作 对文件操作的流程 [x] :打开文件,得到文件句柄并赋值给一个变量 [x] :通过句柄对文件进行操作 [x] :关闭文件 创建初始操作模板文件 [root@localhost sc ...
- salt使用技巧
实时截获任务输出 __salt__['event.send']("module_send_event", {'message': message, 'jid': jid}, ...
- OTP
OTP 是 One Time Programable, 一次性可编程,一种存储器类型.顾名思义,只允许一次编程,后面无法修改. 在嵌入式系统当中,所有的代码和系统数据都是存储在flash芯片内部的,f ...