hadoop实例-网站用户行为分析
一、数据集
网站用户购物行为数据集2030万条,包括raw_user.csv(2000万条)和small_user.csv(30万条,适合新手)
字段说明:
user_id 用户编号,item_id 商品编号,behavior_type 用户操作类型:1(浏览)、2(收藏)、3(加入购物车)、4(购买)
user_geohash 用户地理位置哈希值,在预处理中将其转化为province省份、item_category商品分类,time 用户操作时间
二、实验任务
- 安装Linux操作系统
- 安装关系型数据库MySQL
- 安装大数据处理框架Hadoop
- 安装列族数据库HBase
- 安装数据仓库Hive
- 安装Sqoop
- 安装R
- 安装Eclipse
- 对文本文件形式的原始数据集进行预处理
- 把文本文件的数据集导入到数据仓库Hive中
- 对数据仓库Hive中的数据进行查询分析
- 使用Sqoop将数据从Hive导入MySQL
- 使用Sqoop将数据从MySQL导入HBase
- 使用HBase Java API把数据从本地导入到HBase中
- 使用R对MySQL中的数据进行可视化分析
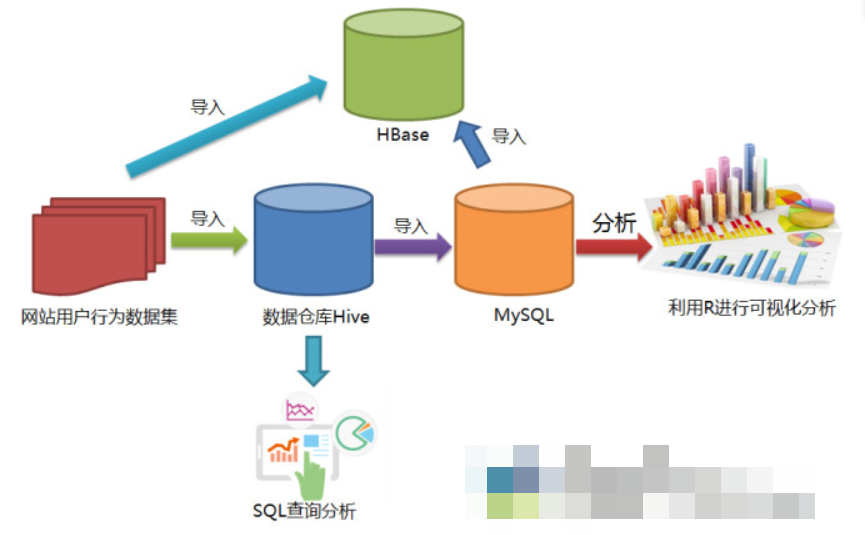
三、实验步骤
(一)对csv进行预处理
1.去除csv文件的表头
cd ~/下载
sed -i '1d' raw_user.csv # 删除第一行
sed -i '1d' small_user.csv
head -5 raw_user.csv # 查看前5行内容
head -g small-user.csv
2.将user_geohash转化为province,并将文件格式转化为txt
具体转化细节不说明,本文注重整个分析过程,详细内容参考林子雨老师的博客。
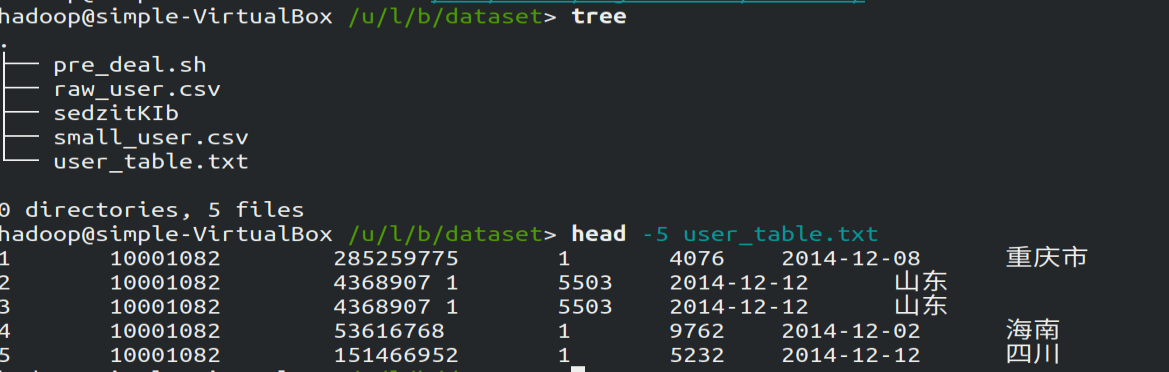
转化成功后,在该目录通过pre_deal.sh脚本加载small_user.csv生成user_table.txt文件,使用tree查看该目录结构:
Hive是基于Hadoop的数据仓库,在将user_table中的数据导入的数据仓库之前,需要先把user_table.txt文件上传到HDFS中。然后再Hive中创建外部表,完成数据的导入。
启动HDFS:由于笔者在安装hadoop时已完成了环境变量的配置,现在在任意目录执行下面的语句开启hadoop:
将user_table.txt文件上传到HDFS中

在HDFS中查看该文件的前10行:

(二)将HDFS中的文件导入到Hive数据仓库中
1.启动mysql数据库
mysql用于保存Hive的元数据(在安装Hive时需要配置),因此需先开启mysql服务

2.启动hive,启动成功后如下图所示
3.创建数据库,并建立外部表,将HDFS中/bigdatacase/dataset目录下的文件作为该外部表的内容
hive> create database dblab;
hive> use dblab;
hive> CREATE EXTERNAL TABLE dblab.bigdata_user(id INT,
uid STRING,item_id STRING,behavior_type INT,item_category STRING,
visit_date DATE,province STRING) COMMENT 'Welcome to xmu dblab!'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION
'/bigdatacase/dataset';
4.使用Hive命令进行查询
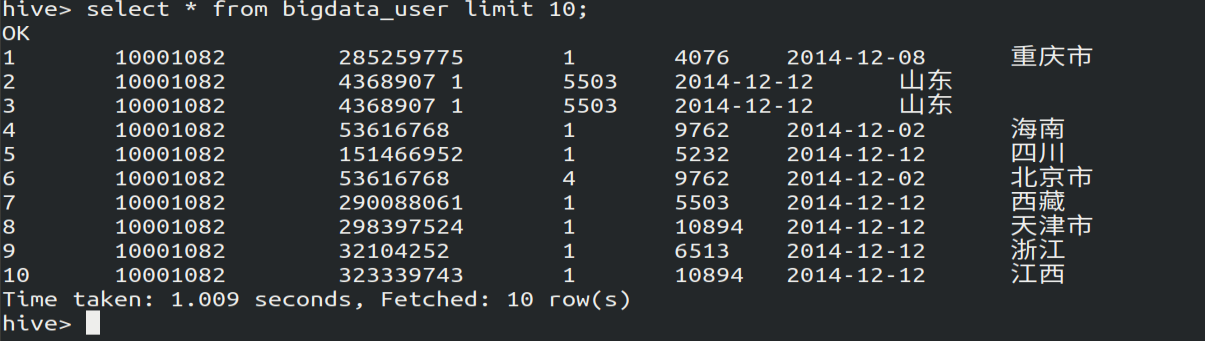
(三)用Hive对数据进行简单的分析
用Hive对数据仓库里的数据进行查询时,需要先开启mysql服务,用于存储Hive的元数据。
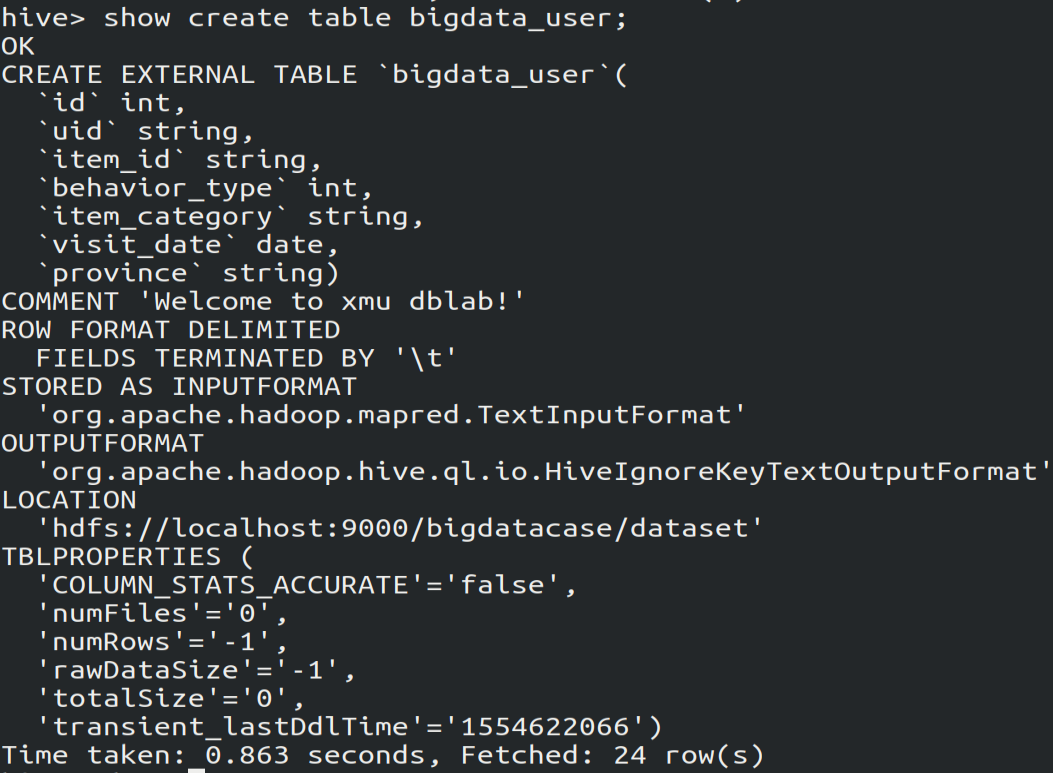
1.查看表的创建过程
show create table bigdata_user; # 查看该表是如何被创建的
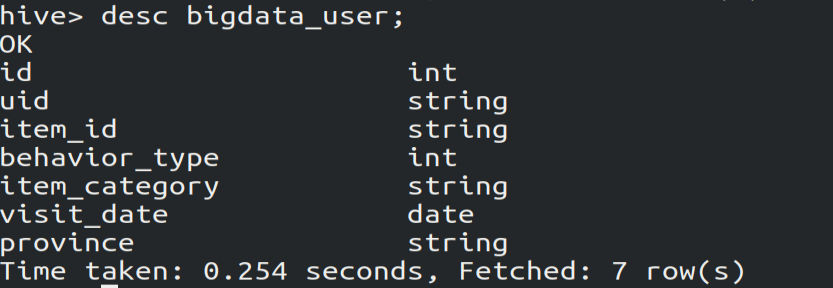
2.查看表的属性及属性的数据类型
desc bigdata_user;
3.对表进行数据分析
(1)查看前10个网站用户的访问日期和所在身份
select visit_date,province from bigdata_user limit ;
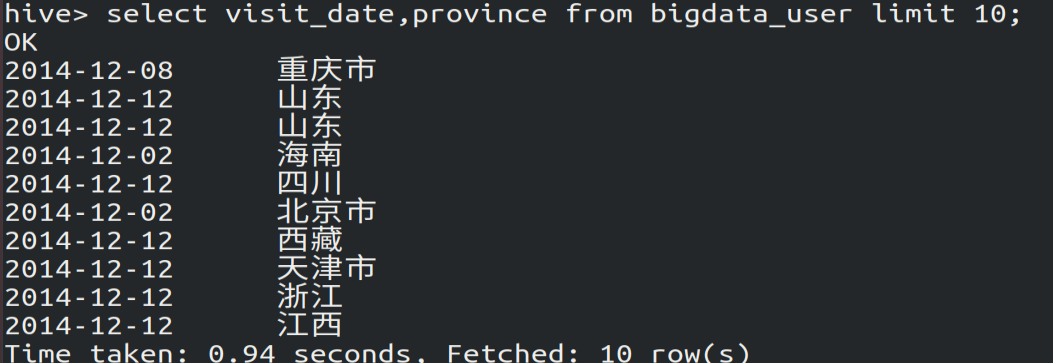
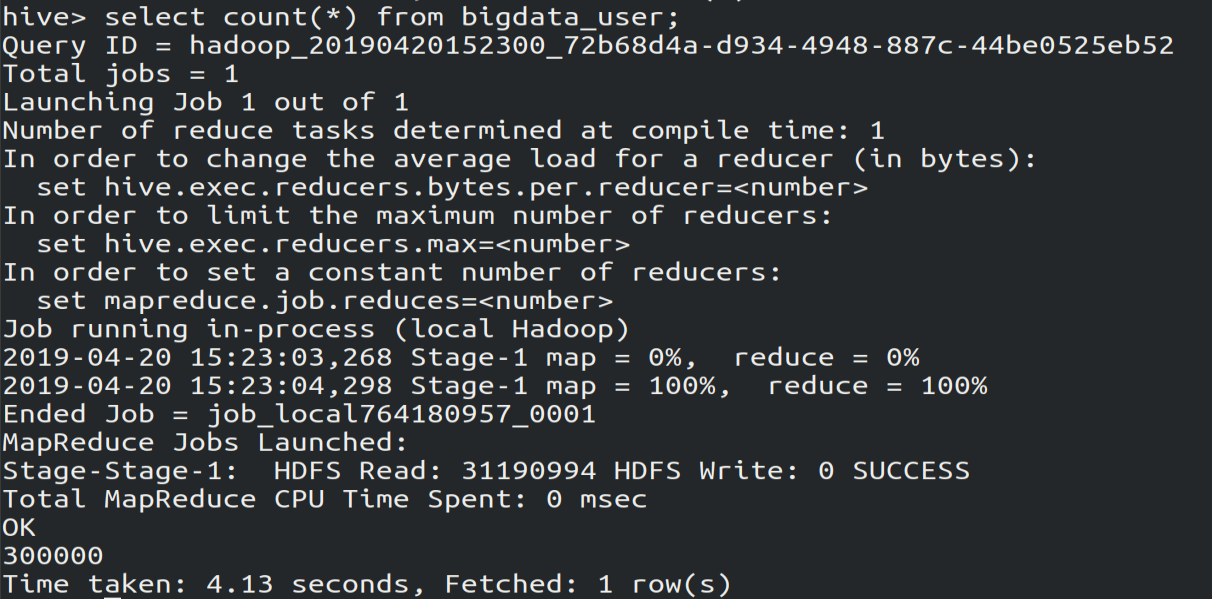
(2)查看bigdata_user表中有多少行数据:30万条
select count(*) from bigdata_user;
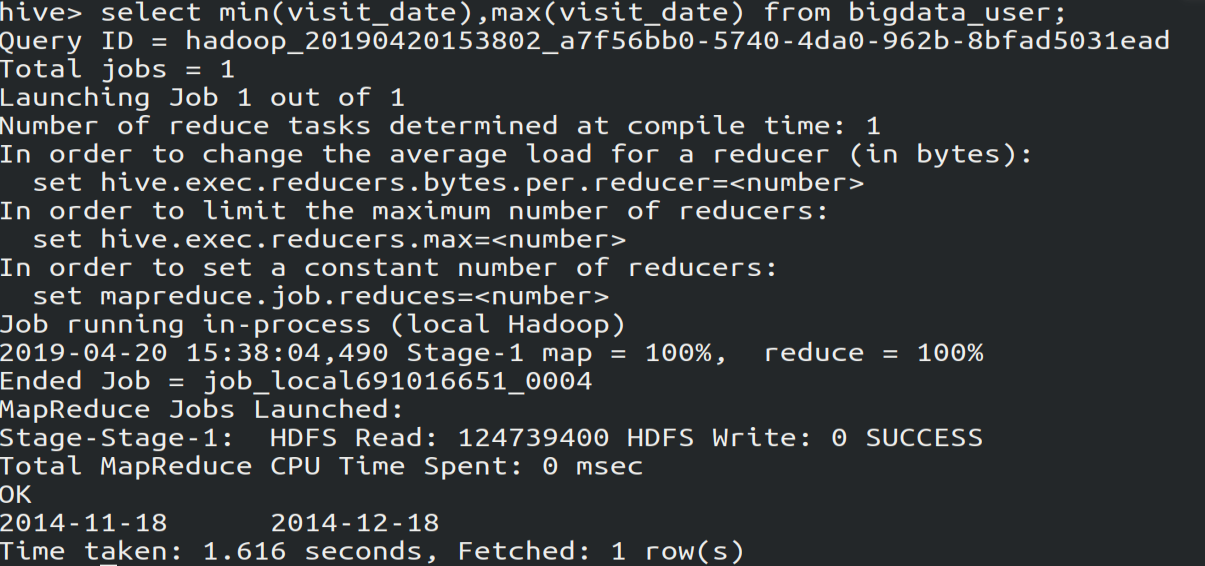
(3)查看bigdata_user表里用户访问网站的时间段,由图可知是2014-11-18到2014-12-18。
select min(visit_date),max(visit_date) from bigtdata_user;
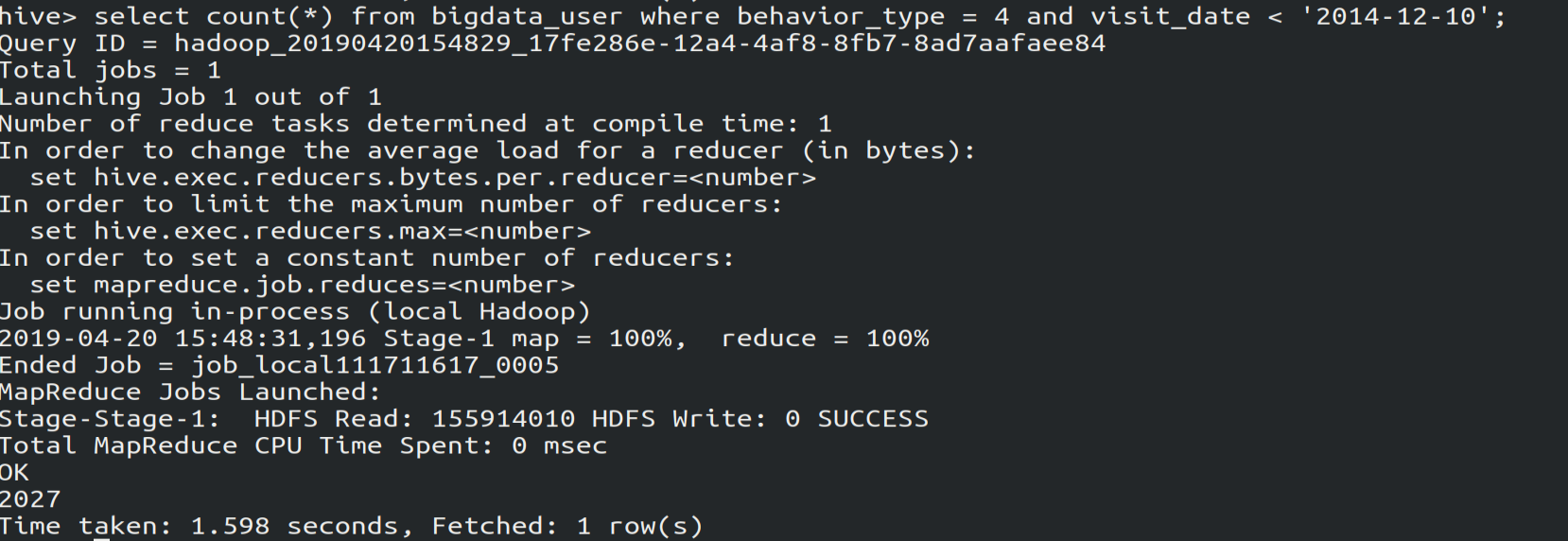
(4)查看2014-12-10前多少人买了东西:2027个人
select count(*) from bigdata_user where bahavior = and visit_date<'2014-12-10'
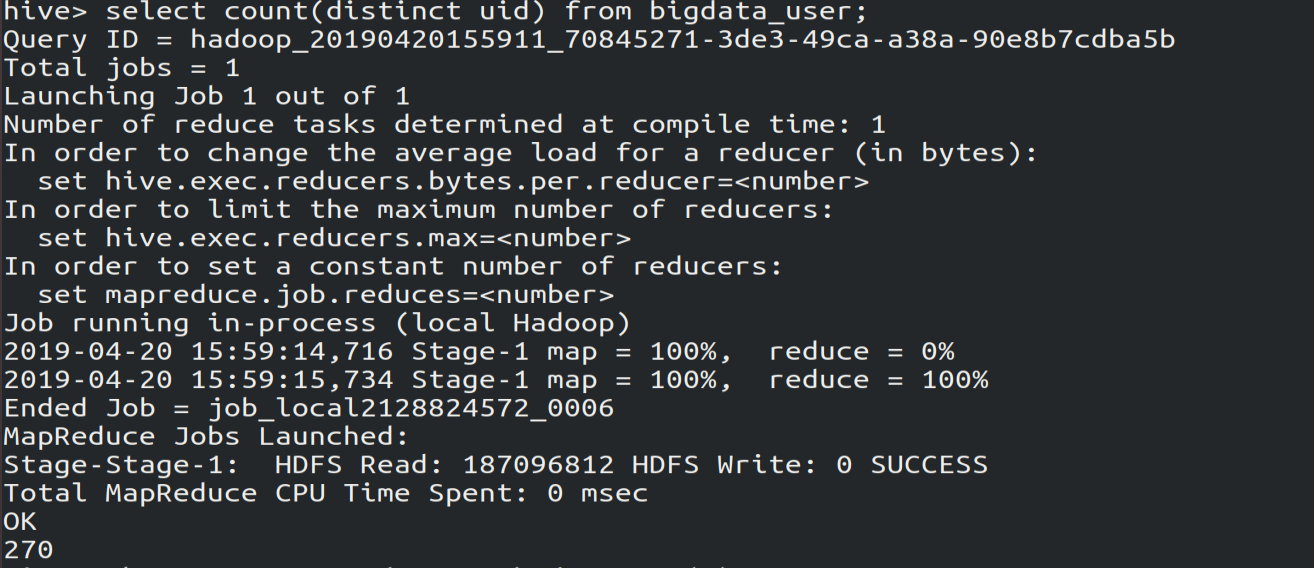
(5)查看一共有多少用户,去重查询。由图可知,虽然一共有30万条访问记录,但实际上只有270个用户。
select count(distinct uid) from bigdata_user;
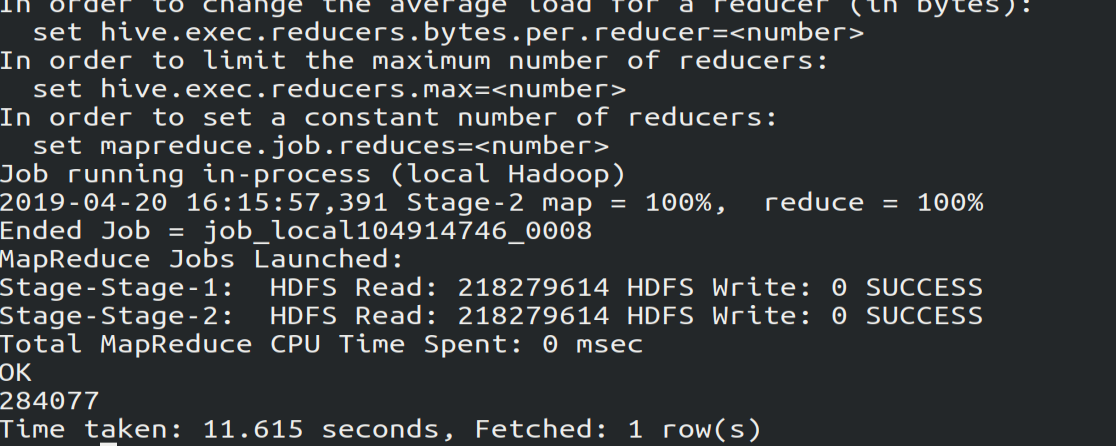
(6) 为防止客户刷单,查看有多少不同的数据,由图可知,有284077条数据
select count(*)
from (select uid,item_id,behavior_type,item_category,visit_date,province
from bigdata_user
group by uid,item_id,behavior_type,item_category,visit_date,province
having count(*)=1
)a; # a是别名
分析就到这里,等刷爆MySQL8.0再来更新!
hadoop实例-网站用户行为分析的更多相关文章
- 网站用户行为分析——HBase的安装与配置
Hbase介绍 HBase是一个分布式的.面向列的开源数据库,源于Google的一篇论文<BigTable:一个结构化数据的分布式存储系统>.HBase以表的形式存储数据,表有行和列组成, ...
- 网站用户行为分析——Hadoop的安装与配置(单机和伪分布式)
Hadoop安装方式 Hadoop的安装方式有三种,分别是单机模式,伪分布式模式,伪分布式模式,分布式模式. 单机模式:Hadoop默认模式为非分布式模式(本地模式),无需进行其他配置即可运行.非分布 ...
- 网站用户行为分析——Linux的安装
Linux的选择 在Linux系统各个发行版中,CentOS系统和Ubuntu系统在服务端和桌面端使用占比最高,网络上资料最是齐全,所以建议使用CentOS系统或Ubuntu. 一般来说,如果要做服务 ...
- 网站用户行为分析——在Ubuntu下安装MySQL及其常用操作
安装MySQL 使用以下命令即可进行mysql安装,注意安装前先更新一下软件源以获得最新版本: sudo apt-get update #更新软件源 sudo apt-get install mysq ...
- Hadoop项目实战-用户行为分析之分析与设计
1.概述 本课程的视频教程地址:<用户行为分析之分析与设计> 下面开始本教程的学习,本教程以用户行为分析案例为基础,带着大家对项目的各个指标做详细的分析,对项目的整体设计做合理的规划,让大 ...
- Hadoop项目实战-用户行为分析之应用概述(一)
1.概述 本课程的视频教程地址:<Hadoop 回顾> 好的,下面就开始本篇教程的内容分享,本篇教程我为大家介绍我们要做一个什么样的Hadoop项目,并且对Hadoop项目的基本特点和其中 ...
- Python之路,Day22 - 网站用户访问质量分析监测分析项目开发
Python之路,Day22 - 网站用户访问质量分析监测分析项目开发 做此项目前请先阅读 http://3060674.blog.51cto.com/3050674/1439129 项目实战之 ...
- Hadoop项目实战-用户行为分析之编码实践
1.概述 本课程的视频教程地址:<用户行为分析之编码实践> 本课程以用户行为分析案例为基础,带着大家去完成对各个KPI的编码工作,以及应用调度工作,让大家通过本课程掌握Hadoop项目的编 ...
- Hadoop项目实战-用户行为分析之应用概述(三)
1.概述 本课程的视频教程地址:<项目工程准备> 本节给大家分享的主题如下图所示: 下面我开始为大家分享今天的第三节的内容——<项目工程准备>,接下来开始分享今天的内容. 2. ...
随机推荐
- LeetCode算法题-Linked List Cycle(Java实现)
这是悦乐书的第176次更新,第178篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第35题(顺位题号是141).给定一个链表,确定它是否有一个循环. 本次解题使用的开发工 ...
- 洛谷模拟NOIP考试反思
洛谷模拟NOIP考试反思 想法 考了这么简单的试qwq然而依然emmmmmm成绩不好 虽然本次难度应该是大于正常PJ难度的但还是很不理想,离预估分数差很多qwq 于是就有了本反思嘤嘤嘤 比赛链接 原比 ...
- 用js显示系统当前日期
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title&g ...
- C. Meaningless Operations Codeforces Global Round 1 异或与运算,思维题
C. Meaningless Operations time limit per test 1 second memory limit per test 256 megabytes input sta ...
- UVA 11645 - Bits(数论+计数问题)
题目链接:11645 - Bits 题意:给定一个数字n.要求0-n的二进制形式下,连续11的个数. 思路:和 UVA 11038 这题相似,枚举中间,然后处理两边的情况. 只是本题最大的答案会超过l ...
- RandomAccess
在List集合中,我们经常会用到ArrayList以及LinkedList集合,但是通过查看源码,就会发现ArrayList实现RandomAccess接口,但是RandomAccess接口里面是空的 ...
- [matlab] 11.多边形凹凸性检测
clear all;close all;clc; n=20; p=rand(n,2); p=createSimplyPoly(p); %创建简单多边形 hold on; for i=1:n if i= ...
- ubuntu1604配置ss代理
1 安装ss 参考http://www.cnblogs.com/mdzz/p/10140066.html sudo apt install python3-pip sudo pip3 install ...
- 分区默认segment大小变化(64k—>8M)
_partition_large_extents和_index_partition_large_extents 参考: http://www.xifenfei.com/2013/08/%E5%88%8 ...
- 盘点 Oracle 11g 中新特性带来的10大性能影响
Oracle的任何一个新版本,总是会带来大量引人瞩目的新特性,但是往往在这些新特性引入之初,首先引起的是一些麻烦,因为对于新技术的不了解.因为对于旧环境的不适应,从Oracle产品到技术服务运维,总是 ...