大数据Web可视化分析系统开发


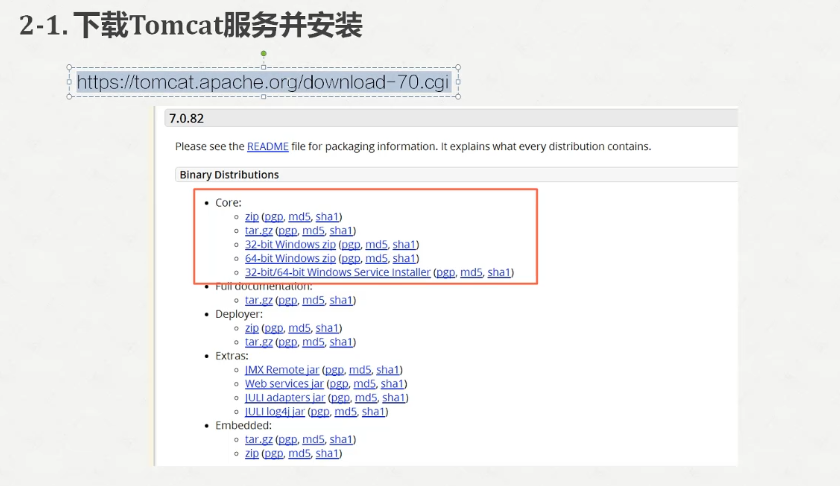
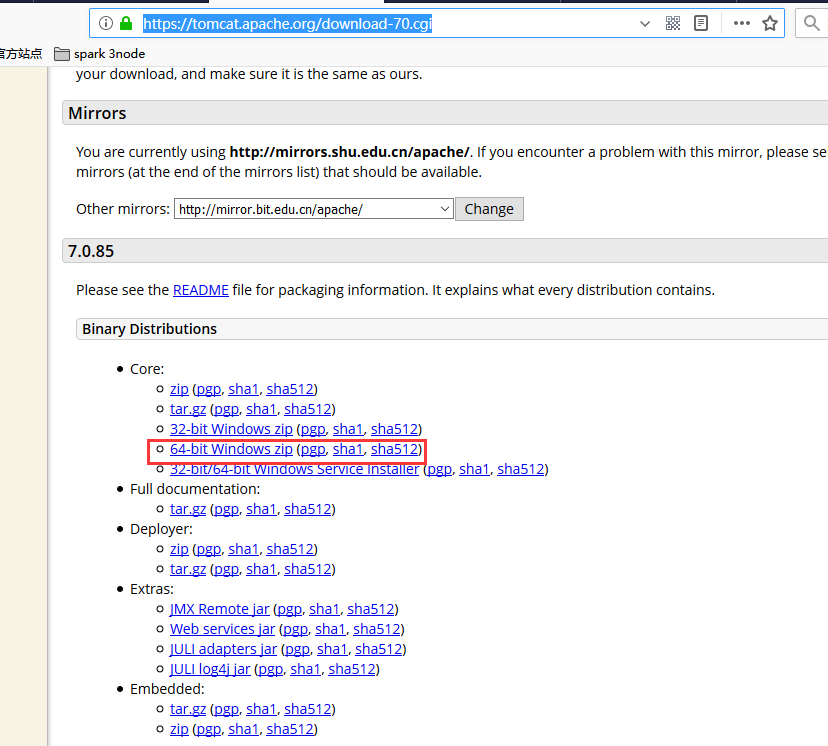
下载地址
https://tomcat.apache.org/download-70.cgi
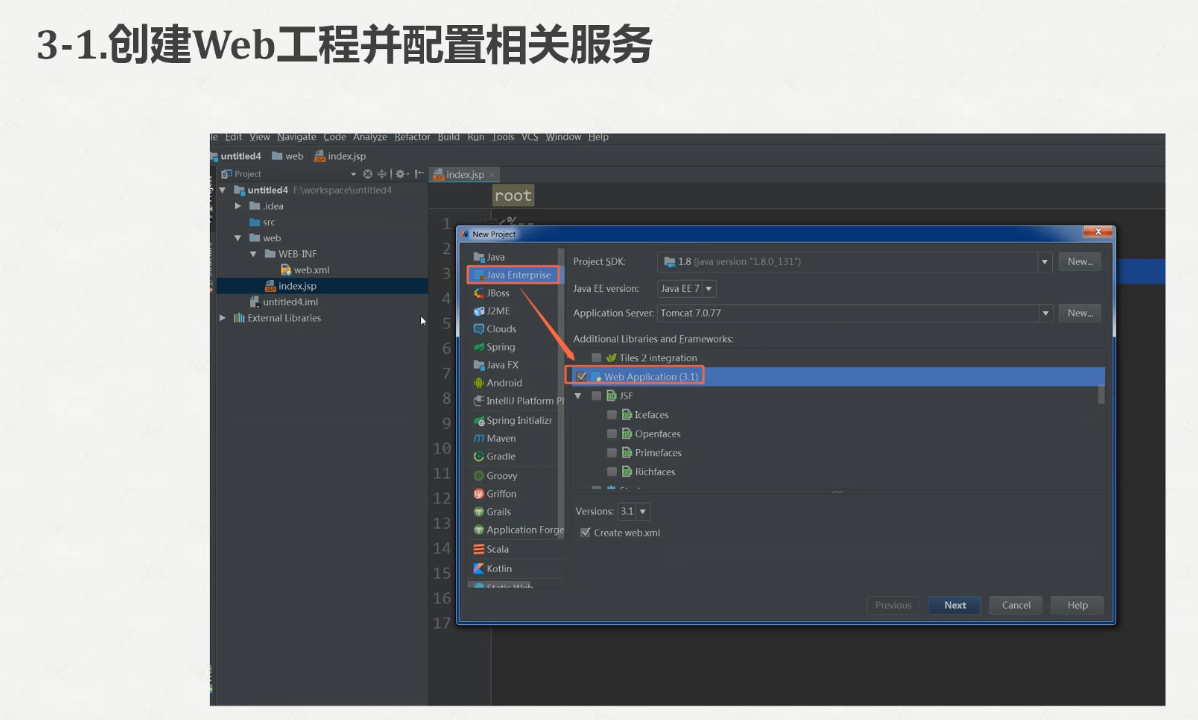



打开我们的idea




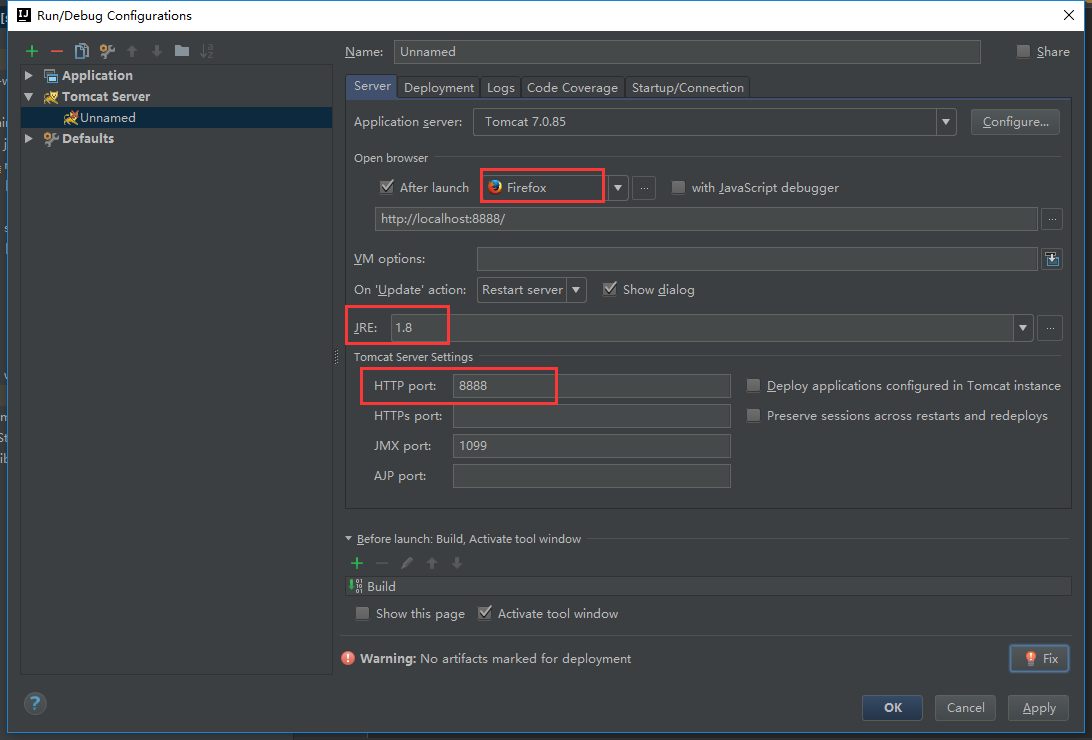
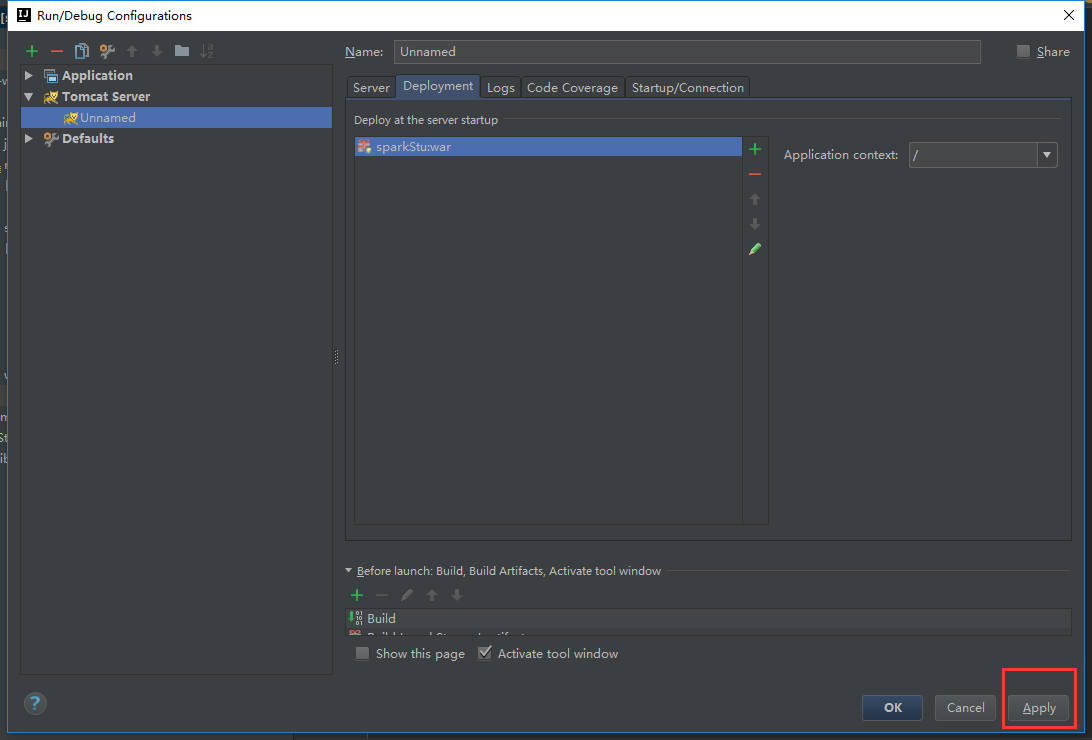
这些的话都可以按照自己的需求来修改


在这里新建包

新建一个java类
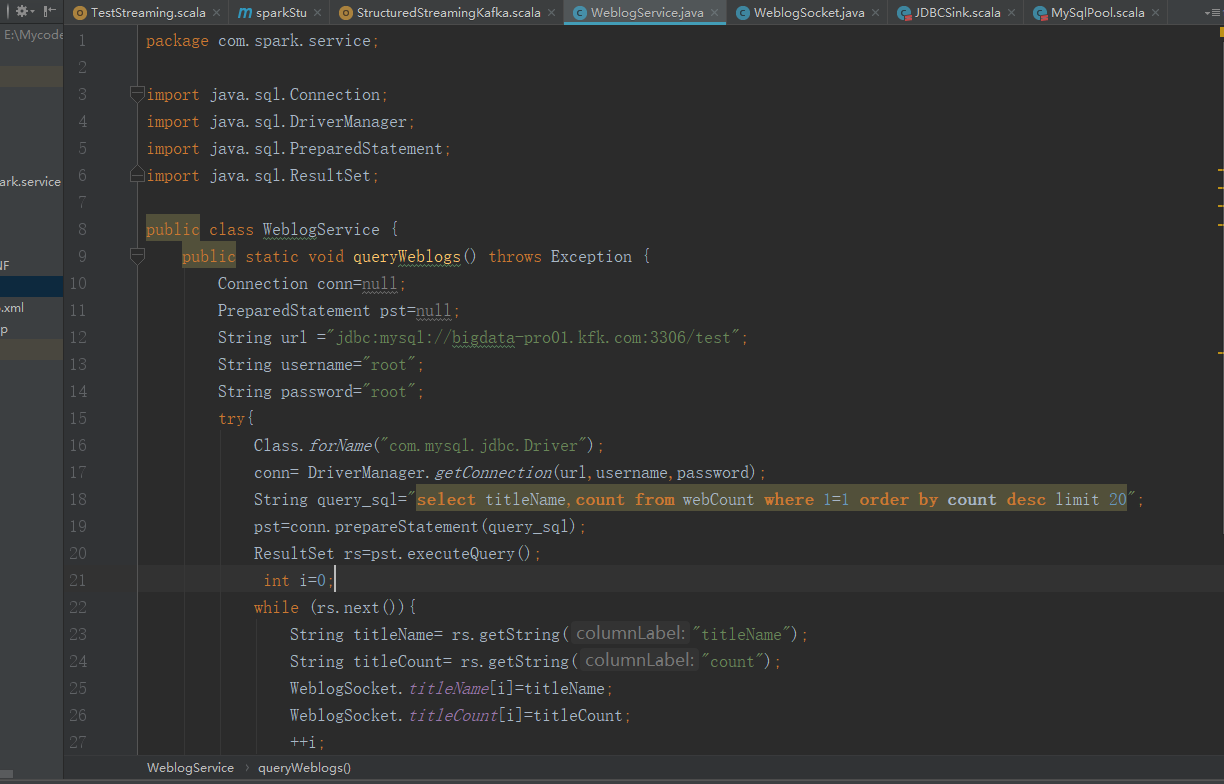
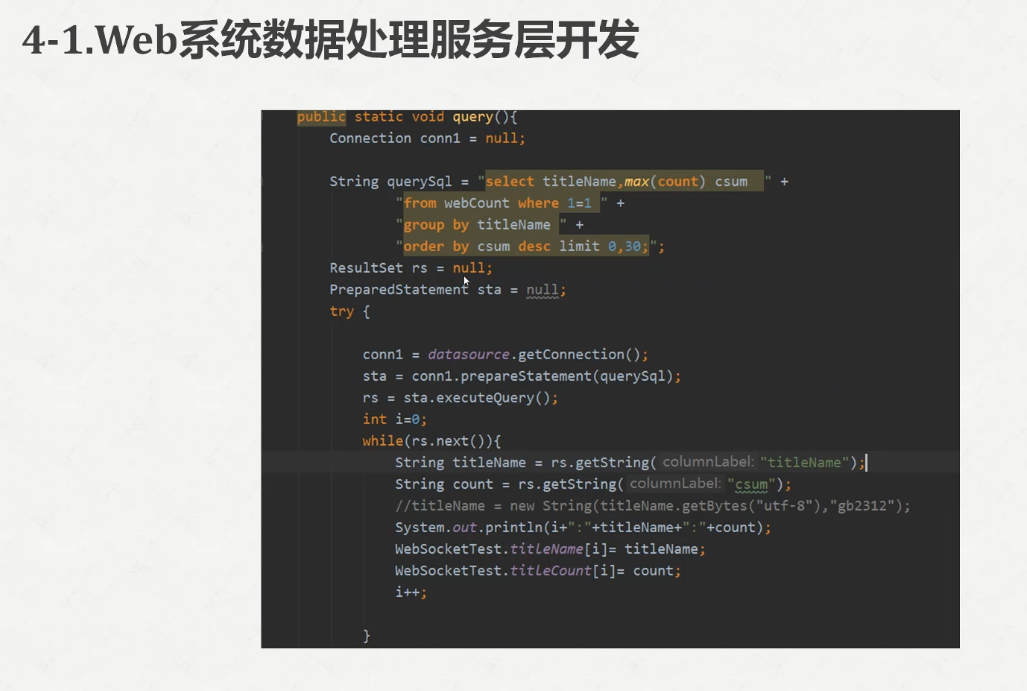
package com.spark.service; import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet; public class WeblogService {
public static void queryWeblogs() throws Exception {
Connection conn=null;
PreparedStatement pst=null;
String url ="jdbc:mysql://bigdata-pro01.kfk.com:3306/test";
String username="root";
String password="root";
try{
Class.forName("com.mysql.jdbc.Driver");
conn= DriverManager.getConnection(url,username,password);
String query_sql="select titleName,count from webCount where 1=1 order by count desc limit 20";
pst=conn.prepareStatement(query_sql);
ResultSet rs=pst.executeQuery();
int i=0;
while (rs.next()){
String titleName= rs.getString("titleName");
String titleCount= rs.getString("count");
WeblogSocket.titleName[i]=titleName;
WeblogSocket.titleCount[i]=titleCount;
++i;
}
}catch (Exception e){
e.printStackTrace();
}
}
}
再新建一个类
我们把tomcat包加载进来



把这些包拷贝到工程目录下

还需要把这些包引进来


写入代码
package com.spark.service;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map; import com.alibaba.fastjson.JSON; import javax.websocket.OnClose;
import javax.websocket.OnMessage;
import javax.websocket.OnOpen;
import javax.websocket.Session;
import javax.websocket.server.ServerEndpoint;
@ServerEndpoint("/websocket")
public class WeblogSocket {
public static String[] titleName = new String[];
public static String[] titleCount = new String[];
//public static String[] titleSum = new String[1];
@OnMessage
public void onMessage(String message,Session session)
throws Exception {
while (true){
WeblogService.queryWeblogs();
Map<String,Object> map =new HashMap<String, Object>();
map.put("titleName", titleName);
map.put("titleCount",titleCount);
// map.put("titleSum", titleSum); session.getBasicRemote().
sendText(JSON.toJSONString(map));
Thread.sleep();
map.clear(); }
} @OnOpen
public void onOpen () {
System.out.println("Client connected");
}
@OnClose
public void onClose () {
System.out.println("Connection closed");
}
}

下载地址
http://echarts.baidu.com/download.html

官网地址 http://jquery.com/

我们拷贝到webapp底下
我们进到echars的官方实例去看看
http://echarts.baidu.com/examples/#chart-type-bar
点进来
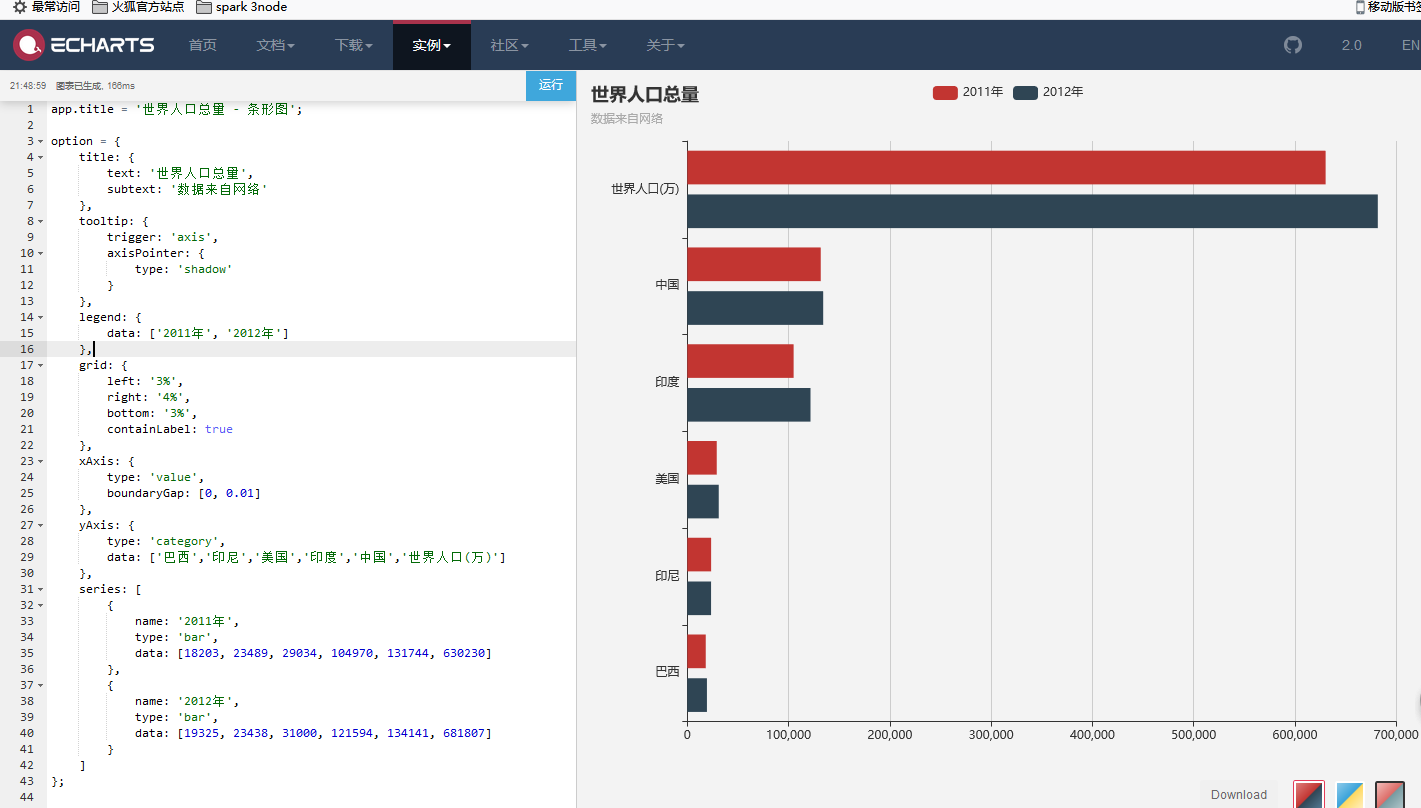
把左边的代码修改之后

新建一个html文件

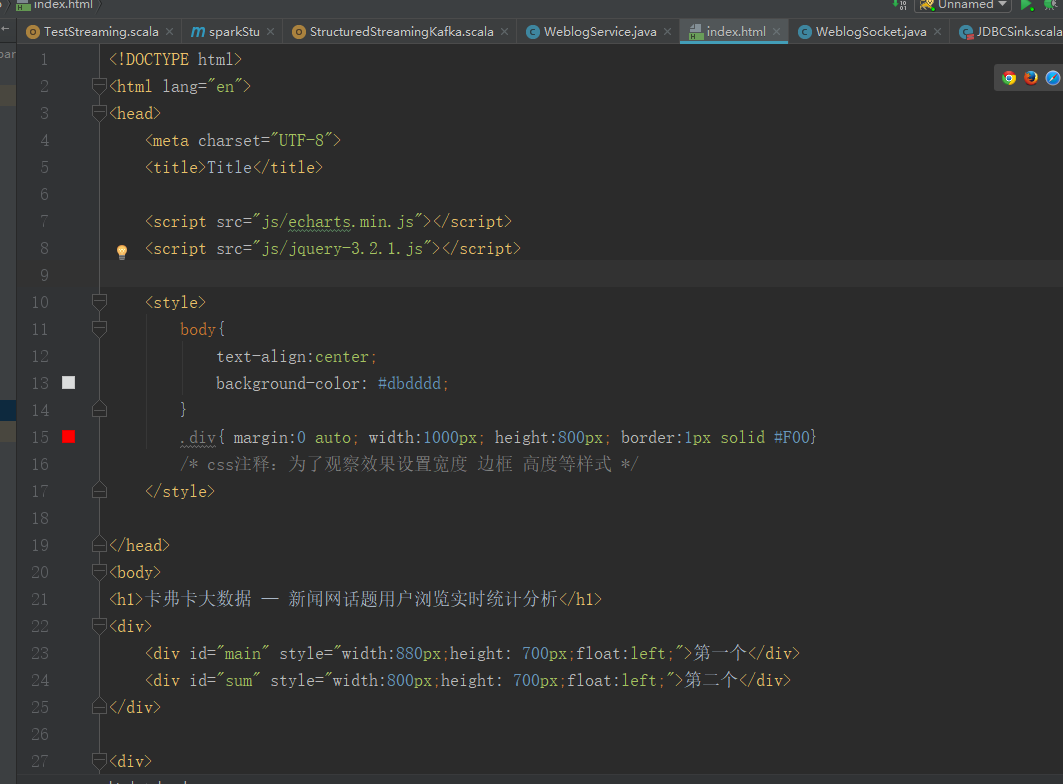
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title> <script src="js/echarts.min.js"></script>
<script src="js/jquery-3.2.1.js"></script> <style>
body{
text-align:center;
background-color: #dbdddd;
}
.div{ margin:0 auto; width:1000px; height:800px; border:1px solid #F00}
/* css注释:为了观察效果设置宽度 边框 高度等样式 */
</style> </head>
<body>
<h1>卡弗卡大数据 — 新闻网话题用户浏览实时统计分析</h1>
<div>
<div id="main" style="width:880px;height: 700px;float:left;">第一个</div>
<div id="sum" style="width:800px;height: 700px;float:left;">第二个</div>
</div> <div>
<input type="submit" value="实时分析" onclick="start()" />
</div> <div id="messages"></div>
<script type="text/javascript"> var webSocket = new WebSocket('ws://localhost:8888/websocket');
var myChart = echarts.init(document.getElementById('main'));
var myChart_sum = echarts.init(document.getElementById('sum')); webSocket.onerror = function(event) {
onError(event)
};
webSocket.onopen = function(event) {
onOpen(event)
};
webSocket.onmessage = function(event) {
onMessage(event)
};
function onMessage(event) {
var sd = JSON.parse(event.data);
processingData(sd);
titleSum(sd.titleSum);
}
function onOpen(event) {
} function onError(event) {
alert(event.data);
} function start() {
webSocket.send('hello');
return false;
} function processingData(json){ var option = {
backgroundColor: '#ffffff',//背景色
title: {
text: '新闻话题浏览量【实时】排行',
subtext: '数据来自搜狗实验室',
textStyle: {
fontWeight: 'normal', //标题颜色
color: '#408829'
},
},
tooltip: {
trigger: 'axis',
axisPointer: {
type: 'shadow'
}
},
legend: {
data: ['浏览量']
},
grid: {
left: '3%',
right: '4%',
bottom: '3%',
containLabel: true
},
xAxis: {
type: 'value',
boundaryGap: [0, 0.01]
},
yAxis: {
type: 'category',
data:json.titleName
},
series: [
{
name: '浏览量',
type: 'bar',
label: {
normal: {
show: true,
position: 'insideRight'
}
},
itemStyle:{ normal:{color:'#f47209'} },
data: json.titleCount
} ]
};
myChart.setOption(option); } function titleSum(data){ var option = {
backgroundColor: '#fbfbfb',//背景色
title: {
text: '新闻话题曝光量【实时】统计',
subtext: '数据来自搜狗实验室'
}, tooltip : {
formatter: "{a} <br/>{b} : {c}%"
},
toolbox: {
feature: {
restore: {},
saveAsImage: {}
}
},
series: [
{
name: '业务指标',
type: 'gauge',
max:50000,
detail: {formatter:'{value}个话题'},
data: [{value: 50, name: '话题曝光量'}]
}
]
}; option.series[0].data[0].value = data;
myChart_sum.setOption(option, true); } </script>
</body>
</html>
把这两个类的代码修改一下
package com.spark.service; import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.HashMap;
import java.util.Map; public class WeblogService { static String url ="jdbc:mysql://bigdata-pro01.kfk.com:3306/test";
static String username="root";
static String password="root"; public Map<String,Object> queryWeblogs() {
Connection conn=null;
PreparedStatement pst=null;
String[] titleNames = new String[20];
String[] titleCounts = new String[20];
Map<String,Object> retMap= new HashMap<String,Object>();
try{
Class.forName("com.mysql.jdbc.Driver");
conn= DriverManager.getConnection(url,username,password);
String query_sql="select titleName,count from webCount where 1=1 order by count desc limit 20";
pst=conn.prepareStatement(query_sql);
ResultSet rs=pst.executeQuery(); int i=0;
while (rs.next()){
String titleName= rs.getString("titleName");
String titleCount= rs.getString("count");
titleNames[i]=titleName;
titleCounts[i]=titleCount;
++i;
}
retMap.put("titleName", titleNames);
retMap.put("titleCount",titleCounts); }catch (Exception e){
e.printStackTrace();
}
return retMap;
} public String[] titleCount() {
Connection conn=null;
PreparedStatement pst=null;
String[] titleSums = new String[1];
Map<String,Object> retMap= new HashMap<String,Object>();
try{
Class.forName("com.mysql.jdbc.Driver");
conn= DriverManager.getConnection(url,username,password);
String query_sql="select count(1) titleSum from webCount ";
pst=conn.prepareStatement(query_sql);
ResultSet rs=pst.executeQuery(); if (rs.next()){
String titleSum= rs.getString("titleSum");
titleSums[0]=titleSum;
}
}catch (Exception e){
e.printStackTrace();
}
return titleSums;
} }
package com.spark.service;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map; import com.alibaba.fastjson.JSON; import javax.websocket.OnClose;
import javax.websocket.OnMessage;
import javax.websocket.OnOpen;
import javax.websocket.Session;
import javax.websocket.server.ServerEndpoint;
@ServerEndpoint("/websocket")
public class WeblogSocket {
WeblogService weblogService = new WeblogService();
@OnMessage
public void onMessage(String message,Session session)
throws Exception {
while (true){
Map<String,Object> map =new HashMap<String, Object>();
map.put("titleName", weblogService.queryWeblogs().get("titleName"));
map.put("titleCount",weblogService.queryWeblogs().get("titleCount"));
map.put("titleCount",weblogService.titleCount());
session.getBasicRemote().
sendText(JSON.toJSONString(map));
Thread.sleep(5000);
map.clear();
}
}
@OnOpen
public void onOpen () {
System.out.println("Client connected");
}
@OnClose
public void onClose () {
System.out.println("Connection closed");
}
}
我们之前的结构化流的处理我们还是跟web分开



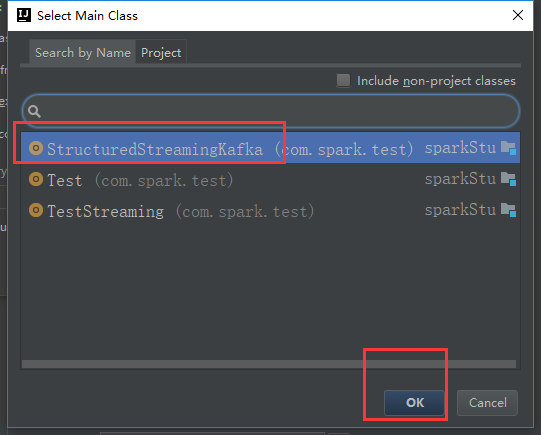
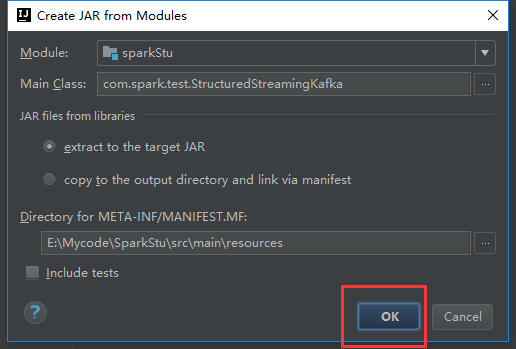

报了这么一个错误,我们就是把那个文件干掉就行了
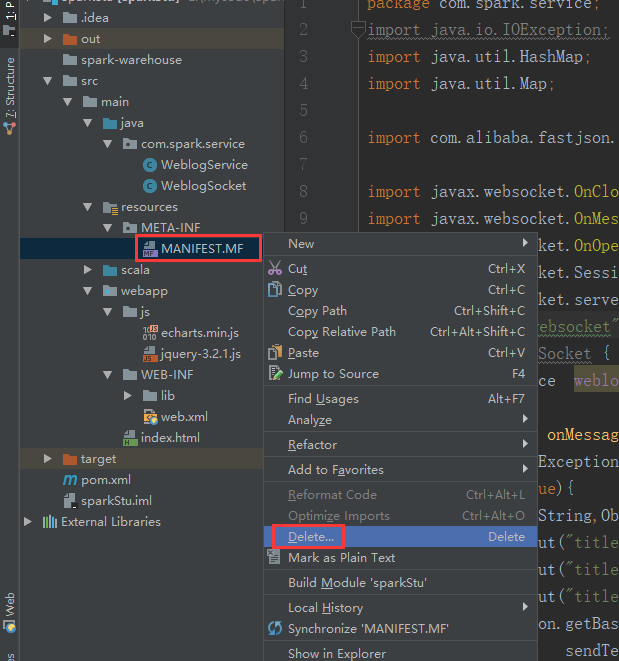
我们再来一次
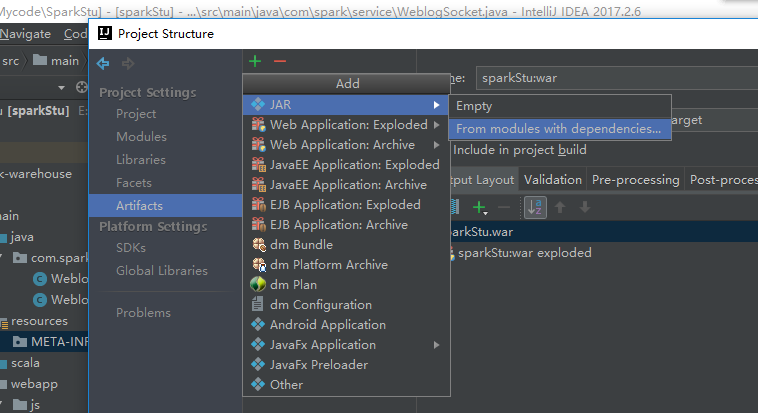
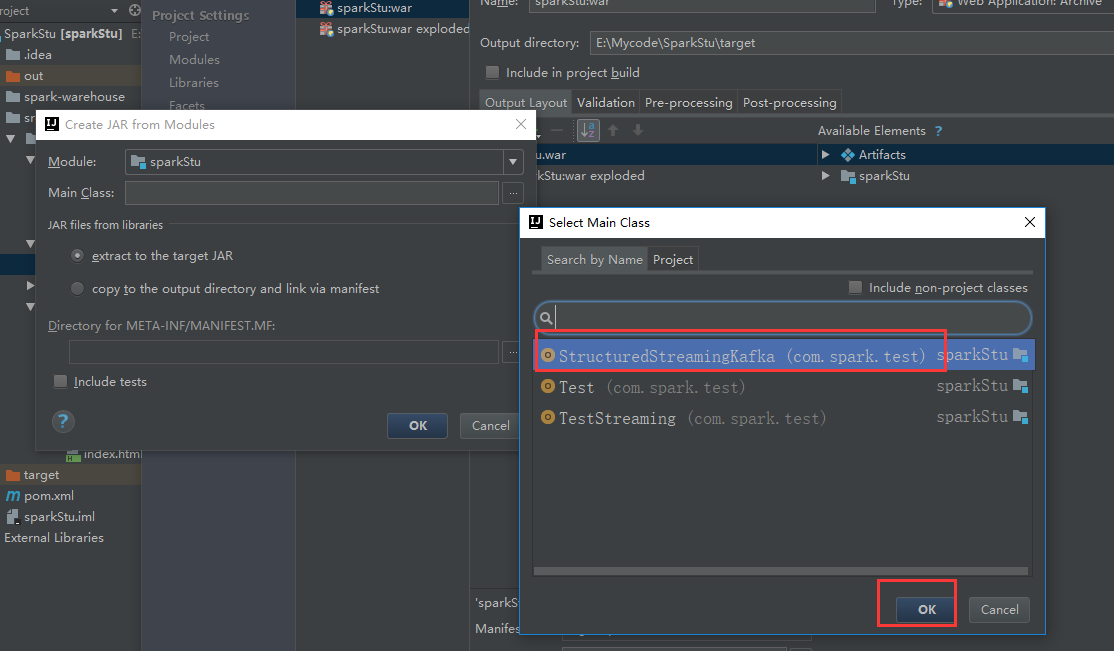
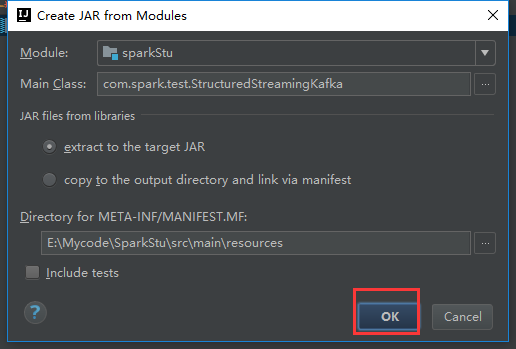
把多余的包剔除掉
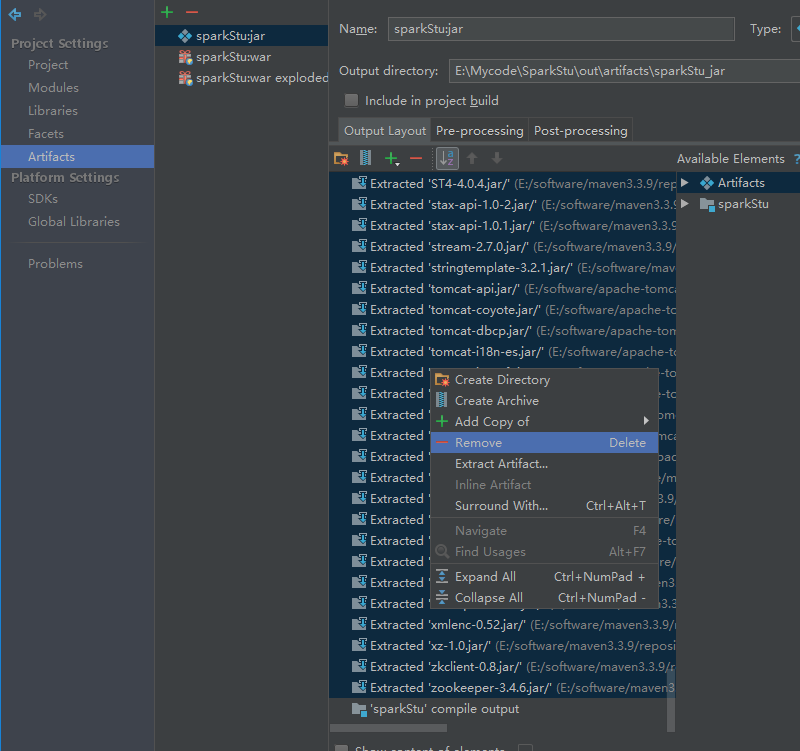
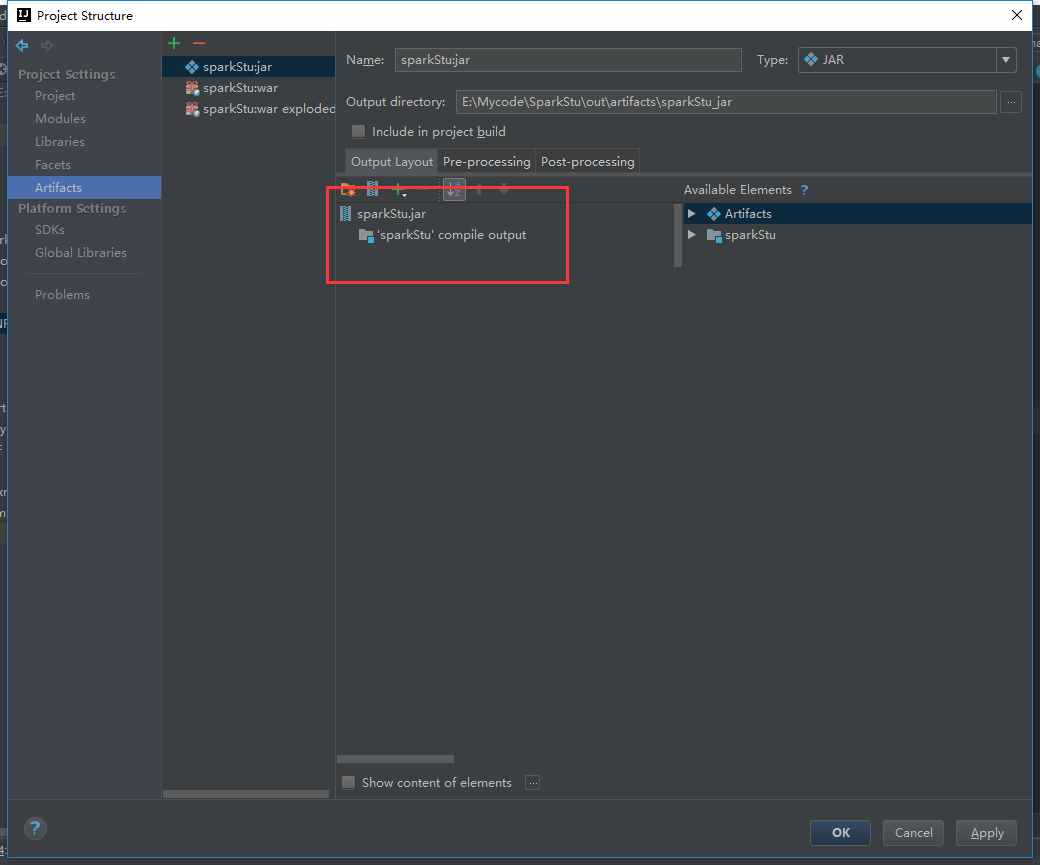
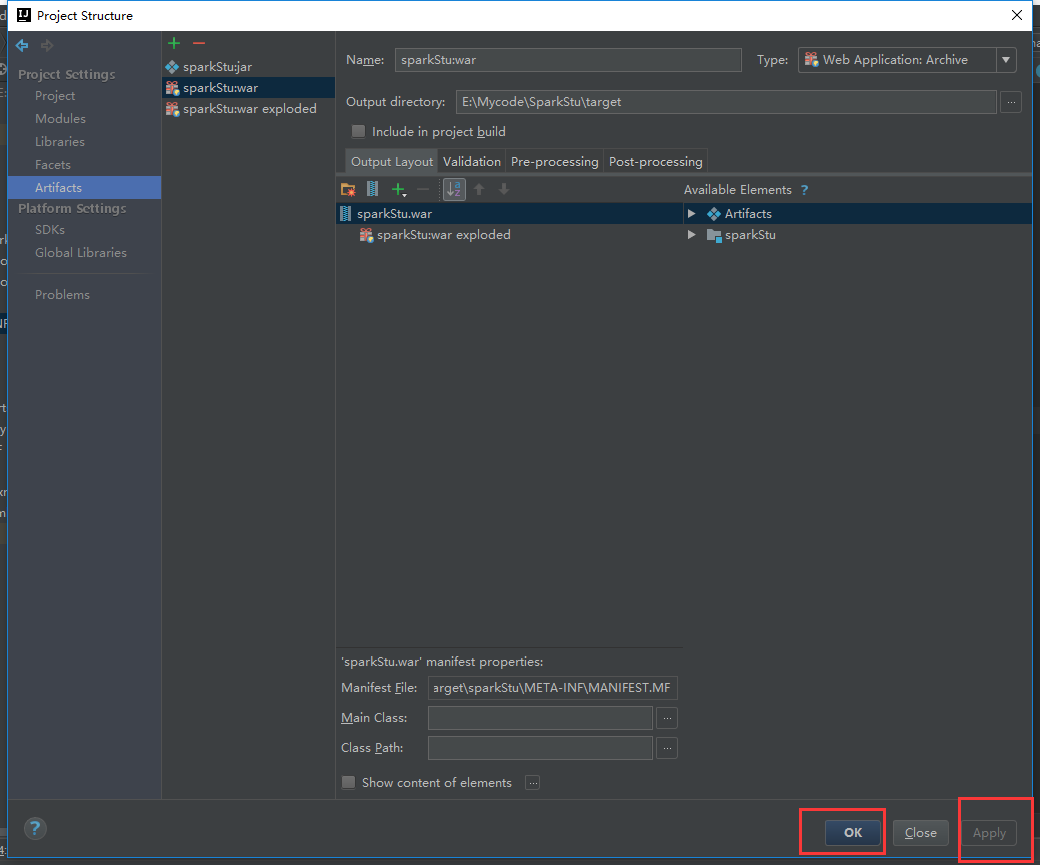

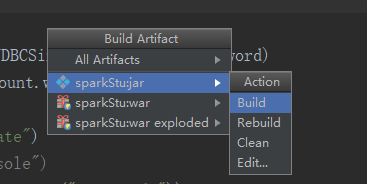
报错了

是因为相同的包冲突的原因
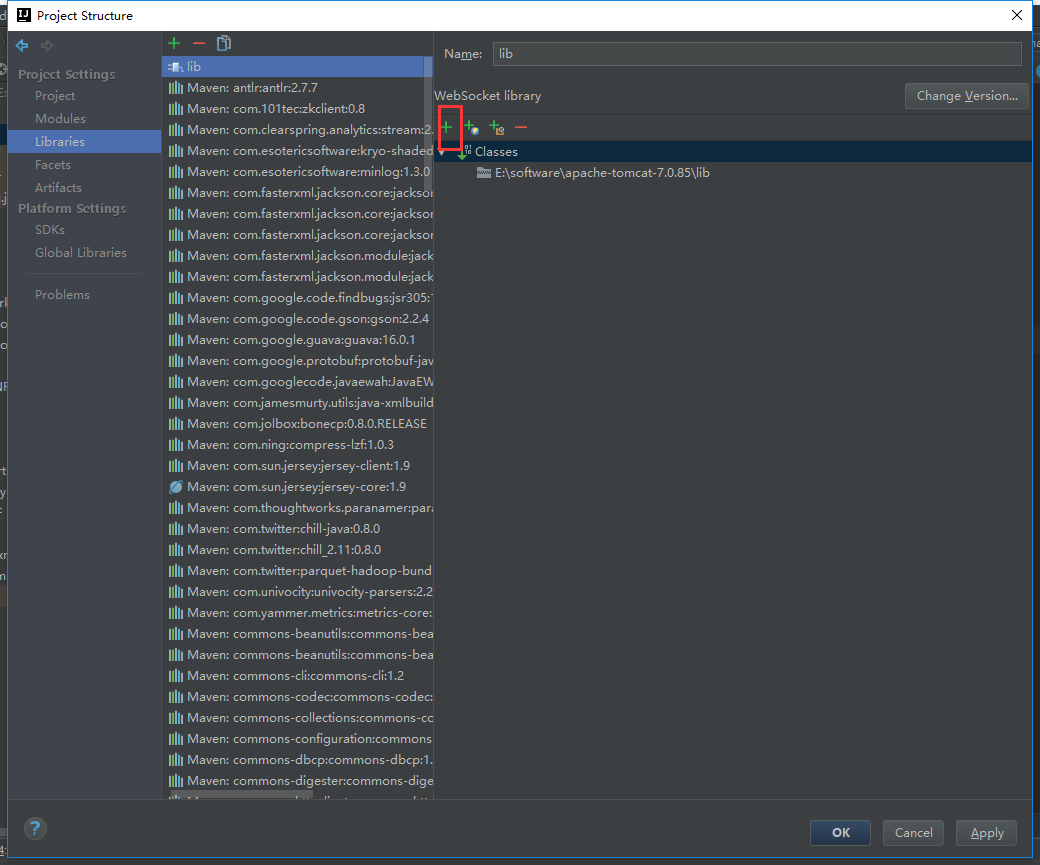
我们就导这些包进来就可以了
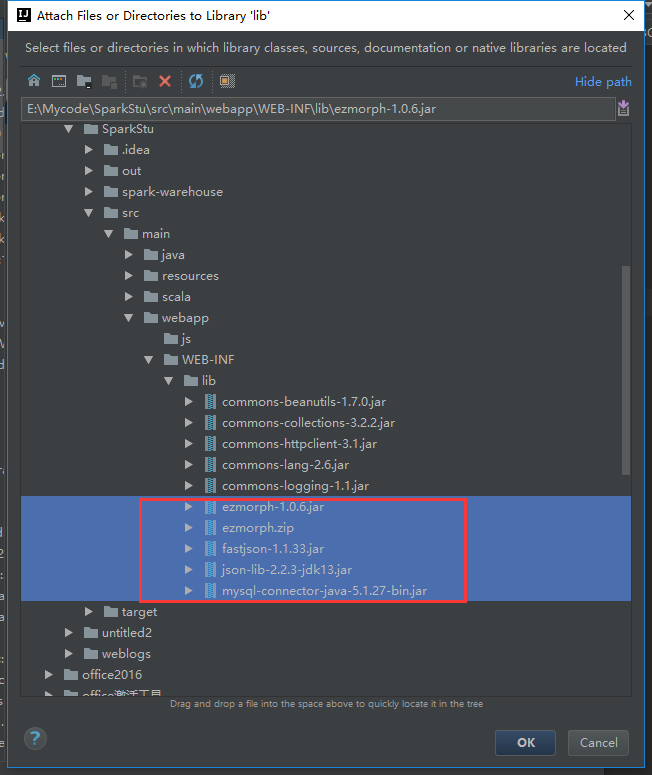
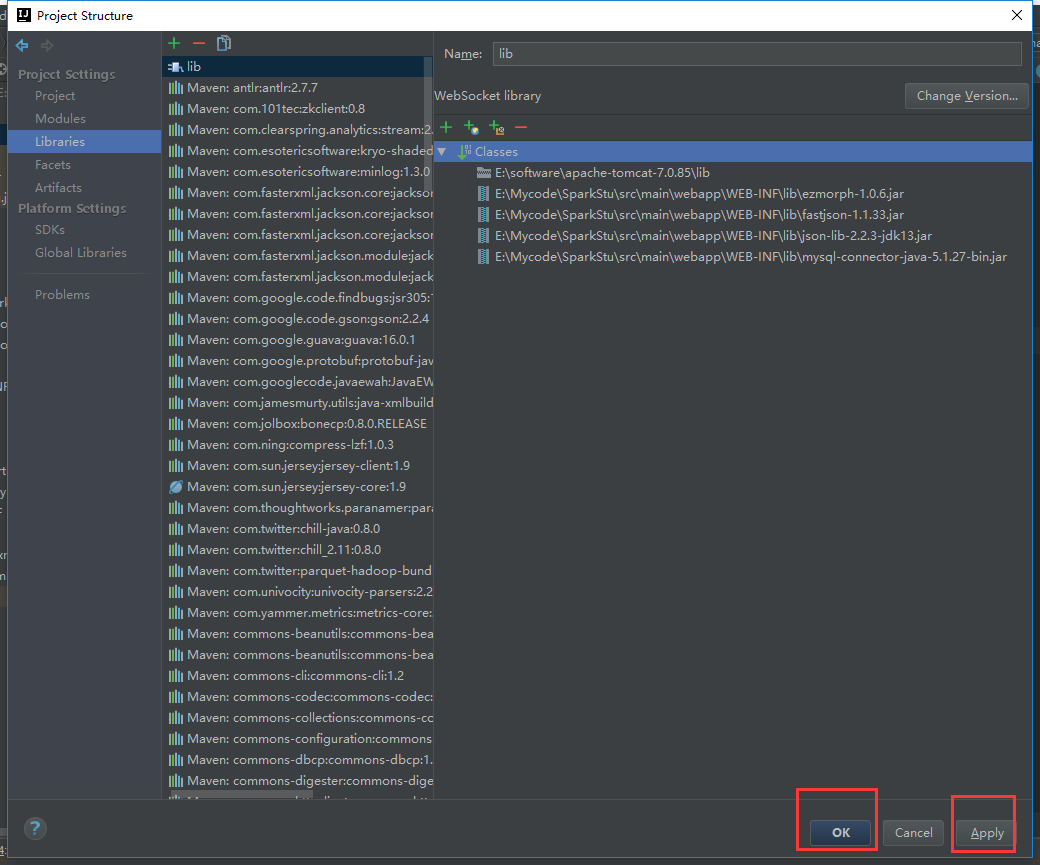
我们再编译一次
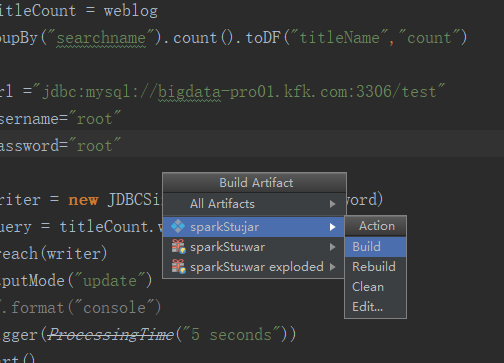

这次编译通过了
把刚刚打的包上传上来

接下来我们重新建一个web工程



从原来的拷贝过去

把js也拷贝过去
把lib包拷贝过去

把index.html文件也拷贝进来到web目录下

我们把web项目的包引进去
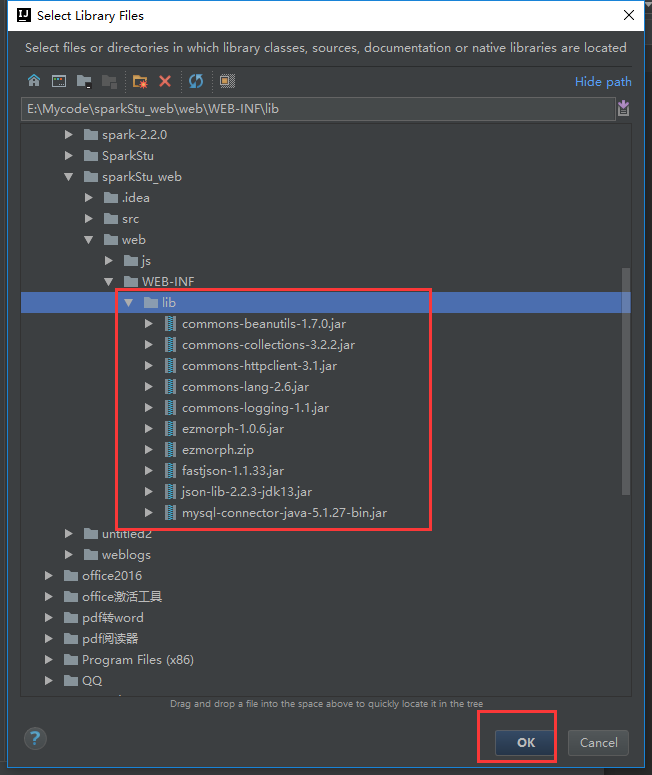


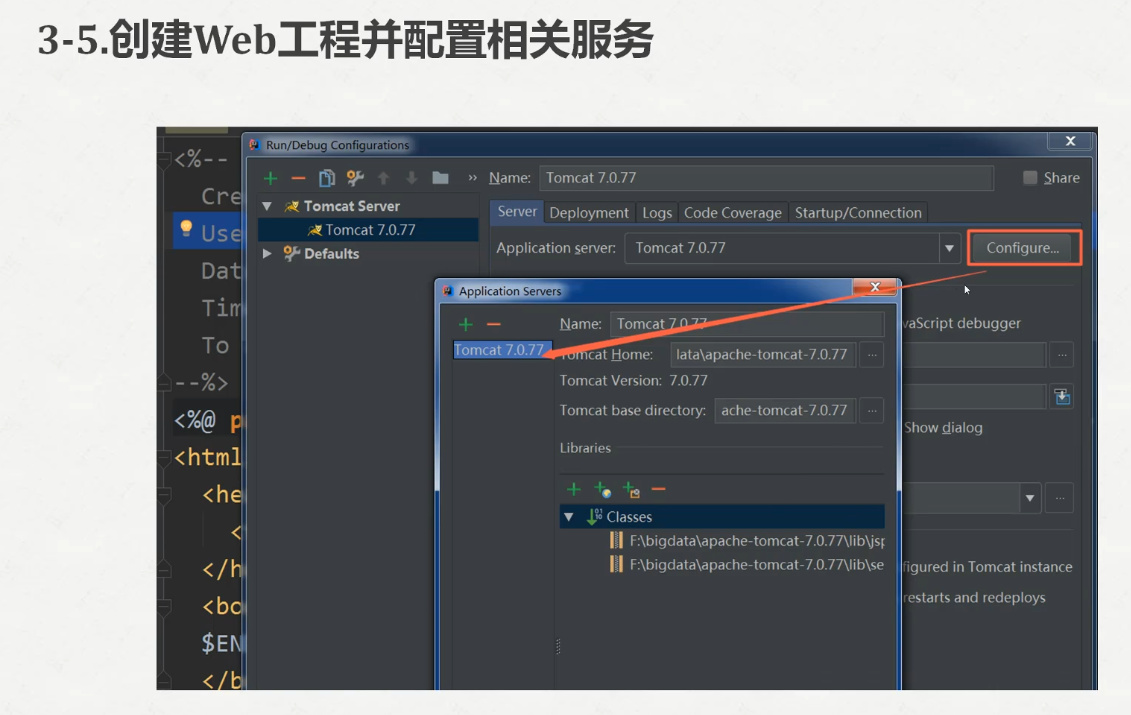
下面配置一下我们的tomcat
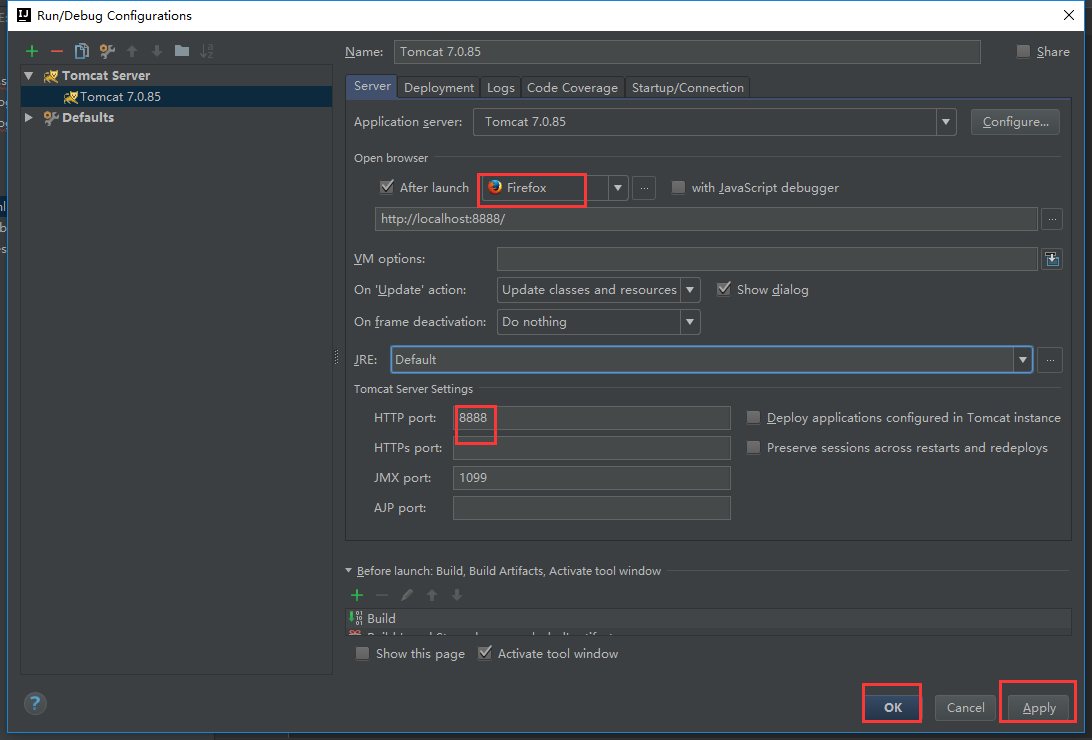
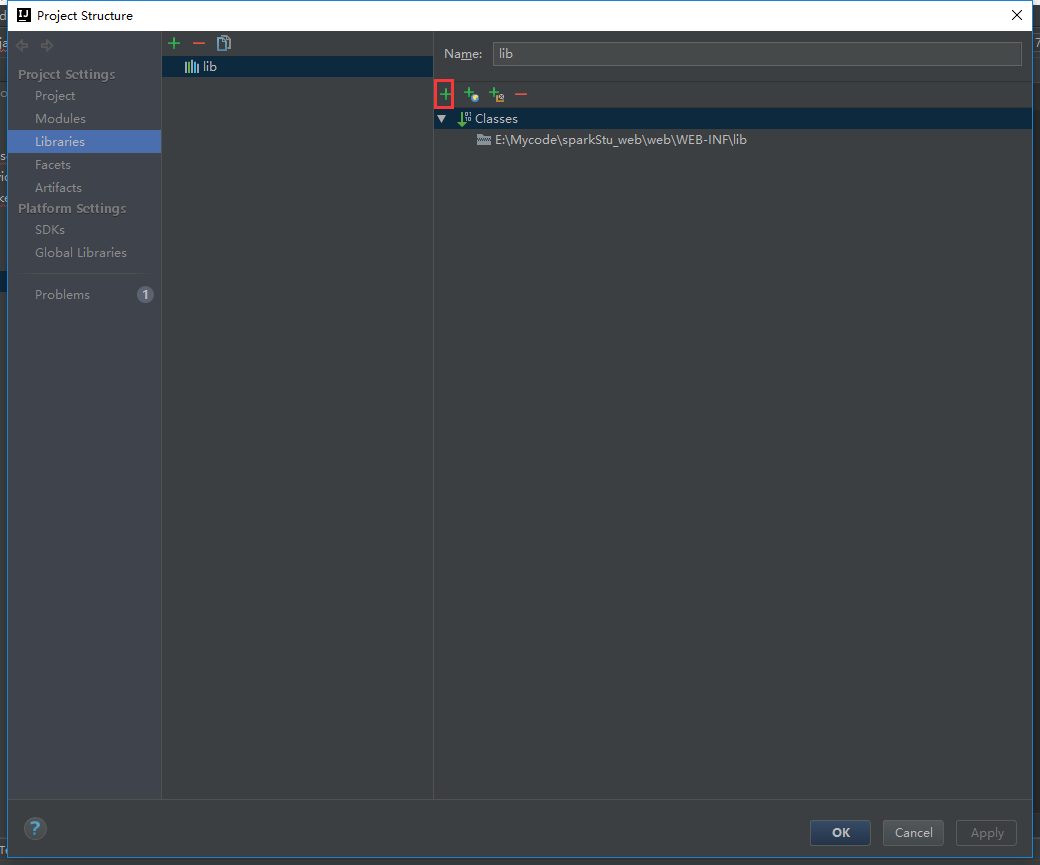
我们还要把tomcat的包加载进来


这样子我们的web项目就没有问题了

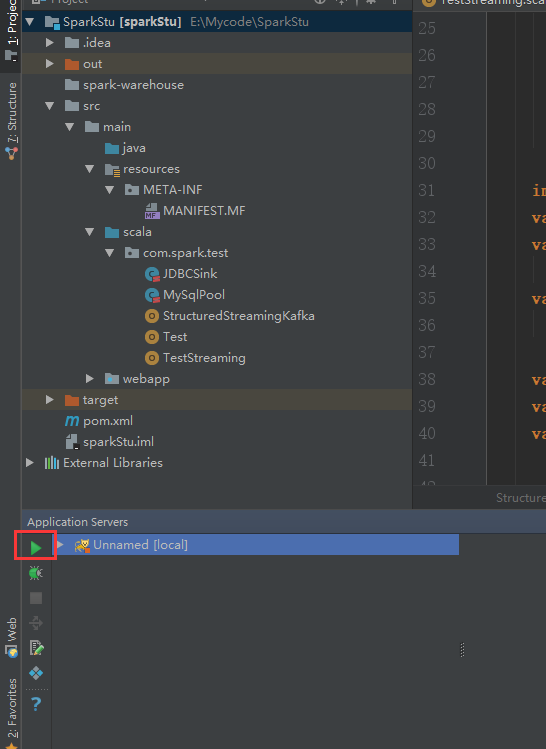
我们启动一下看看服务是否正常的
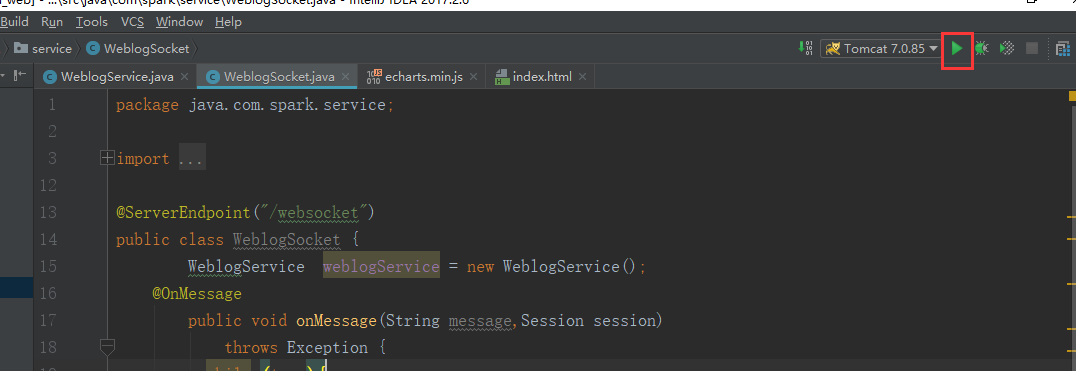
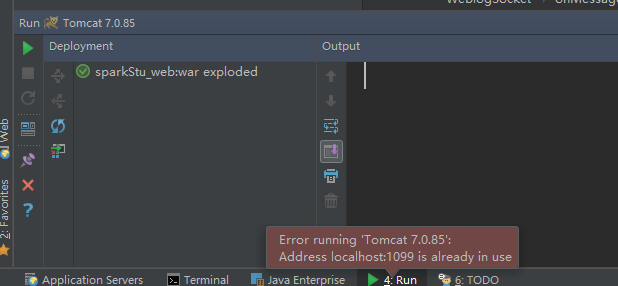
可以看到1099端口已经在使用了,那我们就换个端口1098

这明显不是我们想要的结果,这个界面不是我们的index.html,为了和前面的项目区分开来,我们用的端口号最好不要跟前面的一样

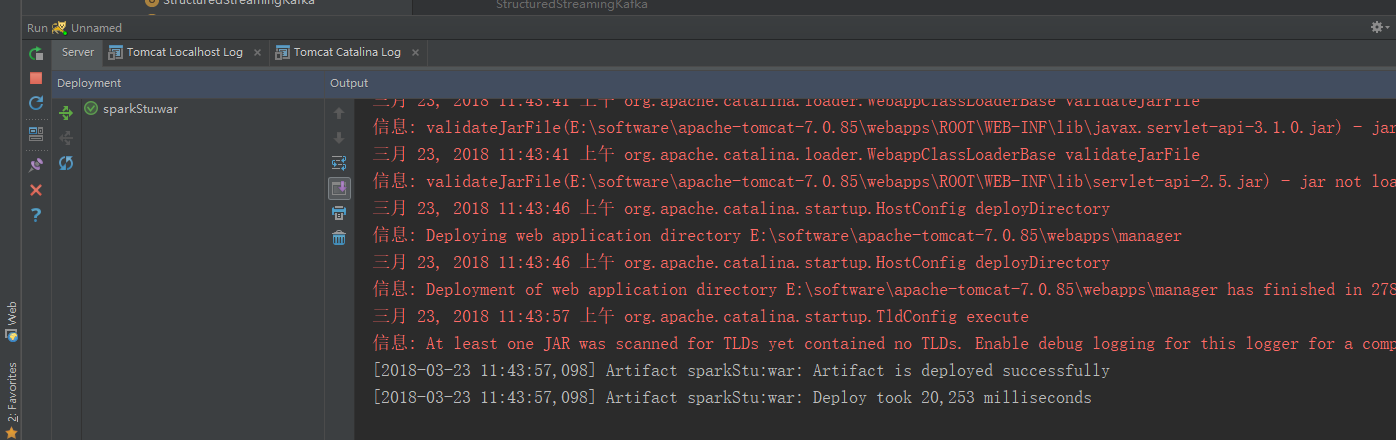
我们再跑一次tomcat

没有报任何错误

这才是我们想要的结果
不过这个经过分析是因为我前面的sparkStu工程还在跑着的原因,我忘记停下来了!
我们按下F12
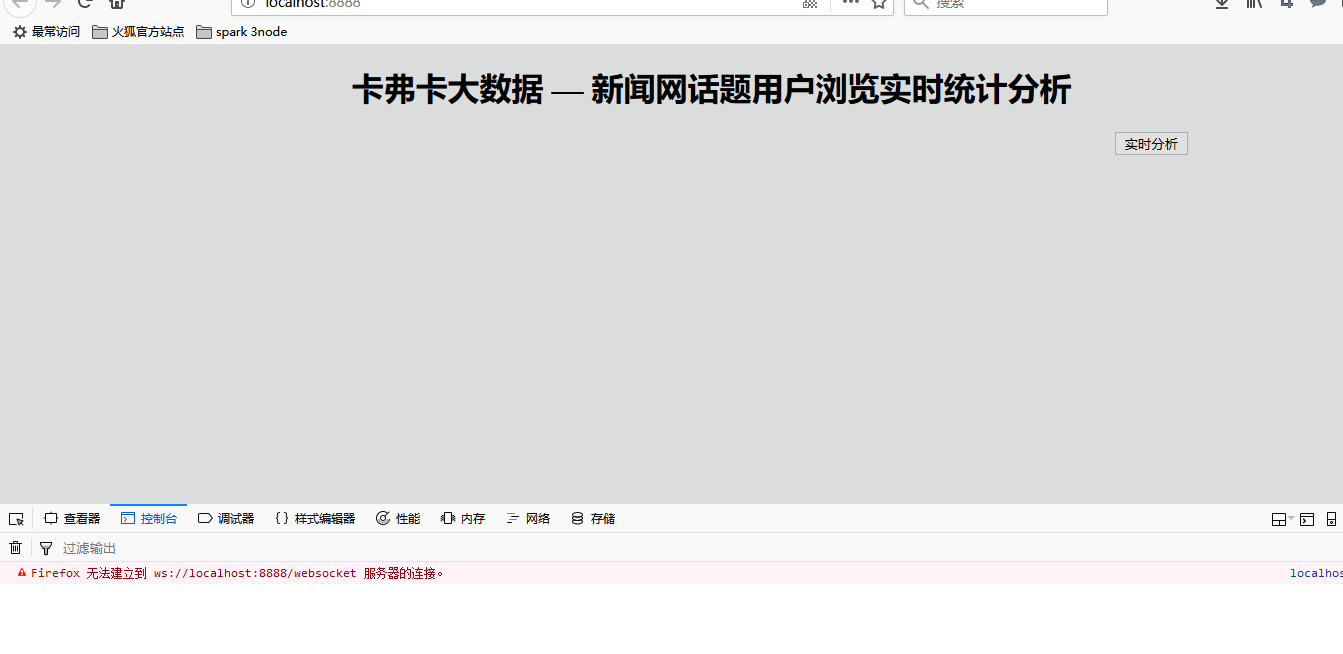
出现错误了
我们的目录有问题
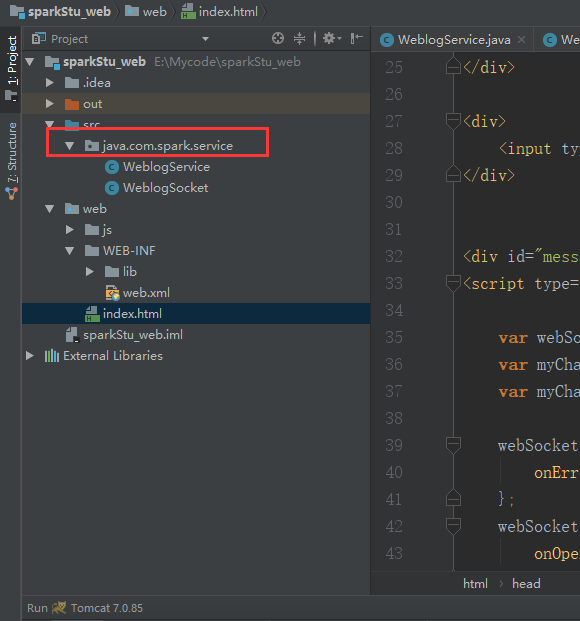
把这个目录激活
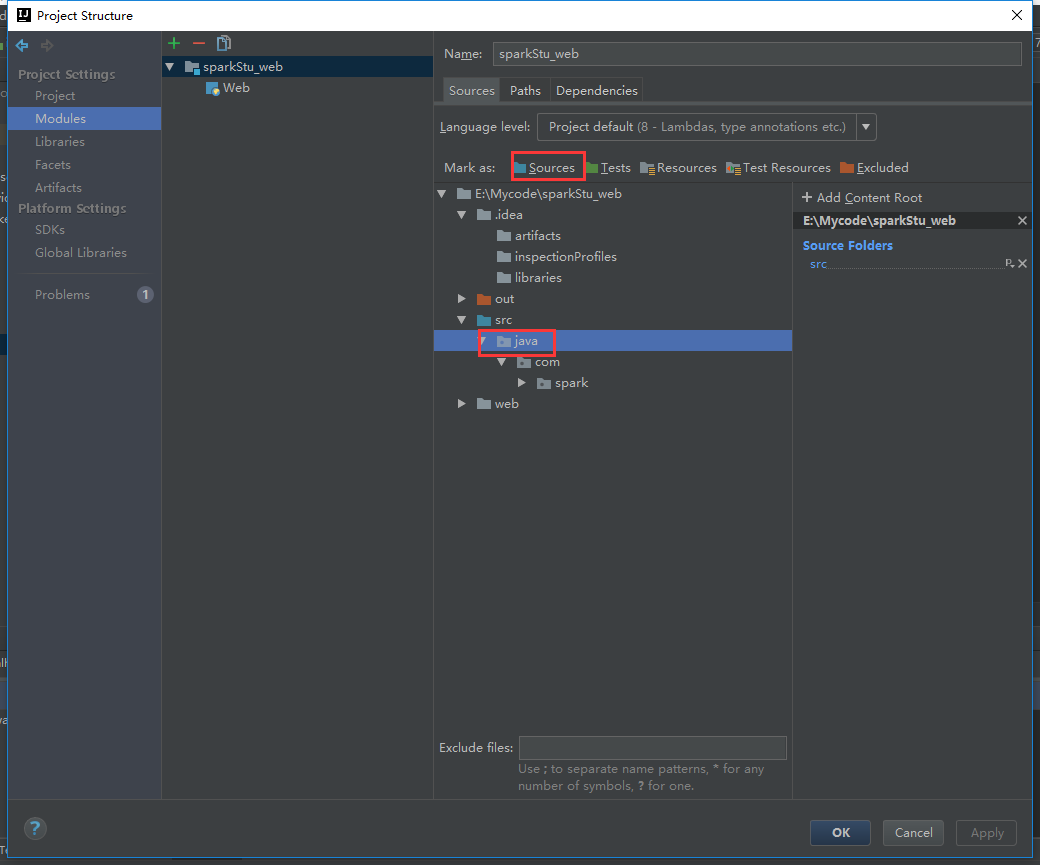
改下这里


改过来就不报错了
把这个工程改成maven工程
这样就把一个普通的工程变成了一个maven工程

添加这个依赖包
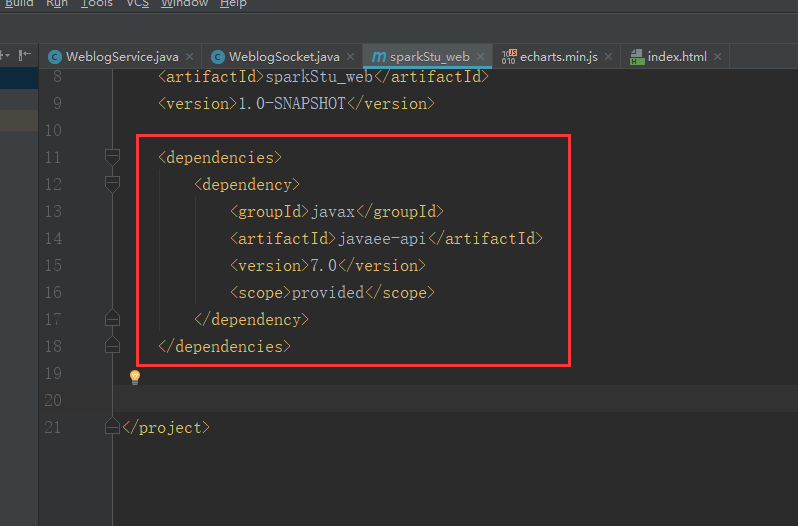
<dependencies>
<dependency>
<groupId>javax</groupId>
<artifactId>javaee-api</artifactId>
<version>7.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
然后我们再rebuid一下
再运行一下tomcat

是没什么问题,但是这个数据真他妈的恶心
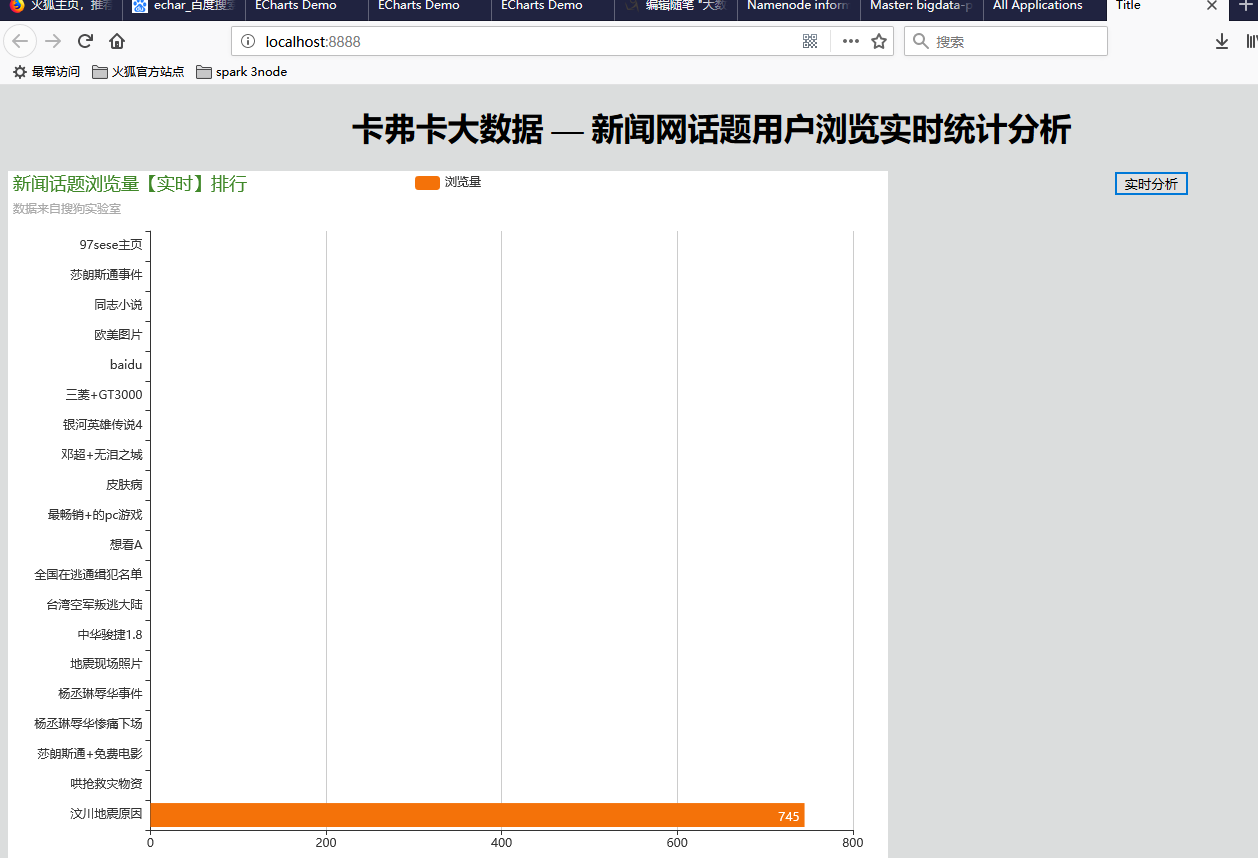
在sparkStu_web工程里面加上这一段
这里把最后修改的代码附上(sparkStu_web工程的)
package com.spark.service; import com.alibaba.fastjson.JSON; import javax.websocket.OnClose;
import javax.websocket.OnMessage;
import javax.websocket.OnOpen;
import javax.websocket.Session;
import javax.websocket.server.ServerEndpoint;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map; @ServerEndpoint("/websocket")
public class WeblogSocket { WeblogService weblogService = new WeblogService();
@OnMessage
public void onMessage(String message, Session session)
throws IOException, InterruptedException {
while(true){
Map<String, Object> map = new HashMap<String, Object>();
map.put("titleName", weblogService.queryWeblogs().get("titleName"));
map.put("titleCount",weblogService.queryWeblogs().get("titleCount"));
map.put("titleSum", weblogService.titleCount()); session.getBasicRemote().
sendText(JSON.toJSONString(map));
Thread.sleep(1000);
map.clear();
}
}
@OnOpen
public void onOpen () {
System.out.println("Client connected");
}
@OnClose
public void onClose () {
System.out.println("Connection closed");
}
}
package com.spark.service; import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.HashMap;
import java.util.Map; /**
* Created by Administrator on 2017/10/17.
*/
public class WeblogService {
static String url ="jdbc:mysql://bigdata-pro01.kfk.com:3306/test";
static String username="root";
static String password="root"; public Map<String,Object> queryWeblogs() {
Connection conn = null;
PreparedStatement pst = null;
String[] titleNames = new String[30];
String[] titleCounts = new String[30];
Map<String,Object> retMap = new HashMap<String, Object>();
try{
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection(url,username,password);
String query_sql = "select titleName,count from webCount where 1=1 order by count desc limit 30";
pst = conn.prepareStatement(query_sql);
ResultSet rs = pst.executeQuery();
int i = 0;
while (rs.next()){
String titleName = rs.getString("titleName");
String titleCount = rs.getString("count");
titleNames[i] = titleName;
titleCounts[i] = titleCount;
++i;
}
retMap.put("titleName", titleNames);
retMap.put("titleCount", titleCounts);
}catch(Exception e){
e.printStackTrace();
}finally{
try {
if (pst != null) {
pst.close();
}
if (conn != null) {
conn.close();
} }catch(Exception e){
e.printStackTrace();
}
}
return retMap;
} public String[] titleCount() {
Connection conn = null;
PreparedStatement pst = null;
String[] titleSums = new String[1];
try{
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection(url,username,password);
String query_sql = "select count(1) titleSum from webCount";
pst = conn.prepareStatement(query_sql);
ResultSet rs = pst.executeQuery();
if(rs.next()){
String titleSum = rs.getString("titleSum");
titleSums[0] = titleSum;
}
}catch(Exception e){
e.printStackTrace();
}finally{
try{
if (pst != null) {
pst.close();
}
if (conn != null) {
conn.close();
}
}catch(Exception e){
e.printStackTrace();
}
}
return titleSums;
} }
启动tomcat
这边的工程我们也启动
让节点2的数据也跑起来这个时候保证kafka,flume等进程的开启,前面已经讲过很多次了

把表中的数据清除
可以看到实时监控是没有数据的

经过漫长的等待
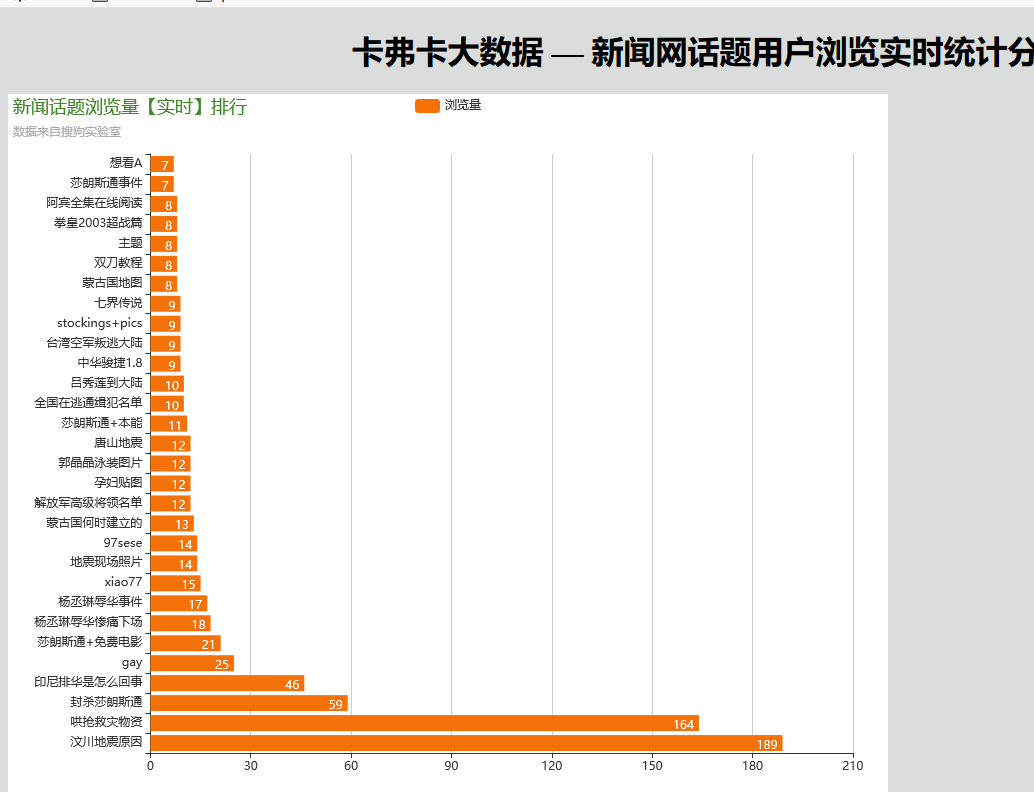
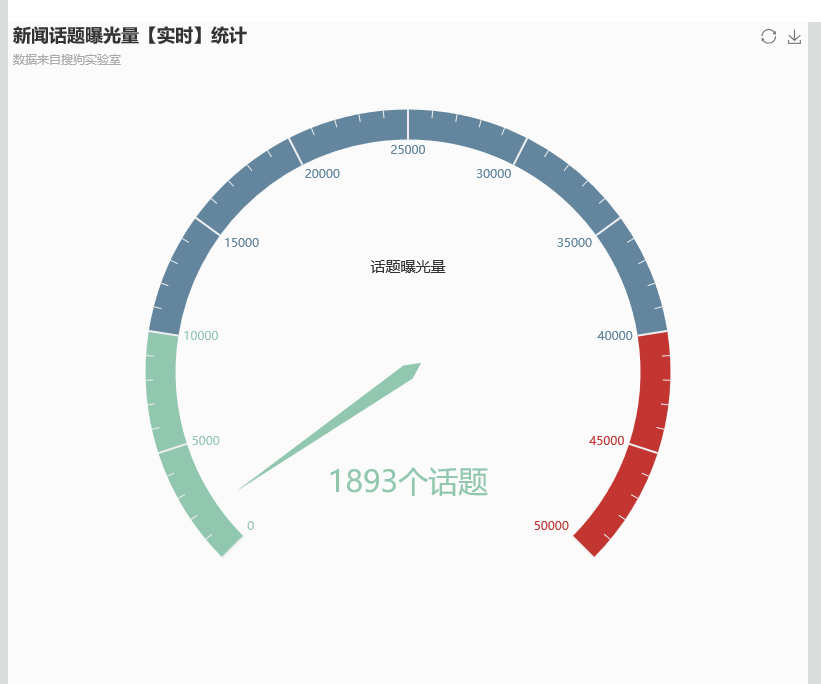
看到实时在监控,数据发生变化

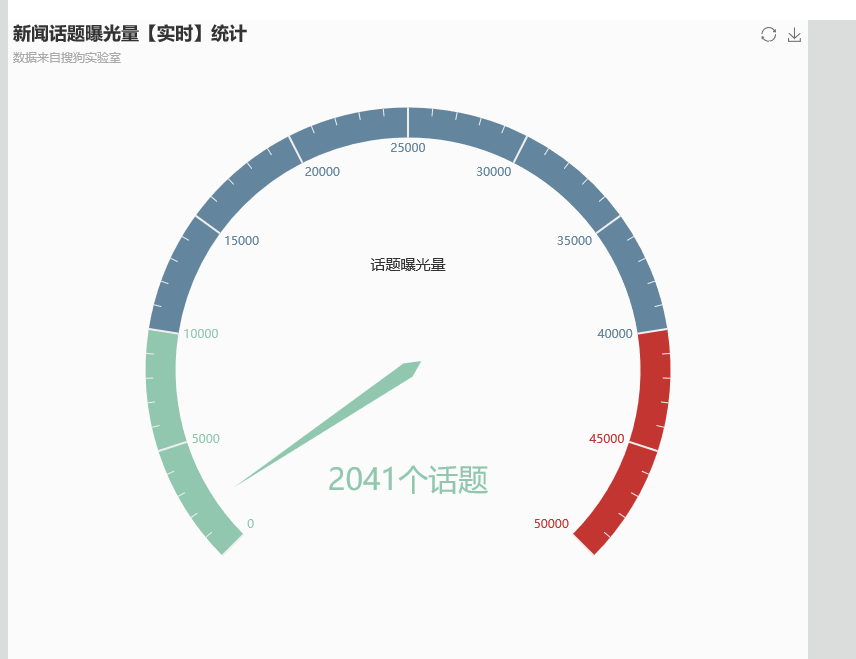
整个项目到现在为止全部结束了,真的好累啊,现在是凌晨3点了,
我真的感到很疲惫了,该回宿舍休息了,实验室的周围是那么安静的!!!!!!
大数据Web可视化分析系统开发的更多相关文章
- 新闻实时分析系统 大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计 2.下载Tomcat并创建Web工程并配置相关服务 下载tomcat,解压并启动tomcat服务. 1)新建web app项目 创建好之后的效果 2)对tomcat进 ...
- 新闻网大数据实时分析可视化系统项目——21、大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计 2.下载Tomcat并创建Web工程并配置相关服务 下载tomcat,解压并启动tomcat服务. 1)新建web app项目 创建好之后的效果 2)对tomcat进 ...
- 学习Hadoop+Spark大数据巨量分析与机器学习整合开发-windows利用虚拟机实现模拟多节点集群构建
记录学习<Hadoop+Spark大数据巨量分析与机器学习整合开发>这本书. 第五章 Hadoop Multi Node Cluster windows利用虚拟机实现模拟多节点集群构建 5 ...
- “基于数据仓库的广东省高速公路一张网过渡期通行数据及异常分析系统"已被《计算机时代》录用
今天收到<计算机时代>编辑部寄来的稿件录用通知,本人撰写的论文"基于数据仓库的广东省高速公路一张网过渡期通行数据及异常分析系统",已被<计算机时代>录 ...
- OneAPM大讲堂 | 监控数据的可视化分析神器 Grafana 的告警实践
文章系国内领先的 ITOM 管理平台供应商 OneAPM 编译呈现. 概览 Grafana 是一个开源的监控数据分析和可视化套件.最常用于对基础设施和应用数据分析的时间序列数据进行可视化分析,也可以用 ...
- 学大数据一定要会Java开发吗?
Java是目前使用广泛的编程语言之一,具有的众多特性,特别适合作为大数据应用的开发语言.Java语言功能强大和简单易用,不仅吸收了C++语言的各种优点还摒弃了C++里难以理解的多继承.指针等概念. J ...
- Impala简介PB级大数据实时查询分析引擎
1.Impala简介 • Cloudera公司推出,提供对HDFS.Hbase数据的高性能.低延迟的交互式SQL查询功能. • 基于Hive使用内存计算,兼顾数据仓库.具有实时.批处理.多并发等优点 ...
- 深入浅出聊Taier—大数据分布式可视化DAG任务调度系统
导读: 上周,袋鼠云数栈全新技术开源规划--DTMO(DTstack Meetup Online)的第一场直播圆满完成.袋鼠云数栈大数据开发专家.Taier项目主导人偷天为大家带来了<Taier ...
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
随机推荐
- this、new,容易混淆的地方
this.new,容易混淆的地方 情况1 关系 情况2 new Foo() 等价于,推荐的写法是new Foo() new Foo new Foo() 不一样 Foo(), Foo()这种情况下,构造 ...
- echarts x轴文字显示不全(xAxis文字倾斜比较全面的3种做法值得推荐)
出处:http://blog.csdn.net/kebi007/article/details/68488694
- python通过xlwt模块直接在网页上生成excel文件并下载
urls: from django.conf.urls import url, include from . import views urlpatterns = [ ... url(r'^domai ...
- WEB开发库收集
1. EASYUI http://www.jeasyui.com/ [INTRODUCTION] jQuery EasyUI framework helps you build yo ...
- Jmeter --- 组件执行顺序与作用域
一.Jmeter重要组件: 1)配置元件---Config Element: 用于初始化默认值和变量,以便后续采样器使用.配置元件大其作用域的初始阶段处理,配置元件仅对其所在的测试树分支有效,如,在同 ...
- VMware Ubuntu如何连接互联网
Brigde——桥接 :默认使用VMnet0 1.原理: Bridge 桥”就是一个主机,这个机器拥有两块网卡,分别处于两个局域网中,同时在”桥”上,运行着程序,让局域网A中的所有数据包原封不动的 ...
- springboot整合shiro-登录认证和权限管理
https://blog.csdn.net/ityouknow/article/details/73836159
- java小程序(课堂作业06)
编写一个程序,此程序在运行时要求用户输入一个 整数,代表某门课的考试成绩,程序接着给出“不及格”.“及格”.“中”.“良”.“优”的结论. 要求程序必须具备足够的健壮性,不管用户输入什 么样的内容,都 ...
- Myeclipse 2017安装
一.下载 Myeclipse官网下载地址:http://www.myeclipsecn.com/download/ 二.安装 安装详细步骤省略,仅仅是一路下一步即可,博主默认安装到了C盘,注意:安装完 ...
- 【剑指offer】两个栈实现队列
用两个栈来实现一个队列,完成队列的Push和Pop操作. 队列中的元素为int类型. public class Solution { Stack<Integer> stack ...