Hadoop系列009-NameNode工作机制
本人微信公众号,欢迎扫码关注!

NameNode工作机制
1 NameNode & SecondaryNameNode工作机制
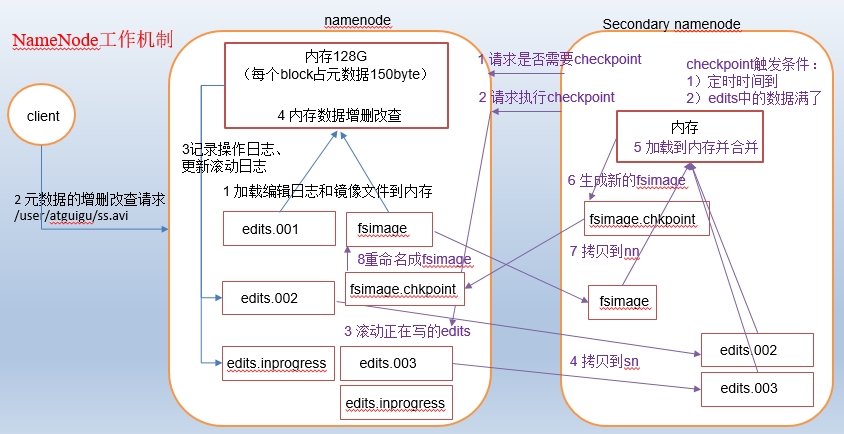
1.1 第一阶段:namenode启动
1)第一次启动namenode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
2)客户端对元数据进行增删改查的请求
3)namenode记录操作日志,更新滚动日志。
4)namenode在内存中对数据进行增删改查
1.2 第二阶段:Secondary NameNode工作
1)Secondary NameNode询问namenode是否需要checkpoint。直接带回namenode是否检查结果。
2)Secondary NameNode请求执行checkpoint。
3)namenode滚动正在写的edits日志
4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode
5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
6)生成新的镜像文件fsimage.chkpoint
7)拷贝fsimage.chkpoint到namenode
8)namenode将fsimage.chkpoint重新命名成fsimage
1.3 参数设置
(1)通常情况下,SecondaryNameNode每隔一小时执行一次。
[hdfs-default.xml]
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
(2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property>
2 NameNode版本号
2.1 查看namenode版本号
在/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current这个目录下查看VERSION
namespaceID=1933630176
clusterID=CID-1f2bf8d1-5ad2-4202-af1c-6713ab381175
cTime=0
storageType=NAME_NODE
blockpoolID=BP-97847618-192.168.10.102-1493726072779
layoutVersion=-63
namenode版本号具体解释
(1)namespaceID在HDFS上,会有多个Namenode,所以不同Namenode的namespaceID是不同的,分别管理一组blockpoolID。
(2)clusterID集群id,全局唯一
(3)cTime属性标记了namenode存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳。
(4)storageType属性说明该存储目录包含的是namenode的数据结构。
(5)blockpoolID:一个block pool id标识一个block pool,并且是跨集群的全局唯一。当一个新的Namespace被创建的时候(format过程的一部分)会创建并持久化一个唯一ID。在创建过程构建全局唯一的BlockPoolID比人为的配置更可靠一些。NN将BlockPoolID持久化到磁盘中,在后续的启动过程中,会再次load并使用。
(6)layoutVersion是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号。
3 镜像文件和编辑日志文件
3.1 概念
3.1.1 Fsimage文件
HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件idnode的序列化信息。
3.1.2 Edits文件
存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到edits文件中。
3.1.3 namenode格式化,具体做什么事
(1)创建fsimage文件,存储fsimage信息
(2)创建edits文件
(3)namenode被格式化之后,将产生如下所示的目录结构

3.2 oiv查看fsimage文件
(1)查看oiv和oev命令
[atguigu@hadoop102 current]$ hdfs
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file
(2)基本语法
hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
(3)案例实操
[atguigu@hadoop102 current]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current
[atguigu@hadoop102 current]$ hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-2.7.2/fsimage.xml
[atguigu@hadoop102 current]$ cat /opt/module/hadoop-2.7.2/fsimage.xml
将显示的xml文件内容拷贝到eclipse中创建的xml文件中,并格式化。
3.3 oev查看fsimage文件
(1)基本语法
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
(2)案例实操
[atguigu@hadoop102 current]$ hdfs oev -p XML -i
edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-2.7.2/edits.xml
[atguigu@hadoop102 current]$ cat /opt/module/hadoop-2.7.2/edits.xml
将显示的xml文件内容拷贝到eclipse中创建的xml文件中,并格式化。
4 滚动编辑日志
正常情况HDFS文件系统有更新操作时,就会滚动编辑日志。也可以用命令强制滚动编辑日志。
1)滚动编辑日志(前提必须启动集群)
hdfs dfsadmin -rollEdits
2)镜像文件什么时候产生
Namenode启动时加载镜像文件和编辑日志
5 SecondaryNameNode目录结构
Secondary NameNode用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
在/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary/current这个目录中查看SecondaryNameNode目录结构。
SecondaryNameNode在previous.checkpoint子目录中备份了主namenode节点中的数据
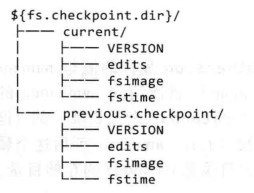
SecondaryNameNode的previous.checkpoint目录、SecondaryNameNode的current目录和主namenode的current目录的布局相同。
好处:在主namenode发生故障时(假设没有及时备份数据),可以从SecondaryNameNode恢复数据。
方法一:将相关存储目录复制到新的namenode中;
方法二:使用-importCheckpoint选项启动namenode守护进程,从而将SecondaryNameNode用作新的主namenode。
6 集群安全模式操作
6.2 概述
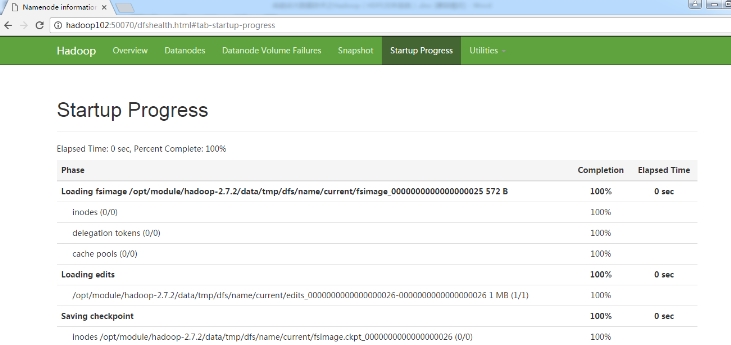
Namenode启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的fsimage文件和一个空的编辑日志。此时,namenode开始监听datanode请求。但是此刻,namenode运行在安全模式,即namenode的文件系统对于客户端来说是只读的。
系统中的数据块的位置并不是由namenode维护的,而是以块列表的形式存储在datanode中。在系统的正常操作期间,namenode会在内存中保留所有块位置的映射信息。在安全模式下,各个datanode会向namenode发送最新的块列表信息,namenode了解到足够多的块位置信息之后,即可高效运行文件系统。
如果满足“最小复本条件”,namenode会在30秒钟之后就退出安全模式。所谓的最小复本条件指的是在整个文件系统中99.9%的块满足最小复本级别(默认值:dfs.replication.min=1)。在启动一个刚刚格式化的HDFS集群时,因为系统中还没有任何块,所以namenode不会进入安全模式。
6.3 基本语法
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
6.3 案例
编辑一个脚本
#!/bin/bash
bin/hdfs dfsadmin -safemode wait
bin/hdfs dfs –put ~/hello.txt /root/hello.txt
Hadoop系列009-NameNode工作机制的更多相关文章
- Hadoop框架:NameNode工作机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.存储机制 1.基础描述 NameNode运行时元数据需要存放在内存中,同时在磁盘中备份元数据的fsImage,当元数据有更新或者添加元数据 ...
- NameNode&Secondary NameNode 工作机制
NameNode&Secondary NameNode 工作机制 NameNode: 1.启动时,加载编辑日志和镜像文件到内存 2.当客户端对元数据进行增删改,请求NameNode 3.Nam ...
- NameNode工作机制
NameNode工作机制
- NameNode && Secondary NameNode工作机制
NameNode && Secondary NameNode工作机制 1)工作流程 2) fsimage和edits NameNode是HDFS的大脑,它维护着整个文件系统的目录树, ...
- HDFS中NameNode和Secondary NameNode工作机制
NameNode工作机制 0)启动概述 Namenode启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作.一旦在内存中成功建立文件系统元数据的映像,则创建一个 ...
- Hadoop框架:DataNode工作机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.工作机制 1.基础描述 DataNode上数据块以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是数据块元数据包括长度.校验.时 ...
- Hadoop_09_HDFS 的 NameNode工作机制
理解NameNode的工作机制尤其是元数据管理机制,以增强对HDFS工作原理的理解,及培养hadoop集群运营中“性能调优” “NameNode”故障问题的分析解决能力 1.NameNode职责: H ...
- hadoop知识点总结(一)hadoop架构以及mapreduce工作机制
1,为什么需要hadoop 数据分析者面临的问题 数据日趋庞大,读写都出现性能瓶颈: 用户的应用和分析结果,对实时性和响应时间要求越来越高: 使用的模型越来越复杂,计算量指数级上升. 期待的解决方案 ...
- HDFS中NameNode工作机制
引言 NameNode: 存储元数据 管理整个HDFS集群 DataNode: 存储数据的block SecondaryNameNode: 辅助HDFS完成一些事情 NameNode和Secondar ...
- Hadoop HDFS NameNode工作机制
Secondary namenode 首先,我们假设如果存储在Namenode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低.因此,元数据需要存放在内存中.但如果只存在内存中 ...
随机推荐
- 解决_CRT_SECURE_NO_WARNINGS警告
VS中: 工程属性->属性->配置属性->C/C++->命令行 在命令行中添加一行: /D _CRT_SECURE_NO_WARNINGS OK!
- JVM学习记录-垃圾收集器
先回顾一下上一篇介绍的JVM中常见几种垃圾收集算法: 标记-清除算法(Mark-Sweep). 复制算法(Copying). 标记整理算法(Mark-Compact). 分代收集算法(Generati ...
- 最新的爬虫工具requests-html
使用Python开发的同学一定听说过Requsts库,它是一个用于发送HTTP请求的测试.如比我们用Python做基于HTTP协议的接口测试,那么一定会首选Requsts,因为它即简单又强大.现在作者 ...
- 下载恒星源码使用vs2015运行配置
需要安装PostgreSQL 配置安装路径下的include 项目 右键→属性 在启动项目项目中配置 右键→属性→展开连接器→输入
- nsq源码阅读笔记之nsqd(四)——Channel
与Channel相关的代码主要位于nsqd/channel.go, nsqd/nsqd.go中. Channel与Topic的关系 Channel是消费者订阅特定Topic的一种抽象.对于发往Topi ...
- docker开机自动重启参数
docker run -ti -d --privileged --restart=always -p : -p : -v /apps/qkaoauth:/apps/qkaoauth docker.qk ...
- BZOJ_3011_[Usaco2012 Dec]Running Away From the Barn _可并堆
BZOJ_3011_[Usaco2012 Dec]Running Away From the Barn _可并堆 Description 给出以1号点为根的一棵有根树,问每个点的子树中与它距离小于l的 ...
- iOS之LLDB常用调试命令
LLDB是个开源的内置于XCode的调试工具,这里来理一理常用用法.lldb对于命令的简称,是头部匹配方式,只要不混淆,你可以随意简称某个命令.结果为在xcode下验证所得,可能与其它平台有所误差. ...
- CISP-PTE注册信息安全专业人员渗透测试工程师知识体系大纲
CISP-PTE注册信息安全专业人员渗透测试工程师知识体系大纲 都是图.. 不足之处,欢迎补充
- java基础 —— properties 使用
目的:分别读取myPro*.properties文件内容,复习一下项目中读取资源配置文件的方法. 项目下载地址:http://pan.baidu.com/s/1jHuzPxs 项目结构如图,ReadP ...