阿狸V任务页面爬取数据解析
需求:
爬取:https://v.taobao.com/v/content/video 所有主播详情页信息
首页分析
分析可以得知数据是通过ajax请求获取的.

分析请求头

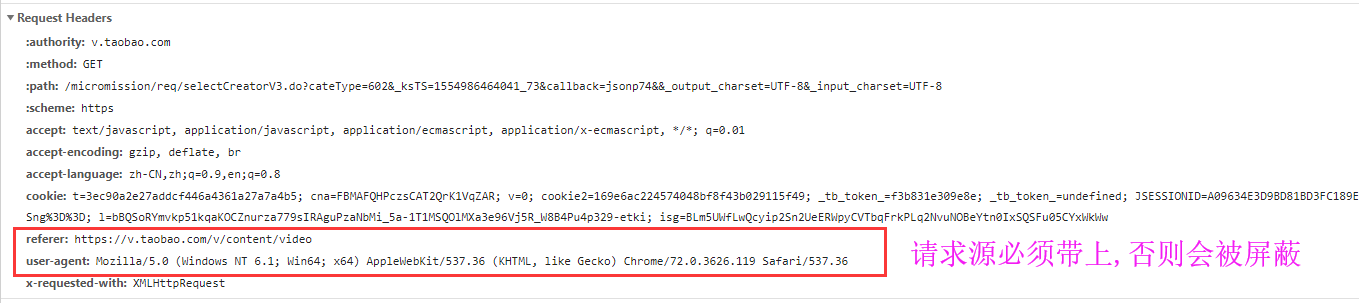
详情页分析
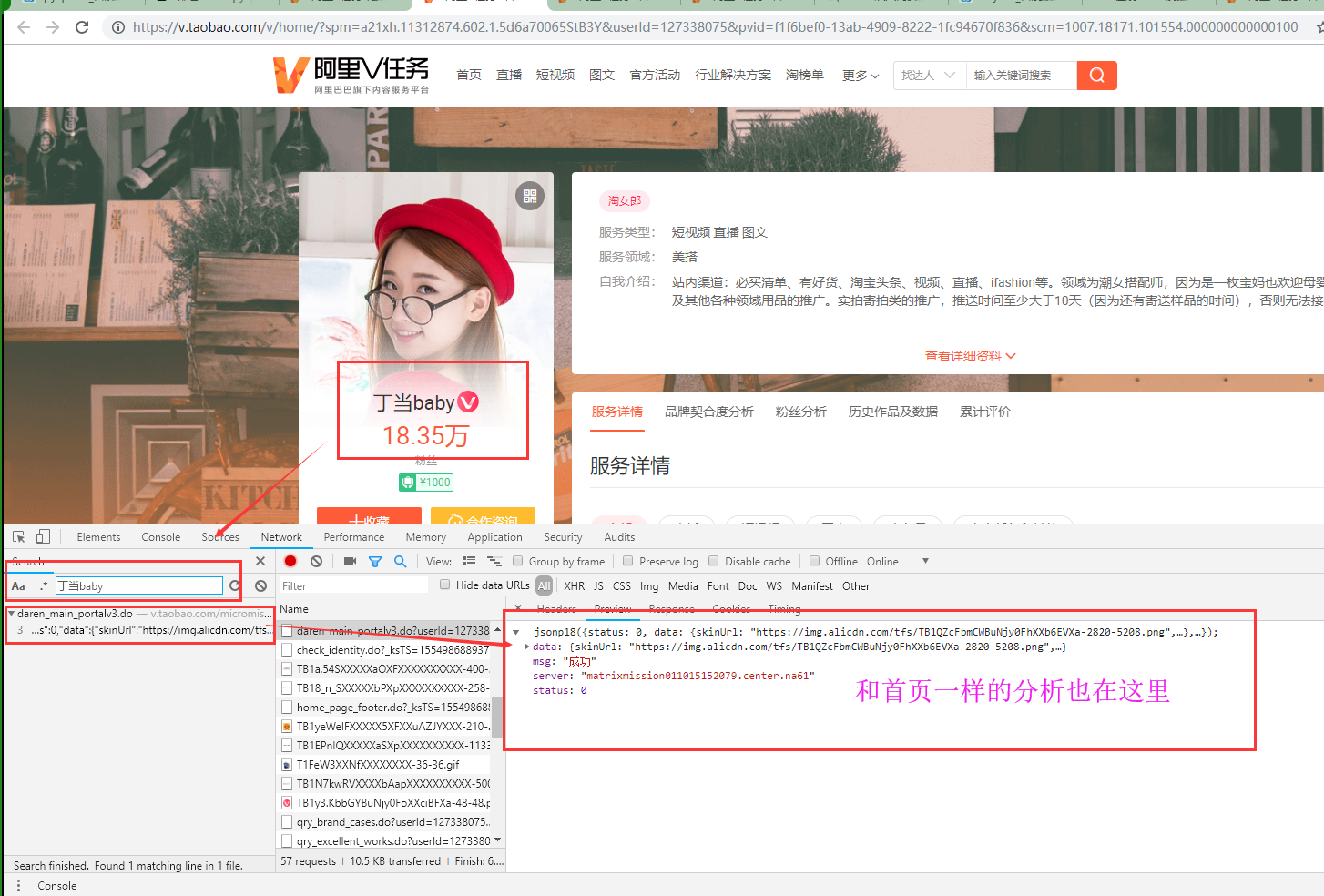
详情页和详情页数据url对比分析

经过测试,发现我们只需要更改'''userid'''的值就可以获取到不同的数据.
分析完毕开始编写代码
完整代码如下
import re
import requests
import json
import jsonpath
import pymongo
class VtaoSpider:
headers={
'referer': 'https://v.taobao.com/v/content/video',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36',
} db=None
def open(self):
'连接数据库'
client=pymongo.MongoClient(host='106.12.108.236',port=27017)
self.db=client['trip'] def get_first_page(self):
'获取首页所有的数据'
url_lst=[]
for i in range(1,26): #25页数据
'处理页面'
params={
'cateType': 602,
'currentPage': i,
'_ksTS': '1554971959356_87',
'':'',
'_output_charset': 'UTF-8',
'_input_charset': 'UTF-8',
}
start_url='https://v.taobao.com/micromission/req/selectCreatorV3.do' first_data=requests.get(url=start_url,headers=self.headers,params=params)
url_lst.append(first_data)
# print(first_data.text)
return url_lst def get_detail_url(self):
'获取详情页的url'
response_list=self.get_first_page()
all_detail_url=[]
for response in response_list:
dd = response.text
d_dict = json.loads(dd)
detail_url = jsonpath.jsonpath(d_dict, '$..homeUrl')
#detail_url是一个列表
all_detail_url.extend(detail_url)
# print(all_detail_url)
return all_detail_url def get_detail_data(self):
url_list=self.get_detail_url()
# print(url_list)
for url in url_list:
try:
ex='userId=(.*?)&'
user_id=re.findall(ex,url)[0]
detail_data_url=f'https://v.taobao.com/micromission/daren/daren_main_portalv3.do?userId={user_id}&_ksTS=1554976401436_17'
# print(detail_data_url) #获取响应数据
data = requests.get(url=detail_data_url, headers=self.headers).text
data_json=json.loads(data)
darenNick=jsonpath.jsonpath(data_json,'$..darenNick')[0]
darenScore=jsonpath.jsonpath(data_json,'$..darenScore')[0]
nick=jsonpath.jsonpath(data_json,'$..nick')[0]
creatorType=jsonpath.jsonpath(data_json,'$..creatorType')[0]
rank=jsonpath.jsonpath(data_json,'$..rank')
res_data={
'darenNick':darenNick,
'darenScore':darenScore,
'nick':nick,
'creatorType':creatorType,
'rank':rank, }
#存入数据库
if self.db['vtaobao'].insert(res_data):
print('save to mongo is successful!') except Exception as e:
print(e) if __name__ == '__main__':
vspider=VtaoSpider()
#数据库启动只需要执行一次
vspider.open()
vspider.get_detail_data()
一共爬取了450条数据,就是450个主播的相关信息!!!
此代码为使用多进程,多线程,爬取时间不能如你们所愿,感兴趣的朋友可以把代码重构一下,使用多进程,多线程,再分享一波,让大家学习一番,谢谢!!!
阿狸V任务页面爬取数据解析的更多相关文章
- Python实训day07pm【Selenium操作网页、爬取数据-下载歌曲】
练习1-爬取歌曲列表 任务:通过两个案例,练习使用Selenium操作网页.爬取数据.使用无头模式,爬取网易云的内容. ''' 任务:通过两个案例,练习使用Selenium操作网页.爬取数据. 使用无 ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- 借助Chrome和插件爬取数据
工具 Chrome浏览器 TamperMonkey ReRes Chrome浏览器 chrome浏览器是目前最受欢迎的浏览器,没有之一,它兼容大部分的w3c标准和ecma标准,对于前端工程师在开发过程 ...
- python3编写网络爬虫14-动态渲染页面爬取
一.动态渲染页面爬取 上节课我们了解了Ajax分析和抓取方式,这其实也是JavaScript动态渲染页面的一种情形,通过直接分析Ajax,借助requests和urllib实现数据爬取 但是javaS ...
- web scraper——简单的爬取数据【二】
web scraper——安装[一] 在上文中我们已经安装好了web scraper现在我们来进行简单的爬取,就来爬取百度的实时热点吧. http://top.baidu.com/buzz?b=1&a ...
- 关于js渲染网页时爬取数据的思路和全过程(附源码)
于js渲染网页时爬取数据的思路 首先可以先去用requests库访问url来测试一下能不能拿到数据,如果能拿到那么就是一个普通的网页,如果出现403类的错误代码可以在requests.get()方法里 ...
- node.js爬取数据并定时发送HTML邮件
node.js是前端程序员不可不学的一个框架,我们可以通过它来爬取数据.发送邮件.存取数据等等.下面我们通过koa2框架简单的只有一个小爬虫并使用定时任务来发送小邮件! 首先我们先来看一下效果图 差不 ...
- 爬虫系列5:scrapy动态页面爬取的另一种思路
前面有篇文章给出了爬取动态页面的一种思路,即应用Selenium+Firefox(参考<scrapy动态页面爬取>).但是selenium需要运行本地浏览器,比较耗时,不太适合大规模网页抓 ...
随机推荐
- SQL Server的Linked Server支持使用SEQUENCE吗?
SQL Server的Linked Server支持使用SEQUENCE吗? SQL Server 2012开始支持序列(SEQUENCE),今天遇到有个同事咨询,能否在LINKED SERVER ...
- mssql sqlserver isnull coalesce函数用法区别说明
摘要: 下文讲述isnull及coalesce空值替换函数的区别 isnull.coalesce函数区别:1.isnull 只能接受两个参数,而coalesce函数可以接受大于等于两个以上参数2.is ...
- ASP.NET Core 中断请求了解一下(翻译)
ASP.NET Core知多少系列:总体介绍及目录 本文所讲方式仅适用于托管在Kestrel Server中的应用.如果托管在IIS和IIS Express上时,ASP.NET Core Module ...
- npm 使用 taobao 的镜像后,无法 login & publish
使用 npm adduser,添加用户之后,没有异常消息,然后使用 npm publish 发布,却报错: 401 原来是 npm 使用 taobao 的镜像后,需要指定 --registry htt ...
- ansible基础-优化
简介 当管理集群达到一定规模时,ansible达到性能瓶颈是难以避免的,此时我们可以通过一定手段提高ansible的执行效率和性能. 笔者虽未管理过超大规模服务器,但也通过查找资料和咨询大神了解了一些 ...
- hadoop rpc协议客户端与服务端的交互流程
尽管这里是hadoop的rpc服务,但是hadoop还是做到了一次连接仅有一次认证.具体的流程待我慢慢道来. 客户端:这里我们假设ConnectionId对应的Connection并不存在.在调用ge ...
- 【深度学习篇】--神经网络中的池化层和CNN架构模型
一.前述 本文讲述池化层和经典神经网络中的架构模型. 二.池化Pooling 1.目标 降采样subsample,shrink(浓缩),减少计算负荷,减少内存使用,参数数量减少(也可防止过拟合)减少输 ...
- Android APP应用启动页白屏(StartingWindow)优化
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 StartingWindow 的处理方式: 使用系统默认的 StartingWindow :用户点了应用图标启动应用,马上弹出系统默 ...
- 值得一看的35个Redis常用问题总结
1.什么是redis? Redis 是一个基于内存的高性能key-value数据库. 2.Reids的特点 Redis本质上是一个Key-Value类型的内存数据库,很像memcached,整个数据库 ...
- Docker进阶之四:镜像管理
一.什么是镜像? 简单说,Docker镜像是一个不包含Linux内核而又精简的Linux操作系统. 二.镜像从哪里来? Docker Hub是由Docker公司负责维护的公共注册中心,包含大量的容 ...