Scrapy爬虫框架补充内容一(Linux环境)
Scrapy爬虫框架结构及工作原理详解
scrapy框架的框架结构如下:
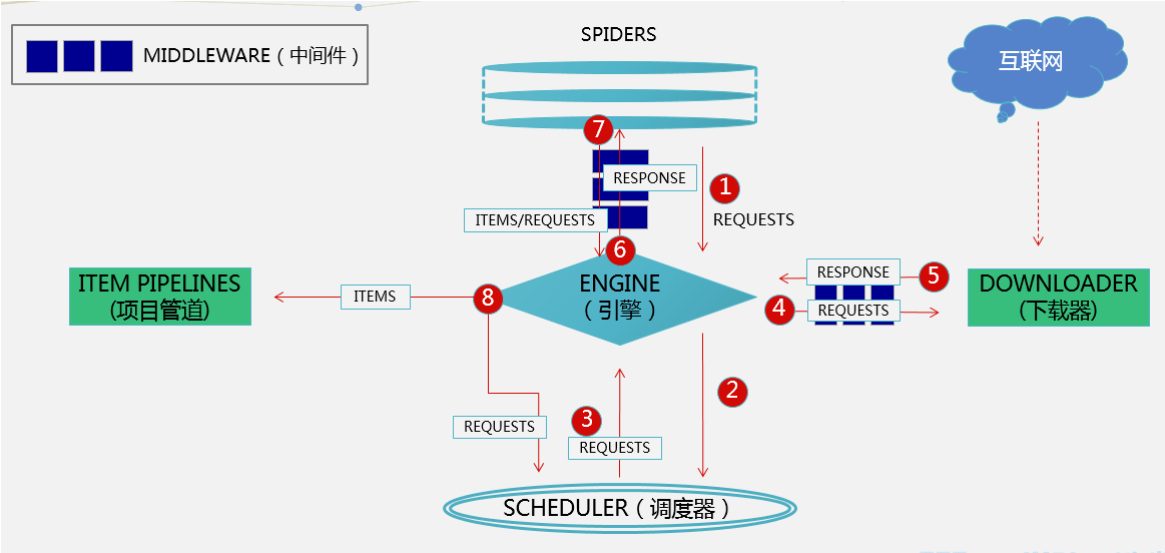
组件分析:
ENGINE:(核心):处理整个框架的数据流,各个组件在其控制下协同工作
SCHEDULER(调度器):负责接收引擎发送来的请求,并压入队列,在引擎再次请求时返回
SPIDER(蜘蛛):负责从网页中提取指定的信息,即item并产生对新页面的下载请求
DOWNLOADER(下载器):用于下载网页内容(即发送HTTP请求/接受HTTP请求)并将内容返回给ENGINE
ITEM PIPELINES(项目管道):主要对爬取到的数据进行处理(去重、过滤、清洗),最终保存数据
DOWNLOADER MIDDLEWARES(下载中间件):位于ENGINE和DOWNLOADER中间,处理请求和响应(该组件是反反爬虫的重点)
SPIDER MIDDLEWARES(爬虫中间件):位于SPIDER和ENGINE中间,处理蜘蛛的请求和响应
数据流对象分析:(主要有三)
(1)REQUEST:scrapy中的hettp请求对象
(2)RESPONSE:scrapy中的http响应对象
(3)ITEM:页面爬取到的数据
工作原理:
(1)、Spiders发送第一个URL给引擎
(2)、引擎从Spider中获取到第一个要爬取的URL后,在调度器(Scheduler)以Request调度
(3)、调度器把需要爬取的request返回给引擎
(4)、引擎将request通过下载中间件发给下载器(Downloader)去互联网下载数据
(5)、一旦数据下载完毕,下载器获取由互联网服务器发回来的Response,并将其通过下载中间件发送给引擎
(6)、引擎从下载器中接收到Response并通过Spider中间件发送给Spider处理
(7)、Spider处理Response并从中返回匹配到的Item及(跟进的)新的Request给引擎
(8)、引擎将(Spider返回的)爬取到的Item给Item Pipeline做数据处理或者入库保存,将(Spider返回的)Request给调度器入队列
(9)、重复第(3)步循环运行直至SCHCULAR中没有REQUEST为止
总结:这章我们学习了整个scrapy框架的结构及工作原理,小伙伴们清楚了吗?(刚全宿舍去看了复联3,突然发现灭霸并没有那么坏!雷神真tm叼!)

Scrapy爬虫框架补充内容一(Linux环境)的更多相关文章
- Scrapy爬虫框架第三讲(linux环境)
下面我们来学习下Spider的具体使用: 我们已上节的百度阅读爬虫为例来进行分析: 1 # -*- coding: utf-8 -*- 2 import scrapy 3 from scrapy.li ...
- Scrapy爬虫框架第五讲(linux环境)【download middleware用法】
DOWNLOAD MIDDLEWRE用法详解 通过上面的Scrapy工作架构我们对其功能进行下总结: (1).在Scheduler调度出队列时的Request送给downloader下载前对其进行修改 ...
- Scrapy爬虫框架第四讲(Linux环境)
下面我们来学习Selector的具体使用:(参考文档:http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/selectors.html) Selecto ...
- Scrapy爬虫框架补充内容三(代理及其基本原理介绍)
前言:(本文参考维基百科及百度百科所写) 当我们使用爬虫抓取数据时,有时会产生错误比如:突然跳出来了403 Forbidden 或者网页上出现以下提示:您的ip访问频率太高 或者时不时跳出一个验证码需 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
随机推荐
- 9.2.2、Libgdx的输入处理之事件处理
(官网:www.libgdx.cn) 事件处理可以更加准确的获取用户的输入.事件处理提供了一种可以通过用户接口进行交互的方法.比如按下.释放一个按钮. 输入处理 事件处理通过观察者模式来完成.首先,需 ...
- iOS开发经验相关知识
一. iPhone Size 手机型号 屏幕尺寸 iPhone 4 4s 320 * 480 iPhone 5 5s 320 * 568 iPhone 6 6s 375 * 667 iphone 6 ...
- HibernateTemplate 查询原生sql及ljava.lang.object cannot be cast to
/** * 使用sql语句进行查询操作 * @param sql * @return */ public List queryWithSql(final String sql){ List list ...
- 【面试笔试算法】Program 2:Amusing Digits(网易游戏笔试题)
时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 网易成立于1997年6月,是中国领先的互联网技术公司.其相继推出了门户网站.在线游戏.电子邮箱.在线教育.电子商务等多种服 ...
- iOS监听模式系列之NSNotificationCenter的简单使用
NSNotificationCenter 对于这个没必要多说,就是一个消息通知机制,类似广播.观察者只需要向消息中心注册感兴趣的东西,当有地方发出这个消息的时候,通知中心会发送给注册这个消息的对象.这 ...
- obj-c中SEL签名和Invocation示例
参考小示例,代码如下: #import <Foundation/Foundation.h> @interface PlayList:NSObject @property NSMutable ...
- 关于linux内核驱动开发中Makefile编译的问题
obj-y:打个比方,我要编译的是hello.c这个文件,obj-y就会把hello.c或者hello.c编译生成的hello.s文件链接到内核中去. obj-m:打个比方,我要编译的是hello.c ...
- 使用kubeadm搭建Kubernetes(1.10.2)集群(国内环境)
目录 目标 准备 主机 软件 步骤 (1/4)安装 kubeadm, kubelet and kubectl (2/4)初始化master节点 (3/4) 安装网络插件 (4/4)加入其他节点 (可选 ...
- Android studio 项目(Project)依赖(非Module)
Android studio 项目(Project)依赖(非Module) 0. 前言 对于Module 级别的依赖大家都知道,今天说下Android Studio下的项目依赖. 场景: A Proj ...
- 基于 Java Web 的毕业设计选题管理平台--选题报告与需求规格说明书
一.选题报告 目录 团队名称 团队成员 项目名称 项目描述 创新与收益 用户场景分析 真实用户调研 未来市场与竞争 项目导图 比例权重 总结 1.团队名称--指南者团队 2.团队成员 孔潭活:2015 ...