Scrapy爬虫框架补充内容一(Linux环境)
Scrapy爬虫框架结构及工作原理详解
scrapy框架的框架结构如下:
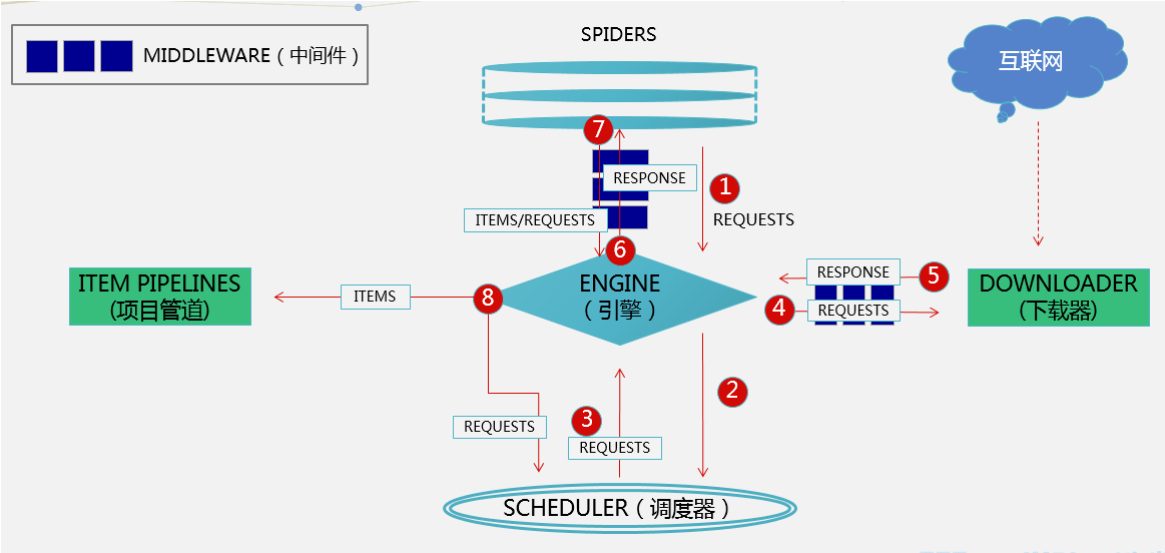
组件分析:
ENGINE:(核心):处理整个框架的数据流,各个组件在其控制下协同工作
SCHEDULER(调度器):负责接收引擎发送来的请求,并压入队列,在引擎再次请求时返回
SPIDER(蜘蛛):负责从网页中提取指定的信息,即item并产生对新页面的下载请求
DOWNLOADER(下载器):用于下载网页内容(即发送HTTP请求/接受HTTP请求)并将内容返回给ENGINE
ITEM PIPELINES(项目管道):主要对爬取到的数据进行处理(去重、过滤、清洗),最终保存数据
DOWNLOADER MIDDLEWARES(下载中间件):位于ENGINE和DOWNLOADER中间,处理请求和响应(该组件是反反爬虫的重点)
SPIDER MIDDLEWARES(爬虫中间件):位于SPIDER和ENGINE中间,处理蜘蛛的请求和响应
数据流对象分析:(主要有三)
(1)REQUEST:scrapy中的hettp请求对象
(2)RESPONSE:scrapy中的http响应对象
(3)ITEM:页面爬取到的数据
工作原理:
(1)、Spiders发送第一个URL给引擎
(2)、引擎从Spider中获取到第一个要爬取的URL后,在调度器(Scheduler)以Request调度
(3)、调度器把需要爬取的request返回给引擎
(4)、引擎将request通过下载中间件发给下载器(Downloader)去互联网下载数据
(5)、一旦数据下载完毕,下载器获取由互联网服务器发回来的Response,并将其通过下载中间件发送给引擎
(6)、引擎从下载器中接收到Response并通过Spider中间件发送给Spider处理
(7)、Spider处理Response并从中返回匹配到的Item及(跟进的)新的Request给引擎
(8)、引擎将(Spider返回的)爬取到的Item给Item Pipeline做数据处理或者入库保存,将(Spider返回的)Request给调度器入队列
(9)、重复第(3)步循环运行直至SCHCULAR中没有REQUEST为止
总结:这章我们学习了整个scrapy框架的结构及工作原理,小伙伴们清楚了吗?(刚全宿舍去看了复联3,突然发现灭霸并没有那么坏!雷神真tm叼!)

Scrapy爬虫框架补充内容一(Linux环境)的更多相关文章
- Scrapy爬虫框架第三讲(linux环境)
下面我们来学习下Spider的具体使用: 我们已上节的百度阅读爬虫为例来进行分析: 1 # -*- coding: utf-8 -*- 2 import scrapy 3 from scrapy.li ...
- Scrapy爬虫框架第五讲(linux环境)【download middleware用法】
DOWNLOAD MIDDLEWRE用法详解 通过上面的Scrapy工作架构我们对其功能进行下总结: (1).在Scheduler调度出队列时的Request送给downloader下载前对其进行修改 ...
- Scrapy爬虫框架第四讲(Linux环境)
下面我们来学习Selector的具体使用:(参考文档:http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/selectors.html) Selecto ...
- Scrapy爬虫框架补充内容三(代理及其基本原理介绍)
前言:(本文参考维基百科及百度百科所写) 当我们使用爬虫抓取数据时,有时会产生错误比如:突然跳出来了403 Forbidden 或者网页上出现以下提示:您的ip访问频率太高 或者时不时跳出一个验证码需 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
随机推荐
- (三十七)从私人通讯录引出的细节I -Notification -Segue -HUD -延时
细节1:账号和密码都有值的时候才可以点击登录按钮,因此应该监听文本框的文本改变. 因为文本框的文本改变代理不能处理,因此应该使用通知Notification. 文本框文本改变会发出通知:通知的前两个参 ...
- memcached /usr/local/memcached/bin/memcached: error while loading shared libraries: libevent-2.0.so.5: cannot open shared object file: No such file or directory
启动memcached的时候发现找不到libevent的库,这是memcache的默认查找路径不包含libevent的安装路径,所以要告诉memcached去哪里查找libevent. 操作命令如下: ...
- (C++)string类杂记
本文特记录C++中string类(注意string是一个类)的一些值得注意的地方. string类的实例是以‘\0'结束的吗? 这个问题有时还真容易混淆,因为我们可能会将 C++ 语言中的string ...
- HTTP2概述
HTTP/2 提供了HTTP语义的传输优化.HTTP/2支持所有HTTP/1.1的核心特征,并且在其他方面做的更高效. HTTP/2中基本的协议单位是帧.每个帧都有不同的类型和用途.例如,报头(HEA ...
- 嵌入式C语言查表法的项目应用
嵌入式C实战项目开发技巧:如果对一个有规律的数组表进行位移操作 就像下面的这个表 之前写过上面这个标题的一篇文章,讲的是以位移的方式去遍历表中的数据,效率非常高,但是,如果要实现一个乱序的流水灯或者跑 ...
- SpriteBuilder中频繁的切换场景层的解决办法
注意,不像SettingsLayer,CCScrollView实例并没有从场景中删除和重新加载像代码所示的那样. 你只是简单的改变其可视(visible)状态on和off. 改变可视状态比加载CCB或 ...
- LeetCode之“字符串”:Valid Number(由此引发的对正则表达式的学习)
题目链接 题目要求: Validate if a given string is numeric. Some examples: "0" => true " 0.1 ...
- android微信登录,分享
这几天开发要用到微信授权的功能,所以就研究了一下.可是微信开放平台接入指南里有几个地方写的不清不楚.在此总结一下,以便需要的人. 很多微信公众平台的应用如果移植到app上的话就需要微信授权登陆了. 目 ...
- Android高效率编码-细节,控件,架包,功能,工具,开源汇总,你想要的这里都有
Android高效率编码-细节,控件,架包,功能,工具,开源汇总 其实写博客的初衷也并不是说什么分享技术,毕竟咱还只是个小程序员,最大的目的就是对自我的知识积累,以后万一编码的时候断片了,也可以翻出来 ...
- Linux之ulimit详解(整理)
修改:一般可以通过ulimit命令或编辑/etc/security/limits.conf重新加载的方式使之生效通过ulimit比较直接,但只在当前的session有效,limits.conf中可以根 ...