chapter02 PCA主成分分析在手写数字识别分类的应用
#coding=utf8
# 导入numpy工具包。
import numpy as np
# 导入pandas用于数据分析。
import pandas as pd
from sklearn.metrics import classification_report
# 从sklearn.decomposition导入PCA。
from sklearn.decomposition import PCA
# 从互联网读入手写体图片识别任务的训练数据,存储在变量digits_train中。
digits_train = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/optdigits/optdigits.tra', header=None)
# 从互联网读入手写体图片识别任务的测试数据,存储在变量digits_test中。
digits_test = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/optdigits/optdigits.tes', header=None)
# 对训练数据、测试数据进行特征向量(图片像素)与分类目标的分隔。
X_train = digits_train[np.arange(64)]
y_train = digits_train[64]
X_test = digits_test[np.arange(64)]
y_test = digits_test[64]
# 导入基于线性核的支持向量机分类器。
from sklearn.svm import LinearSVC
# 使用默认配置初始化LinearSVC,对原始64维像素特征的训练数据进行建模,并在测试数据上做出预测,存储在y_predict中。
svc = LinearSVC()
svc.fit(X_train, y_train)
y_predict = svc.predict(X_test)
# 使用PCA将原64维的图像数据压缩到20个维度。
estimator = PCA(n_components=20)
# 利用训练特征决定(fit)20个正交维度的方向,并转化(transform)原训练特征。
pca_X_train = estimator.fit_transform(X_train)
# 测试特征也按照上述的20个正交维度方向进行转化(transform)。
pca_X_test = estimator.transform(X_test)
# 使用默认配置初始化LinearSVC,对压缩过后的20维特征的训练数据进行建模,并在测试数据上做出预测,存储在pca_y_predict中。
pca_svc = LinearSVC()
pca_svc.fit(pca_X_train, y_train)
pca_y_predict = pca_svc.predict(pca_X_test)
# 对使用原始图像高维像素特征训练的支持向量机分类器的性能作出评估。
print svc.score(X_test, y_test)
print classification_report(y_test, y_predict, target_names=np.arange(10).astype(str))
# 对使用PCA压缩重建的低维图像特征训练的支持向量机分类器的性能作出评估。
print pca_svc.score(pca_X_test, y_test)
print classification_report(y_test, pca_y_predict, target_names=np.arange(10).astype(str))
结果:
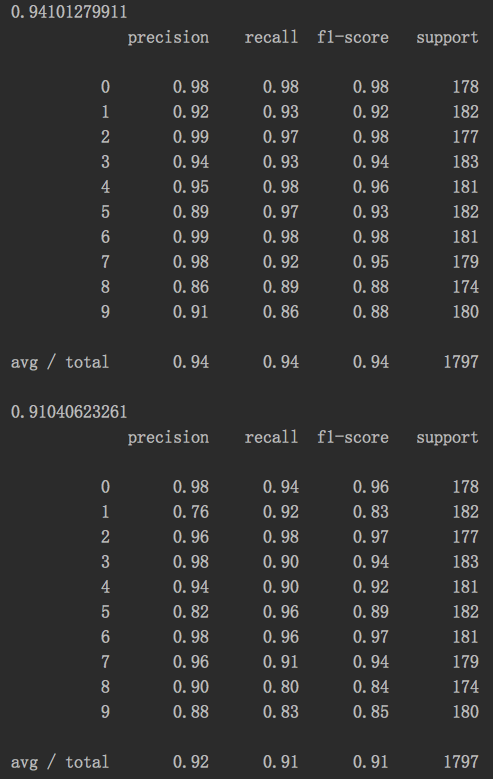
分析:虽然损失了%3的预测准确性,但是相比于原来的64维特征,使用PCA压缩并降低了68.75%的维度,能改节省大量的训练时间,在保持数据多样性的基础上,规避掉了大量特征冗余和噪声。
chapter02 PCA主成分分析在手写数字识别分类的应用的更多相关文章
- kaggle 实战 (1): PCA + KNN 手写数字识别
文章目录 加载package read data PCA 降维探索 选择50维度, 拆分数据为训练集,测试机 KNN PCA降维和K值筛选 分析k & 维度 vs 精度 预测 生成提交文件 本 ...
- 【Keras篇】---利用keras改写VGG16经典模型在手写数字识别体中的应用
一.前述 VGG16是由16层神经网络构成的经典模型,包括多层卷积,多层全连接层,一般我们改写的时候卷积层基本不动,全连接层从后面几层依次向前改写,因为先改参数较小的. 二.具体 1.因为本文中代码需 ...
- 基于卷积神经网络的手写数字识别分类(Tensorflow)
import numpy as np import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_dat ...
- MindSpore手写数字识别初体验,深度学习也没那么神秘嘛
摘要:想了解深度学习却又无从下手,不如从手写数字识别模型训练开始吧! 深度学习作为机器学习分支之一,应用日益广泛.语音识别.自动机器翻译.即时视觉翻译.刷脸支付.人脸考勤--不知不觉,深度学习已经渗入 ...
- 机器学习框架ML.NET学习笔记【4】多元分类之手写数字识别
一.问题与解决方案 通过多元分类算法进行手写数字识别,手写数字的图片分辨率为8*8的灰度图片.已经预先进行过处理,读取了各像素点的灰度值,并进行了标记. 其中第0列是序号(不参与运算).1-64列是像 ...
- 机器学习框架ML.NET学习笔记【5】多元分类之手写数字识别(续)
一.概述 上一篇文章我们利用ML.NET的多元分类算法实现了一个手写数字识别的例子,这个例子存在一个问题,就是输入的数据是预处理过的,很不直观,这次我们要直接通过图片来进行学习和判断.思路很简单,就是 ...
- Tensorflow之MNIST手写数字识别:分类问题(1)
一.MNIST数据集读取 one hot 独热编码独热编码是一种稀疏向量,其中:一个向量设为1,其他元素均设为0.独热编码常用于表示拥有有限个可能值的字符串或标识符优点: 1.将离散特征的取值扩展 ...
- Kaggle竞赛丨入门手写数字识别之KNN、CNN、降维
引言 这段时间来,看了西瓜书.蓝皮书,各种机器学习算法都有所了解,但在实践方面却缺乏相应的锻炼.于是我决定通过Kaggle这个平台来提升一下自己的应用能力,培养自己的数据分析能力. 我个人的计划是先从 ...
- 【深度学习系列】手写数字识别卷积神经--卷积神经网络CNN原理详解(一)
上篇文章我们给出了用paddlepaddle来做手写数字识别的示例,并对网络结构进行到了调整,提高了识别的精度.有的同学表示不是很理解原理,为什么传统的机器学习算法,简单的神经网络(如多层感知机)都可 ...
随机推荐
- Mac OS下 selenium 驱动safari日志
/Library/Java/JavaVirtualMachines/jdk1.8.0_171.jdk/Contents/Home/bin/java "-javaagent:/Applicat ...
- Qt数据库_资料
1. QT笔记_数据库总结(一)-rojian-ChinaUnix博客.html http://blog.chinaunix.net/uid-28194872-id-3631462.html (里面有 ...
- css 键盘
<html lang="en"> <head> <meta charset="UTF-8"> <title>Do ...
- python-GUI,生成ssn
第一次做这个, 样子有点丑,主要是实现功能,做测试的时候,经常要用到身份证号.手机号.姓名等,这里先生成ssn,后续研究怎么做成客户端 代码: from tkinter import * from u ...
- English trip -- VC(情景课)5 Around Town
Around Town 城市周围 Talk about the picture 看图说话 sentences Where are you? I'm in the Meten classroom. ...
- Python在七牛云平台的应用(三)简单的人脸识别
前言 这是最后一篇介绍python在七牛云平台的应用了,因为-前两篇文章第一篇分享了怎么安装七牛的官方库以及怎么对自己的空间进行下载上传,删除等行动.而第二篇则分享了怎么利用七牛的API接口,由于七牛 ...
- hdu-6319-单调队列
Problem A. Ascending Rating Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 524288/524288 K ...
- hibernate一级缓存和二级缓存的区别
http://blog.csdn.net/defonds/article/details/2308972 缓存是介于应用程序和物理数据源之间,其作用是为了降低应用程序对物理数据源访问的频次,从而提高了 ...
- kill word fore out
1● fore f ɔ: 预先,前面
- POJ 2886 线段树单点更新
转载自:http://blog.csdn.net/sdj222555/article/details/6878651 反素数拓展参照:http://blog.csdn.net/ACdreamers/a ...