mybatis学习系列三(部分)
1 forearch_oracle下批量保存(47)
oracle批量插入
不支持values(),(),()方式
1、多个insert放在begin-end里面
begin
insert into myemployeee(id,last_name,email,gender,dept_id) values
(myemployeee_seq.nextval,#{emp.lastName,jdbcType=VARCHAR},#{emp.email,jdbcType=VARCHAR},
insert into myemployeee(id,last_name,email,gender,dept_id) values
(myemployeee_seq.nextval,#{emp.lastName,jdbcType=VARCHAR},#{emp.email,jdbcType=VARCHAR},
end;
#{emp.gender,jdbcType=VARCHAR},#{emp.deptId,jdbcType=INTEGER})
2、利用中间表
insert into employeee(id,last_name,email)
select employeee_seq.nextval,lastName,email from (
select 'test_a_01' lastName,'test_a_e1' email from dual
union
select 'test_a_02' lastName,'test_a_e2' email from dual
union
select 'test_a_03' lastName,'test_a_e3' email from dual
方式一:
<!-- oracle第一种方式 -->
<foreach collection="emps" item="emp" open="begin" close="end;">
insert into myemployeee(id,last_name,email,gender,dept_id)
values
(myemployeee_seq.nextval,#{emp.lastName,jdbcType=VARCHAR},#{emp.email,jdbcType=VARCHAR},
#{emp.gender,jdbcType=VARCHAR},#{emp.deptId,jdbcType=INTEGER})
</foreach>
方式二:
<!-- oracle第二种方式 -->
insert into myemployeee(id,last_name,email,gender,dept_id)
select employeee_seq.nextval,lastName,email,gender,deptId from
<foreach collection="emps" item="emp" open="(" close=")" separator="union">
select #{emp.lastName,jdbcType=VARCHAR} lastName,#{emp.email,jdbcType=VARCHAR} email,
#{emp.gender,jdbcType=VARCHAR} gender,#{emp.deptId,jdbcType=VARCHAR} deptId
from dual
</foreach>
2 动态sql-内置参数_parameter和_databaseId(48)
不只是方法传递过来的参数可以被判断,取值
Mybatis还有2个默认内置参数:
_parameter:代表整个参数
单个参数:_parameter即这个参数
多个参数:参数会被封装为一个map,_parameter代表该map
_databaseId:如果配置了DatabaseIdProvider标签,_databaseId代表当前数据库别名(如oracle)
<!-- 内置参数_databaseId和 _parameter
selectEmployeeByInnerParameter(Employee employee);
-->
<select id="selectEmployeeByInnerParameter" resultType="com.mybatis.bean.Employee">
<if test="_databaseId == 'oralce' ">
select * from tbl_employeee
<!-- <if test="_parameter !=null">
where last_name= #{_parameter.lastName}
</if> -->
<if test="_parameter !=null">
where last_name= #{lastName}
</if>
</if>
<if test="_databaseId == 'mysql' ">
select * from myemployeee
<if test="_parameter !=null">
where last_name=#{_parameter.lastName}
</if>
</if>
</select>
3 动态sql-bind绑定(49)
<if test="_databaseId == 'mysql' ">
select * from myemployeee
<!-- like 查询
方式一:$ 不安全
where last_name like '%${lastName}%'
方式二:# CONCAT
where last_name like CONCAT('%',#{lastName},'%')
方式三:bind,将值绑定到一个变量中,方便后来引用
<bind name="_lastName" value="'%'+lastName+'%'"/>
<if test="_parameter !=null">
where last_name like #{_lastName}
</if>
-->
<bind name="_lastName" value="'%'+lastName+'%'"/>
<if test="_parameter !=null">
where last_name like #{_lastName}
</if>
</if>
4 动态sql-sql抽取可重用sql片段(50)
1)定义sql片段
<sql id="queryColumn">
id,last_name,email,gender,dept_id
</sql>
2)使用
select
<include refid="queryColumn"></include>
from myemployeee
include中自定义属性及值,sql标签内即可使用
注意:只能使用$,不能使用#
select
<include refid="queryColumn">
<!-- 自定义属性及值 -->
<property name="testColumn" value="test"/>
</include>
from myemployeee
<sql id="queryColumn">
id,last_name,email,gender,dept_id,${testColumn}
</sql>
5 缓存-一级缓存(51-53)
一级缓存:默认开启,sqlsession级别缓存(也称为本地缓存),查询的结果存放在map中
二级缓存:手动开启和配置,基于namespace级别
1)测试一级缓存
EmployeeMapper mapper=session.getMapper(EmployeeMapper.class);
List<Employee> emps=mapper.selectEmployeeByInnerParameter(new Employee(null,"addemps1","addemps1@qq.com","男",1));
System.out.println(emps.toString());
List<Employee> emps2=mapper.selectEmployeeByInnerParameter(new Employee(null,"addemps1","addemps1@qq.com","男",1));
System.out.println(emps2.toString());
System.out.println(emps2==emps); //为true
实际只执行了一次sql语句,后面的查询从一级缓存获取
一级缓存失效情况:
1、sqlsession不同
2、Sqlsession相同,查询条件不同(需要执行新sql)
3、sqlsession相同,2次查询间执行了增删改操作(影响当前数据)
4、sqlsession相同,手动清除了一级缓存
1、sqlsession不同
//一级缓存测试失效(非同一个sqlsession),执行2次sql
EmployeeMapper mapper=session.getMapper(EmployeeMapper.class);
List<Employee> emps=mapper.selectEmployeeByInnerParameter(new Employee(null,"addemps1","addemps1@qq.com","男",1));
System.out.println(emps.toString());
SqlSession session2 = sqlSessionFactory.openSession();//手动提交
EmployeeMapper mapper2=session2.getMapper(EmployeeMapper.class);
List<Employee> emps2=mapper2.selectEmployeeByInnerParameter(new Employee(null,"addemps1","addemps1@qq.com","男",1));
System.out.println(emps2.toString());
System.out.println(emps2==emps); //为false
2、sqlsession相同,查询条件不同
//一级缓存测试失效(情况2:同一个sqlsession,不同查询条件)
EmployeeMapper mapper=session.getMapper(EmployeeMapper.class);
List<Employee> emps=mapper.selectEmployeeByInnerParameter(new Employee(null,"addemps1","addemps1@qq.com","男",1));
System.out.println(emps.toString());
List<Employee> emps2=mapper.selectEmployeeByIds(Arrays.asList(1,2,3));
System.out.println(emps2.toString());
System.out.println(emps2==emps); //为false
3、sqlsession相同,2次查询间执行了增删改操作(影响当前数据)
//一级缓存测试失效(情况3:sqlsession相同,2次查询间执行了增删改操作(影响当前数据))
EmployeeMapper mapper=session.getMapper(EmployeeMapper.class);
List<Employee> emps=mapper.selectEmployeeByInnerParameter(new Employee(null,"addemps1","addemps1@qq.com","男",1));
System.out.println(emps.toString());
//更新操作
int updateSize=mapper.updateEmp(new Employee(3,"test333","test3333@com.cm","女",1));
List<Employee> emps2=mapper.selectEmployeeByIds(Arrays.asList(1,2,3));
System.out.println(emps2.toString());
System.out.println(emps2==emps); //为false
4、sqlsession相同,手动清除了一级缓存
//一级缓存测试失效(情况4:同一个sqlsession,清除了一级缓存)
EmployeeMapper mapper=session.getMapper(EmployeeMapper.class);
List<Employee> emps=mapper.selectEmployeeByInnerParameter(new Employee(null,"addemps1","addemps1@qq.com","男",1));
System.out.println(emps.toString());
session.clearCache();
List<Employee> emps2=mapper.selectEmployeeByIds(Arrays.asList(1,2,3));
System.out.println(emps2.toString());
System.out.println(emps2==emps); //为false
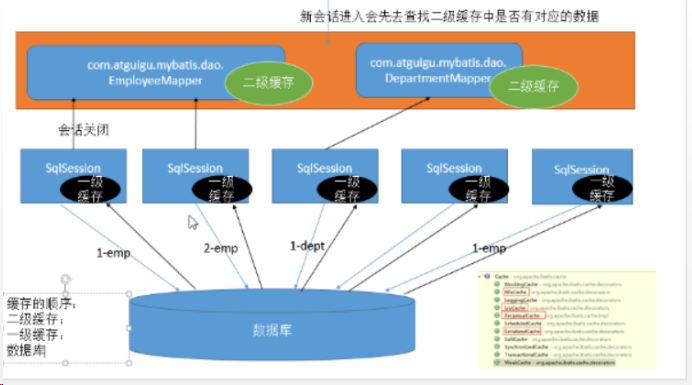
6 缓存-二级缓存(54-55)
二级缓存(全局缓存),基于namespace级别缓存
工作机制:
1、一个会话查询一条数据,数据会被放在当前会话的一级缓存中。
2、会话关闭,一级缓存中的数据会被保存到二级缓存中。
3、sqlsession==employmapper==>employee
Deptmapper===>dept
不同namespace查出数据会放在自己对应的缓存map中
查询的数据默认先放在一级缓存中,只有会话提交或关闭后,一级缓存中的数据会转移到二级缓存中
使用:
1)开启二级缓存配置
默认开启,也可在mybatis-config.xml配置文件中设置
<!-- 开启二级缓存,默认开启 -->
<setting name="cacheEnabled" value="true"/>
2)在xml配置使用(namespace级别)
Mapper中配置使用二级缓存
<cache></cache>
<!-- mapper中配置二级缓存
eviction:回收策略,LRU,FIFO,SOFT,WEAK;默认LRU
flushInterval:缓存刷新间隔(默认不清空),定位秒
readOnly:是否只读,true/false,默认false
true:mybatis认为所有从缓存中获取数据的操作都是只读操作,不会修改数据,
mybatis为了加快获取速度,会直接将数据在缓存中的引用返回,不安全,速度快
false:非只读,mybatis可能认为数据可能会被修改,mybatis会利用序列化&反序列化技术克隆数据,安全,速度慢
-->
<cache eviction="" flushInterval="" readOnly=""></cache>
3)POJO需要实现序列化接口
测试样例:
1)mapper中配置
<cache></cache>
2)测试类
//二级缓存测试
EmployeeMapper mapper=session.getMapper(EmployeeMapper.class);
List<Employee> emps=mapper.selectEmployeeByInnerParameter(new Employee(null,"addemps1","addemps1@qq.com","男",1));
System.out.println(emps.toString());
session.close();
SqlSession session2 = sqlSessionFactory.openSession();//手动提交
EmployeeMapper mapper2=session2.getMapper(EmployeeMapper.class);
List<Employee> emps2=mapper2.selectEmployeeByIds(Arrays.asList(1,2,3));
System.out.println(emps2.toString());
System.out.println(emps2==emps); //为false
session2.close();
3)报错
[com.mybatis.bean.Employee@2473b9ce, com.mybatis.bean.Employee@60438a68, com.mybatis.bean.Employee@140e5a13, com.mybatis.bean.Employee@3439f68d]
Exception in thread "main" org.apache.ibatis.cache.CacheException: Error serializing object. Cause: java.io.NotSerializableException: com.mybatis.bean.Employee
at org.apache.ibatis.cache.decorators.SerializedCache.serialize(SerializedCache.java:102)
Employee没有序列化,实现Serializable接口后
再报错:
false
Exception in thread "main" org.apache.ibatis.cache.CacheException: Error serializing object. Cause: java.io.NotSerializableException: com.mybatis.bean.MyDept
MyDept没有序列化,实现Serializable接口
4)输出结果
[com.mybatis.bean.Employee@2473b9ce, com.mybatis.bean.Employee@60438a68, com.mybatis.bean.Employee@140e5a13, com.mybatis.bean.Employee@3439f68d]
[com.mybatis.bean.Employee@29ba4338, com.mybatis.bean.Employee_$$_jvst385_0@7bb58ca3]
false
False是因为通过序列化拷贝的数据。
如果不配置<cache>,则会发送2次sql请求;
7 缓存-二级缓存的设置(56)
1)setting配置中
<!-- 开启二级缓存,默认开启 -->
<setting name="cacheEnabled" value="false"/>
关闭二级缓存,但一级缓存未关闭;设置的是二级缓存
2)每个select标签都有useCache=true,默认为true;false为关闭;设置的是二级缓存。
3)每个增删改包含标签:flushcache=true;默认为true;清空缓存(一级和二级缓存都清空
4)sqlsession.clearCache();清空一级缓存
5)localcachescope:本地缓存(本地会话)范围,一级缓存
8缓存-原理图示(57 )
9缓存-第三方缓存整合原理&ehcache适配器(58-59)
引入ehcache-core缓存jar包,还有其他缓存包,可参考mybatis github网站
mybatis学习系列三(部分)的更多相关文章
- MyBatis学习系列三——结合Spring
目录 MyBatis学习系列一之环境搭建 MyBatis学习系列二——增删改查 MyBatis学习系列三——结合Spring MyBatis在项目中应用一般都要结合Spring,这一章主要把MyBat ...
- MyBatis学习系列二——增删改查
目录 MyBatis学习系列一之环境搭建 MyBatis学习系列二——增删改查 MyBatis学习系列三——结合Spring 数据库的经典操作:增删改查. 在这一章我们主要说明一下简单的查询和增删改, ...
- MyBatis学习系列一之环境搭建
目录 MyBatis学习系列一之环境搭建 MyBatis学习系列二——增删改查 MyBatis学习系列三——结合Spring 学习一个新的知识,首先做一个简单的例子使用一下,然后再逐步深入.MyBat ...
- MyBatis学习 之 三、动态SQL语句
目录(?)[-] 三动态SQL语句 selectKey 标签 if标签 if where 的条件判断 if set 的更新语句 if trim代替whereset标签 trim代替set choose ...
- 【转】MyBatis学习总结(三)——优化MyBatis配置文件中的配置
[转]MyBatis学习总结(三)——优化MyBatis配置文件中的配置 一.连接数据库的配置单独放在一个properties文件中 之前,我们是直接将数据库的连接配置信息写在了MyBatis的con ...
- mybatis入门系列三之类型转换器
mybatis入门系列三之类型转换器 类型转换器介绍 mybatis作为一个ORM框架,要求java中的对象与数据库中的表记录应该对应 因此java类名-数据库表名,java类属性名-数据库表字段名, ...
- scrapy爬虫学习系列三:scrapy部署到scrapyhub上
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- DocX开源WORD操作组件的学习系列三
DocX学习系列 DocX开源WORD操作组件的学习系列一 : http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_sharp_001_docx1.htm ...
- RabbitMQ学习系列三-C#代码接收处理消息
RabbitMQ学习系列三:.net 环境下 C#代码订阅 RabbitMQ 消息并处理 http://www.80iter.com/blog/1438251320680361 http://www. ...
随机推荐
- Linux - 修改内核启动顺序及删除无用内核
现象: CentOS7开机启动界面显示多个内核选项 原因: 正常情况下,有两个启动项,一个是"正常启动",另一个是"救援模式启动"(rescue). 如果启动项 ...
- Leetcode:148_Sort List | O(nlogn)链表排序 | Medium
题目:Sort List Sort a linked list in O(n log n) time using constant space complexity 看题目有两个要求:1)时间复杂度为 ...
- Python——通过用户cookies访问微博首页
通过用户cookies访问微博首页 1.登录微博 self.driver.delete_all_cookies() # 删除cookies self.driver.get(self.url) time ...
- [源码]Delphi 5KB无输入表下载者
[源码]Delphi 5KB无输入表下载者源码 PROGRAM Fun; type DWORD = LongWord; THandle = LongWord; BOOL = LongBool; LPC ...
- Java异常处理设计(三)
接着上一篇讲. 一个异常日志处理的例子: 抛出异常的地方为: try{ ... ...//省略N行 }catch( Exception e){ throw new RuntimeException ( ...
- Android生成自定义二维码
前面说过两种二维码扫描方式,现在说如何生成自定义酷炫二维码.二维码生成需要使用Google开源库Zxing,Zxing的项目地址:https://github.com/ZBar/ZBar,我们只需要里 ...
- Linux_CentOS-服务器搭建 <七>
设置Linux下Mysql表名不区分大小写 对linux安装mysql不熟悉的(查看我那一系列的文章第一篇): http://www.cnblogs.com/Alandre/p/3365535.htm ...
- 从零开始学 Web 之 移动Web(九)微金所案例
大家好,这里是「 从零开始学 Web 系列教程 」,并在下列地址同步更新...... github:https://github.com/Daotin/Web 微信公众号:Web前端之巅 博客园:ht ...
- Docker修改默认网段
因阿里云服务器VPC默认占用了172.16.0.0/16 网段,与Docker里的网段相同,导致Docker里无法连接VPC服务器.后来找到的解决方案是修改Docker的默认网段. 由于Docker默 ...
- Kafka项目实战-用户日志上报实时统计之应用概述
1.概述 本课程的视频教程地址:<Kafka实战项目之应用概述> 本课程是通过一个用户实时上报日志来展开的,通过介绍 Kafka 的业务和应用场景,并带着大家搭建本 Kafka 项目的实战 ...