Hive的基本概念
一、Hive基本概念
1.什么是Hive?
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载。可以存储、查询和分析存储在Hadoop中的大规模数据。
hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。
Hive的优点是学习成本低,可以通过HQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。
hive十分适合数据仓库的统计分析。
2.Hive的优缺点?
(1)优点
- 简单容易上手:提供了类SQL查询语言HQL
- 可扩展:为超大数据集设计了计算/扩展能力(MR作为计算引擎,HDFS作为存储系统)一般情况下不需要重启服务Hive可以自由的扩展集群的规模。
- 提供统一的元数据管理
- 延展性:Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
- 容错:良好的容错性,节点出现问题SQL仍可完成执行
(2)缺点(局限性)
hive的HQL表达能力有限
- 迭代式算法无法表达,比如pagerank
- 数据挖掘方面,比如kmeans
hive的效率比较低
- hive自动生成的mapreduce作业,通常情况下不够智能化
- hive调优比较困难,粒度较粗
- hive可控性差
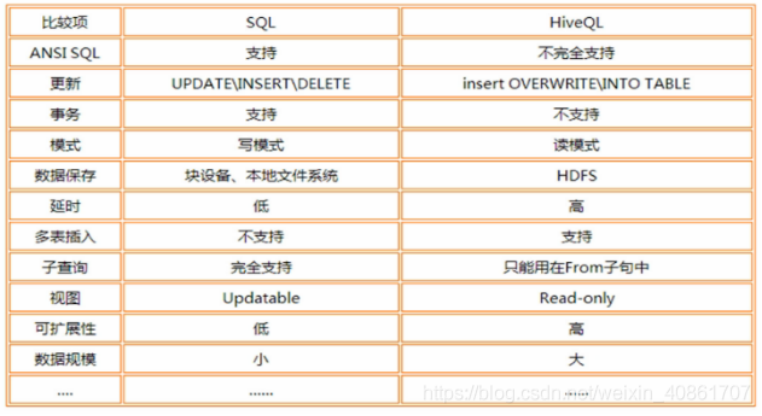
3.Hive和传统数据库有什么异同?
4.Hive架构原理?
(1)Hive架构简介
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行。最后将执行返回的结果输出到用户交互接口。
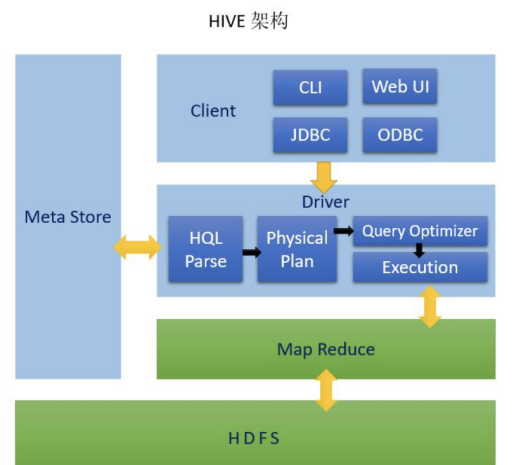
(2)Hive用户接口
包括 : CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive)、BEELINE。
BEELINE:hive客户端链接到hive的一个工具。可以理解成mysql的客户端,如:Navicat 等。
(3)Hive元数据
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等。
一般存储关系型数据库MySQL中,在测试阶段也可以用hive内置Derby数据库。
(4)Hive的HSQL转换为MapReduce的过程
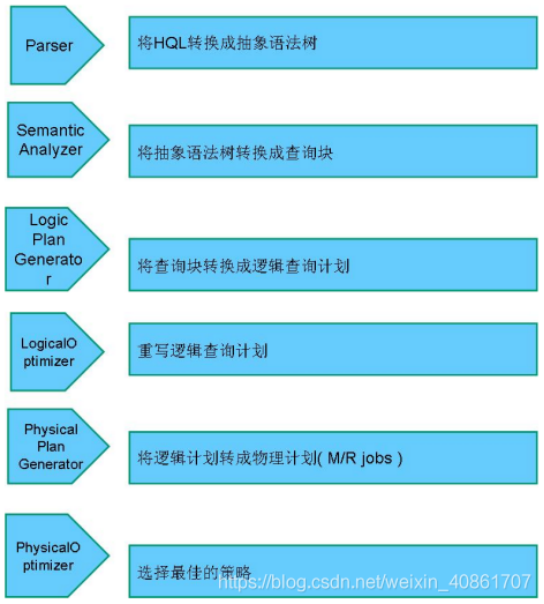
过程描述如下:
SQL Parser(解析器) :Antlr(是指可以根据输入自动生成语法树并可视化的显示出来的开源语法分析器)定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象 语法树AST Tree;
Semantic Analyzer(语义分析器): 遍历AST Tree,抽象出查询的基本组成单元QueryBlock;
Logical plan(逻辑计划): 遍历QueryBlock,翻译为执行操作树OperatorTree;
Logical plan optimizer(优化器): 逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量;
Physical plan: 遍历OperatorTree,翻译为MapReduce任务;
Logical plan optimizer: 物理层优化器进行MapReduce任务的变换,生成最终的执行计划;
5.Hive底层与数据库交互原理?
由于Hive的元数据可能要面临不断地更新、修改和读取操作,所以它显然不适合使用Hadoop文件系统进行存储。
目前Hive将元数据存储在RDBMS中,比如存储在MySQL、Derby中。
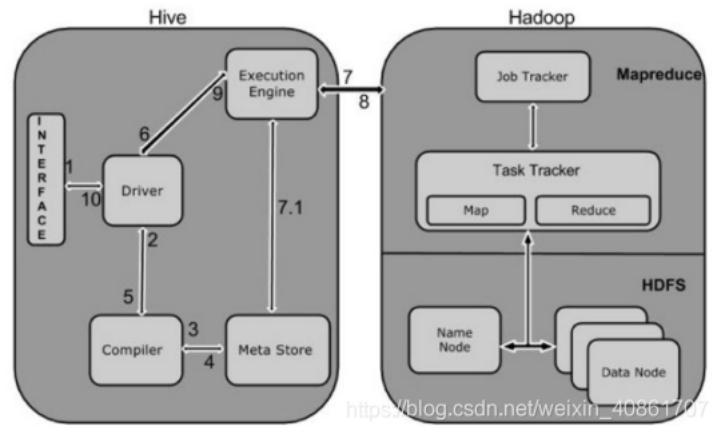
6.Hive有哪些方式保存元数据,各有哪些特点?
元数据存储在关系型数据库中。如Derby、MySQL等。
Metastore的作用是:客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。
Hive支持三种不同的元数据存储模式,分别为:内嵌模式、本地模式、远程模式,每种存储方式使用不同的配置参数。
内嵌模式主要用于单元测试,在该模式下每次只有一个进程可以连接到元数据存储,Derby是内嵌式元数据存储的默认数据库。
优点:小巧,无需额外配置metastore服务
缺点:每次只能有一个进程访问元数据,不支持多会话. 内存,不够稳定
本地模式:将元数据保存在本地独立的数据库中(一般是mysql),可以支持多会话连接.
在远程模式下,所有的Hive客户端都将打开一个到元数据服务器的连接,该服务器依次查询元数据,元数据服务器和客户端之间使用Thrift协议通信。避免每个客户端都去安装Mysql数据库
本地元存储和远程元存储的区别是:本地元存储不需要单独起metastore服务,用的是跟hive在同一个进程里的metastore服务。远程元存储需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。远程元存储的metastore服务和hive运行在不同的进程。
7.Hive如何进行权限控制?
hive支持简单的权限管理,默认情况下是不开启,这样所有的用户都具有相同的权限,同时也是超级管理员,也就对hive中的所有表都有查看和改动的权利,这样是不符合一般数据仓库的安全原则的。Hive可以是基于元数据的权限管理,也可以基于文件存储级别的权限管理。
为了使用Hive的授权机制,有两个参数必须在hive-site.xml中设置:
<property>
<name>hive.security.authorization.enabled</name>
<value>true</value>
<description>enable or disable the hive client authorization</description>
</property>
<property>
<name>hive.security.authorization.createtable.owner.grants</name>
<value>ALL</value>
<description>the privileges automatically granted to the owner whenever a table gets created. An example like "select,drop" will grant select and drop privilege to the owner of the table</description>
</property>
Hive支持以下权限:
|
权限名称 |
含义 |
|
ALL |
所有权限 |
|
ALTER |
允许修改元数据(modify metadata data of object) --表信息数据 |
|
UPDATE |
允许修改物理数据(modify physical data of object) --实际数据 |
|
CREATE |
允许进行CREATE操作 |
|
DROP |
允许进行DROP操作 |
|
INDEX |
允许建索引(目前还没有实现) |
|
LOCK |
当出现并发的时候允许用户进行LOCK和UNLOCK操作 |
|
SELECT |
允许用户进行SELECT操作 |
|
SHOW_DATABASE |
允许用户查看可用的数据库 |
Hive授权的核心就是用户(user)、组(group)、角色(role)。
Hive的用户和组使用的是Linux机器上的用户和组,而角色必须自己创建。
角色管理:
--创建和删除角色
create role role_name;
drop role role_name;
--展示所有roles
show roles
--赋予角色权限
grant select on database db_name to role role_name;
grant select on [table] t_name to role role_name;
--查看角色权限
show grant role role_name on database db_name;
show grant role role_name on [table] t_name;
--角色赋予用户
grant role role_name to user user_name
--回收角色权限
revoke select on database db_name from role role_name;
revoke select on [table] t_name from role role_name;
--查看某个用户所有角色
show role grant user user_name;
Hive的基本概念的更多相关文章
- 【Hadoop离线基础总结】数据仓库和hive的基本概念
数据仓库和Hive的基本概念 数据仓库 概述 数据仓库英文全称为 Data Warehouse,一般简称为DW.主要目的是构建面向分析的集成化数据环境,主要职责是对仓库中的数据进行分析,支持我们做决策 ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- Hive的基本概念和常用命令
原文链接: https://www.toutiao.com/i6766571623727235595/?group_id=6766571623727235595 一.概念: 1.结构化和非结构化数据 ...
- Hive 的基本概念
Hadoop开发存在的问题 只能用java语言开发,如果是c语言或其他语言的程序员用Hadoop,存在语言门槛. 需要对Hadoop底层原理,api比较了解才能做开发. Hive概述 Hive是基于H ...
- Hive(1)-基本概念
一. 什么是Hive Hive:由Facebook开源用于解决海量结构化日志的数据统计. Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能. 本 ...
- Hive从概念到安装使用总结
一.Hive的基本概念 1.1 hive是什么? (1)Hive是建立在hadoop数据仓库基础之上的一个基础架构: (2)相当于hadoop之上的一个客户端,可以用来存储.查询和分析存储在hadoo ...
- Hive深入浅出
1. Hive是什么 1) Hive是什么? 这里引用 Hive wiki 上的介绍: Hive is a data warehouse infrastructure built on top of ...
- Hive分区(静态分区+动态分区)
Hive分区的概念与传统关系型数据库分区不同. 传统数据库的分区方式:就oracle而言,分区独立存在于段里,里面存储真实的数据,在数据进行插入的时候自动分配分区. Hive的分区方式:由于Hive实 ...
- Hive的HQL语句及数据倾斜解决方案
[版权申明:本文系作者原创,转载请注明出处] 文章出处:http://blog.csdn.net/sdksdk0/article/details/51675005 作者: 朱培 ID ...
- Hive篇--相关概念和使用二
一.基本概念 Hive分桶: 1.概念 分桶表是对列值取哈希值的方式,将不同数据放到不同文件中存储.对于hive中每一个表.分区都可以进一步进行分桶.(可以对列,也可以对表进行分桶)由列的哈希值除以桶 ...
随机推荐
- sipp3.6多方案压测脚本
概述 SIP压测工具sipp,免费,开源,功能足够强大,配置灵活,优点多. 有时候我们需要模拟现网的生产环境来压测,就需要同时有多个sipp脚本运行,并且需要不断的调整呼叫并发. 通过python脚本 ...
- idea相关配置及插件安装
对idea相关的配置及好用的插件进行总结下. 一.idea 破解码及配置:https://www.jb51.net/softs/672190.html 二.idea插件: 1.findBugs-ide ...
- SV 接口中的clocking
接口 module可以例化模块,可以例化接口 接口不能例化模块 采样和数据驱动 时钟驱动数据,数据会有延迟,RTL仿真的时候,不会仿真出这个延时;RTL仿真的时候,不会仿真出寄存器的延时;只有在门级仿 ...
- 【rt-thread】构建自己的项目工程 -- 初始篇
现以stm32f429igt6芯片的板子 & Keil5编译环境为例,记述构建适配自己板子的rt-thread工程的过程 1.拿到rt-thread源码,进入bsp/stm32/librari ...
- DDP运行报错(单卡无错):ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1)
使用DDP时出现错误,但是单卡跑无错误. 错误记录如下: RuntimeError: Expected to have finished reduction in the prior iteratio ...
- 00.Oracle 11g安装
通过Docker安装Oracle 1.搜索镜像 先使用指令搜素远程仓库中的Oracle镜像 sudo docker search docker-oracle-xe-11g 2.拉取镜像 选择一个sta ...
- Redis-键
- 【转】国产飞腾D2000:基于A72?
https://zhuanlan.zhihu.com/p/612054128 China's Phytium D2000: Building on A72? 国产飞腾D2000:基于A72? PS:麒 ...
- Cloudquery的学习安装与使用
Cloudquery的学习安装与使用 下载 官方下载地址: https://www.cloudquery.club/download https://pan.baidu.com/s/1a7XOrnMU ...
- Harbor修改默认网段以及设置开机启动的方法
Harbor修改默认网段以及设置开机启动的方法 背景 docker 默认的网段是 172.16.xx.xx 网段. harbor进行设置时会自动加1 设置为 172.17.xx.xx 有时候这个网段是 ...