分库分表后全局唯一ID的四种生成策略对比
分库分表之后,ID主键如何处理?
当业务量大的时候,数据库中数据量过大,就要进行分库分表了,那么分库分表之后,必然将面临一个问题,那就是ID怎么生成?因为要分成多个表之后,如果还是使用每个表的自增长ID,意味着每个表都是从1开始累加的,这样肯定是不对的。需要一个全局唯一的ID来支持。所以这也是你实际生产环境中必须考虑的一个问题。全局ID生成器,一般需要满足下列几个特性:
唯一性、高可用、递增性、安全性、高可用性
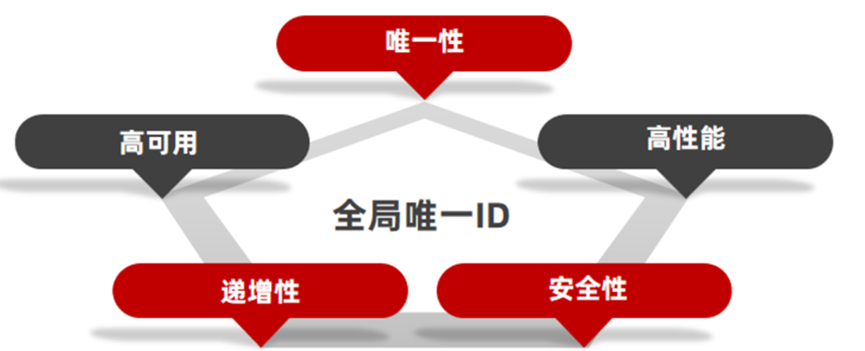
常用的主键ID生成策略有以下几种:
数据库自增ID
原理:
如果使用这种方式,那么这就意味着,你的系统里每次得到一个ID,都需要往一个库中的一个表中插入一条没有什么业务含义的数据,然后获取一个数据库自增的id.拿到这个ID之后,再往对应的分库分表里写。
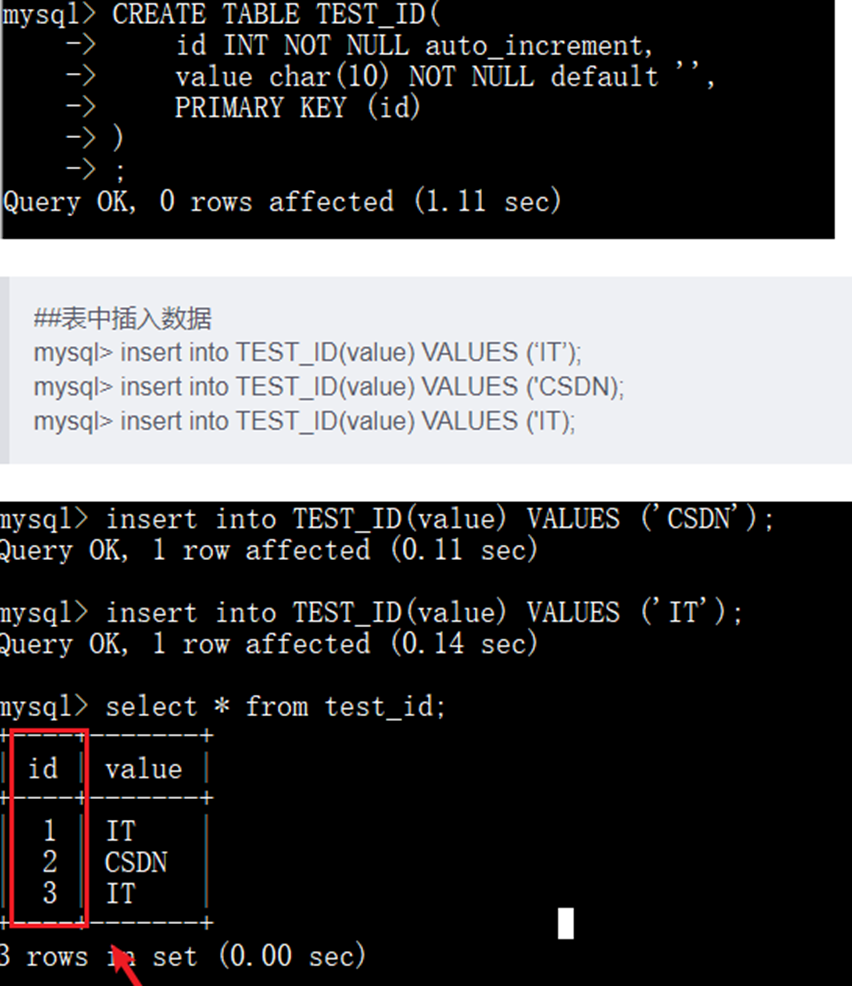
这种方式的优缺点如下:
优点:非常简单,有序递增,方便分页和排序。
缺点:
a.分库分表之后,数据表的自增ID容易重复,无法直接使用(虽然可以设置步长,但是局限性明显);
b.性能吞吐量整个比较低。如果设计一个单独的数据库来实现分布式应用的数据唯一性,即使使用预先生成方案,也会因为事务问题,在高并发场景下容易出现单点的瓶颈问题。
使用场景:单数据库实例的表ID(包含主从同步场景);部分按天计数的流水号等
在分不分表场景、全局唯一性ID场景下不使用。
Redis生产全局ID
原理:
通过Redis的INCR/INCRBY自增原子操作命令,能保证生产的ID肯定是唯一的序列号,本质上实现方式与数据库一致的。
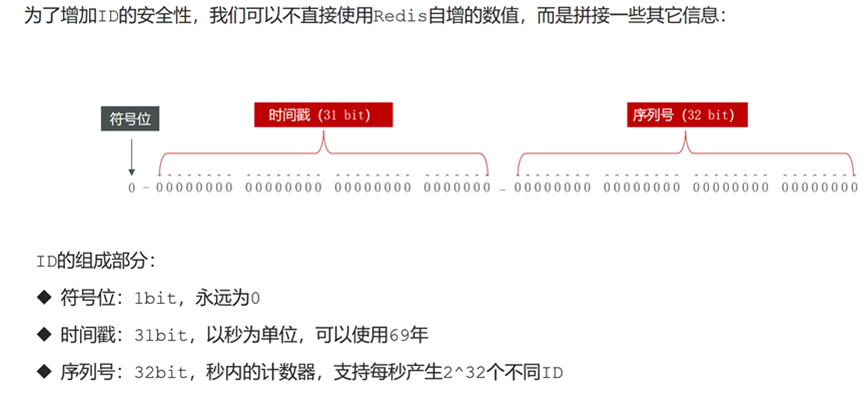
使用Redis生产全局ID的优缺点:
本文由凯哥Java(公众号:kaigejava),个人博客:www.kaigejava.com 发布于博客园.
凯哥自己开发的,领取外卖、打车、咖啡、买菜、各大电商的优惠券的公¥众¥号。如下图:
优点:整体吞吐量比数据库要高。因为Redis的吞吐量性能高于数据库
缺点:Redis实例或者集群宕机后,找回最新的ID值比较麻烦。但是可以在生产唯一ID的算法上进行优化,避免这种情况。
使用场景:比较适合计算场景。比如用户访问量、订单流水号(日期+流水号)等。
凯哥推荐文章:Redis实战9-全局唯一ID
UUID、GUID生成ID
优缺点:
优点:性能非常高。在本地生成,没有网络消耗;
缺点:UUID太长了,占用空间大,作为主键性能太差了;
由于UUI不具有有序性,会导致B+树索引在写的时候有过多的随机写操作。
使用场景:如果你要随机生成一个什么文件名称、编号之类的,可以考虑使用UUID,但是如果是作为数据库的主键,不建议使用UUID的。
雪花算法(snowflake)
雪花算法来源于Twitter,使用Scala语言实现,雪花算法的特性是有序、唯一且要求性能高,低延迟(每台集群每秒至少生成10K条数据,并且响应时间在2MS内),要在分布式环境(多集群、跨机房)下使用。因此雪花算法得到的ID是分段组成的。
a.与指定日期时间差(时间差到毫秒级)的,41位数字,可以使用69年;
b.机器ID+集群ID,10位,最多支持1024台机器;
c.序列号,12位。每台机器每毫秒内最多生产4096个序列号.
雪花算法的核心思想是:
分布式ID固定是一个long类型的数字,一个long类型占用8个字节,也就是8*8=64个bit位。所以,雪花算法的格式如下图:

雪花算法分段,每段含义:
第一段:也就是最高1位是符号位。固定值,就是0,标识全部ID都是正整数。
第二段:接下来的41位,标识的是时间戳。单位是毫秒。41bits标识的数字对应的是2^41次方-1.也就是可以标识2的41次方-1个毫秒值。换算成年就是标识69年的时间;
第三段:再接下来的10位标识的是机器ID。如果有异地部署,多集群的也可以配置,需要在线下提前规划好各地机房,各个集群,实例ID的编号。其中包括5位的机器id和5位的集群id.最多可以部署2^10台机器。也就是1024台。
第四段:最后12位是序列号。用于记录同一毫秒内产生的不同ID.12个比特位可以代表的最大正整数是2^12-1=4096.也就是说,可以用这12个bits代表数字来区分同一毫秒内4096个不同的ID.
此算法的优缺点如下:
雪花算法的优缺点:
优点:毫秒数在高位,自增序列在低位,所以整个ID都呈现出递增趋势;
不依赖数据库等三方系统,以服务部署方式,稳定性更高,生成ID的性能也是非常高的;
可以根据自身业务特性来分配bit位,非常灵活。
缺点:
太依赖集群的时钟,如果机器时钟回拨了,可能会导致重复或者服务处于不可用。
结束语
大家好,我是凯哥Java(kaigejava),乐于分享技术文章,欢迎大家关注“凯哥Java”,及时了解更多。让我们一起学Java。也欢迎大家有事没事就来和凯哥聊聊~~~
分库分表后全局唯一ID的四种生成策略对比的更多相关文章
- 分库分表后跨分片查询与Elastic Search
携程酒店订单Elastic Search实战:http://www.lvesu.com/blog/main/cms-610.html 为什么分库分表后不建议跨分片查询:https://www.jian ...
- 分库分表之后全局id怎么生成
数据库自增id: 这个就是说你的系统里每次得到一个id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个id.拿到这个id之后再往对应的分库分表里去写入. 这个方案的好 ...
- 分库分表之后全局id咋生成?
1.面试题 分库分表之后,id主键如何处理? 2.面试官心里分析 其实这是分库分表之后你必然要面对的一个问题,就是id咋生成?因为要是分成多个表之后,每个表都是从1开始累加,那肯定不对啊,需要一个全局 ...
- 分库分表数据库自增 id
分库分表之后,ID 主键如何处理? 面试题 分库分表之后,id 主键如何处理? 面试官心理分析 其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 ...
- 为什么MySQL分库分表后总存储大小变大了?
1.背景 在完成一个分表项目后,发现分表的数据迁移后,新库所需的存储容量远大于原本两张表的大小.在做了一番查询了解后,完成了优化. 回过头来,需要进一步了解下为什么会出现这样的情况. 与标题的问题的类 ...
- 游戏服务器生成全局唯一ID的几种方法
在服务器系统开发时,为了适应数据大并发的请求,我们往往需要对数据进行异步存储,特别是在做分布式系统时,这个时候就不能等待插入数据库返回了取自动id了,而是需要在插入数据库之前生成一个全局的唯一id,使 ...
- 分布式唯一ID的几种生成方案
前言 在互联网的业务系统中,涉及到各种各样的ID,如在支付系统中就会有支付ID.退款ID等.那一般生成ID都有哪些解决方案呢?特别是在复杂的分布式系统业务场景中,我们应该采用哪种适合自己的解决方案是十 ...
- mysql分库分表那些事
为什么使用分库分表? 如下内容,引用自 Sharding Sphere 的文档,写的很大气. <ShardingSphere > 概念 & 功能 > 数据分片> 传统的 ...
- 001---mysql分库分表
mysql分库分表 一.整体的切分方式 1.分库分表:即数据的切分就是通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)中,以达到分散单台设备负载的效果 2.数据的切分根 ...
- Mysql系列七:分库分表技术难题之分布式全局唯一id解决方案
一.前言 在前面的文章Mysql系列四:数据库分库分表基础理论中,已经说过分库分表需要应对的技术难题有如下几个: 1. 分布式全局唯一id 2. 分片规则和策略 3. 跨分片技术问题 4. 跨分片事物 ...
随机推荐
- 使用EF 连接 数据库 SQLserver、MySql 实现 CodeFirst
1.新建项目,下载Nuget安装包 创建项目需要注意几点,如果是基于 .net framework 的项目 需要选择 相应版本的 EF, 如果是跨平台则选择EF Core版本. 我这里选择的是 .ne ...
- Windows服务器安全检查
为降低windows服务器系统的脆弱性,除了补丁及时更新,还建议加强系统账号的管理. 1.精简系统登录账号,最小化登录权限 检查方法:开始->运行->compmgmt.msc(计算机管理) ...
- Spring之拦截器和过滤器
Spring拦截器 拦截器简介 Spring拦截器是一种基于AOP的技术,本质也是使用一种代理技术,它主要作用于接口请求中的控制器,也就是Controller. 因此它可以用于对接口进行权限验证控制. ...
- Pyechart绘图基础
1.绘制散点图 from pyecharts.charts import Scatter import pyecharts.options as opts import numpy as np x = ...
- 基于Java+SpringBoot+Vue宠物咖啡馆平台设计和实现
\n文末获取源码联系 感兴趣的可以先收藏起来,大家在毕设选题,项目以及论文编写等相关问题都可以给我加好友咨询 系统介绍: 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成 ...
- [oeasy]python0024_ 输出时间_time_模块_module_函数_function
输出时间 回忆上次内容 print函数 有个默认的 end参数 end参数 的值可以是任意字符串 end参数 的值会输出到结尾位置 end参数 的默认值是 ...
- 为什么StampedLock会导致CPU100%?
StampedLock 是 Java 8 引入的一种高级的锁机制,它位于 java.util.concurrent.locks 包中.与传统的读写锁(ReentrantReadWriteLock)相比 ...
- GitHub Star 数量前 12 的开源无代码工具
相关文章:GitHub Star 数量前 15 的开源低代码项目 在本篇文章中,我们将探索 12 款在 GitHub 上星级排名前列的开源无代码工具. 每款工具都旨在简化和加速开发过程,但各自侧重于不 ...
- c#写一个WINFORM的多线程操作
以下是一个简单的示例,展示了如何在C# WinForms中创建一个按钮的异步事件,并使用Label控件来显示事件执行的时长. 首先,确保你已经在你的项目中添加了一个Button和一个Label控件.假 ...
- 《最新出炉》系列入门篇-Python+Playwright自动化测试-53- 处理面包屑(详细教程)
1.简介 面包屑(Breadcrumb),又称面包屑导航(BreadcrumbNavigation)这个概念来自童话故事"汉赛尔和格莱特",当汉赛尔和格莱特穿过森林时,不小心迷路了 ...